关于一致性Hash算法
在大型web应用中,缓存可算是当今的一个标准开发配置了。在大规模的缓存应用中,应运而生了分布式缓存系统。分布式缓存系统的基本原理,大家也有所耳闻。key-value如何均匀的分散到集群中?说到此,最常规的方式莫过于hash取模的方式。比如集群中可用机器适量为N,那么key值为K的的数据请求很简单的应该路由到hash(K) mod N对应的机器。的确,这种结构是简单的,也是实用的。但是在一些高速发展的web系统中,这样的解决方案仍有些缺陷。随着系统访问压力的增长,缓存系统不得不通过增加机器节点的方式提高集群的相应速度和数据承载量。增加机器意味着按照hash取模的方式,在增加机器节点的这一时刻,大量的缓存命不中,缓存数据需要重新建立,甚至是进行整体的缓存数据迁移,瞬间会给DB带来极高的系统负载,设置导致DB服务器宕机。 那么就没有办法解决hash取模的方式带来的诟病吗?看下文。
1. 一致性哈希(Consistent Hashing)
选择具体的机器节点不在只依赖需要缓存数据的key的hash本身了,而是机器节点本身也进行了hash运算。
(1) hash机器节点
首先求出机器节点的hash值(怎么算机器节点的hash?ip可以作为hash的参数吧。。当然还有其他的方法了),然后将其分布到0~2^32的一个圆环上(顺时针分布)。如下图所示:
集群中有机器:A , B, C, D, E五台机器,通过一定的hash算法我们将其分布到如上图所示的环上。
(2)访问方式
如果有一个写入缓存的请求,其中Key值为K,计算器hash值Hash(K),
Hash(K)
对应于图 – 1环中的某一个点,如果该点对应没有映射到具体的某一个机器节点,那么顺时针查找,直到第一次找到有映射机器的节点,该节点就是确定的目标节点,如果超过了2^32仍然找不到节点,则命中第一个机器节点。比如
Hash(K)
的值介于A~B之间,那么命中的机器节点应该是B节点(如上图 )。
(3)增加节点的处理
如上图 – 1,在原有集群的基础上欲增加一台机器F,增加过程如下:
计算机器节点的Hash值,将机器映射到环中的一个节点,如下图:
增加机器节点F之后,访问策略不改变,依然按照(2)中的方式访问,此时缓存命不中的情况依然不可避免,不能命中的数据是hash(K)在增加节点以前落在C~F之间的数据。尽管依然存在节点增加带来的命中问题,但是比较传统的 hash取模的方式,一致性hash已经将不命中的数据降到了最低。
Consistent Hashing最大限度地抑制了hash键的重新分布。另外要取得比较好的负载均衡的效果,往往在服务器数量比较少的时候需要增加虚拟节点来保证服务器能均匀的分布在圆环上。因为使用一般的hash方法,服务器的映射地点的分布非常不均匀。使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上。
下面有一个图描述了需要为每台物理服务器增加的虚拟节点。

x轴表示的是需要为每台物理服务器扩展的虚拟节点倍数(scale),y轴是实际物理服务器数,可以看出,当物理服务器的数量很小时,需要更大的虚拟节点,反之则需要更少的节点,从图上可以看出,在物理服务器有10台时,差不多需要为每台服务器增加100~200个虚拟节点才能达到真正的负载均衡。
2. 代码实现
http://www.iteye.com/topic/684087
3. 其他参考资料
补充
当服务器不多,并且不考虑扩容的时候,可直接使用简单的路由算法,用服务器数除缓存数据KEY的hash值,余数作为服务器下标即可。
但是当业务发展,网站缓存服务需要扩容时就会出现问题,比如3台缓存服务器要扩容到4台,就会导致75%的数据无法命中,当100台服务器中增加一台,不命中率会到达99%(n/(n+1)),这显然是不能接受的。
在设计分布式缓存集群的时候,需要考虑集群的伸缩性,也就是当向集群中增加服务器的时候,要尽量减小对集群的影响,而一致性hash算法就是用来解决集群伸缩性。
一致性hash算法通过构造一个长度为2^32的整数环,根据节点名的hash值将缓存服务器节点放置在这个环上,然后计算要缓存的数据的key的hash值,顺时针找到最近的服务器节点,将数据放到该服务器上。
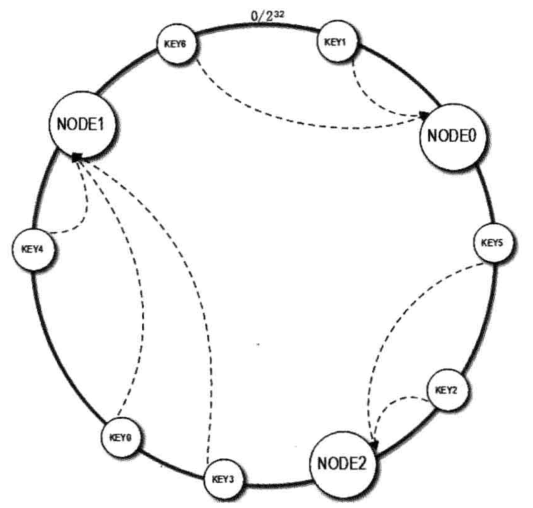
有Node0,Node1,Node2三个节点,假设Node0的hash值是1024,key1的hash值是500,key1在环上顺时针查找,最近的节点就是Node0。
当服务器集群又开始扩容,新增了Node3节点,从三个节点扩容到了四个节点。
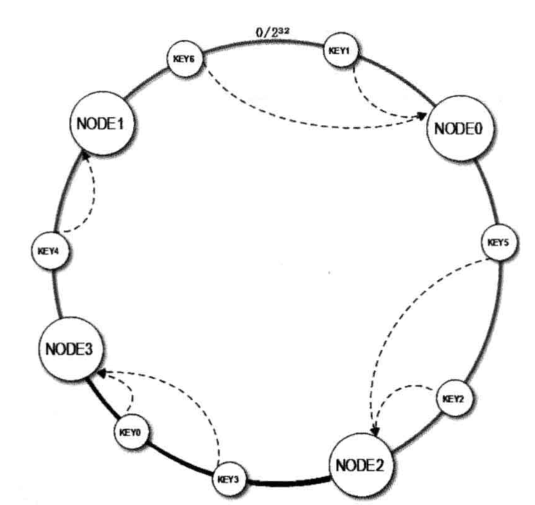
Node3加到了Node2和Node1之间,除了Node2到Node3之间原本是Node1的数据无法再命中,其它的数据不受影响,3台扩容到4台可命中率高达75%,
而且集群越大,影响越小,100台服务器增加一台,命中率可达到99%。
查找不小于查找树的最小值是用的二叉查找树实现的。
但是这样子还是会存在一个问题,就是负载不均衡的问题,当Node3加到Node2和Node1之间时,原本会访问Node1的缓存数据有50%的概率会缓存到Node3上了,这样Node0和Node2的负载会是Node1和Node3的两倍。
要解决一致性hash算法带来的负载不均衡问题,可通过将每台物理服务器虚拟成一组虚拟缓存服务器,将虚拟服务器的hash值放置在hash环上,KEY在环上先找到虚拟服务器节点,然后再映射到实际的服务器上。

这样在Node0,1,2虚拟节点都已存在的情况下,将Node3的多个虚拟节点分散到它们中间,多个虚拟的Node3节点会影响到其它的多个虚拟节点,而不是只影响其中一个,这样将命中率不会有变化,但是负载却更加均衡了而且虚拟节点越多越均衡。
关于一致性Hash算法的更多相关文章
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一致性hash算法详解
转载请说明出处:http://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT) ...
- 一致性hash算法简介
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简单哈希 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 一致性 hash 算法( consistent hashing )a
一致性 hash 算法( consistent hashing ) 张亮 consistent hashing 算法早在 1997 年就在论文 Consistent hashing and rando ...
- 一致性hash算法简介与代码实现
一.简介: 一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义: 1.平衡性(Balance) 2.单调性(Monotonicity) 3.分散性(Spread) 4.负 ...
- memcache的一致性hash算法使用
一.概述 1.我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同,只是对我们要存储数据的k ...
- 一致性Hash算法在Redis分布式中的使用
由于redis是单点,但是项目中不可避免的会使用多台Redis缓存服务器,那么怎么把缓存的Key均匀的映射到多台Redis服务器上,且随着缓存服务器的增加或减少时做到最小化的减少缓存Key的命中率呢? ...
- 【转载】一致性hash算法释义
http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html 一致性Hash算法背景 一致性哈希算法在1997年由麻省理工学院的Karge ...
- 一致性Hash算法在Memcached中的应用
前言 大家应该都知道Memcached要想实现分布式只能在客户端来完成,目前比较流行的是通过一致性hash算法来实现.常规的方法是将server的hash值与server的总台数进行求余,即hash% ...
随机推荐
- 【LeetCode】56. Merge Intervals
Merge Intervals Given a collection of intervals, merge all overlapping intervals. For example,Given ...
- 【LeetCode】35. Search Insert Position (2 solutions)
Search Insert Position Given a sorted array and a target value, return the index if the target is fo ...
- 配置tomcat全局c3p0连接池
由于项目中多个应用访问同一个数据库,并部署在同一个tomcat下面,所以没必要每个应用都配置连接池信息,这样可能导致数据库的资源分布不均,所以这种情况完全可以配置一个tomcat的全局连接池,所涉及应 ...
- Python学习笔记010——匿名函数lambda
1 语法 my_lambda = lambda arg1, arg2 : arg1 + arg2 + 1 arg1.arg2:参数 arg1 + arg2 + 1 :表达式 2 描述 匿名函数不需要r ...
- AP_创建标准发票后会计科目的变化(概念)
2014-06-04 Created By BaoXinjian 1. 创建Invoice,并查看所创建的科目
- 字符串 - KMP模式匹配
在朴素的模式匹配算法中,主串的pos值(i)是不断地回溯来完成的(见字符串的基本操作中的Index函数).而计算机的大仙们发现这种回溯其实可以是不需要的.既然i值不回溯,也就是不可以变小,那么考虑的变 ...
- CView类的使用
首先我们来写一个样例: 1.建一个win32简单应用程序,不要觉得这样就不能写出MFC程序,由于是不是MFC程序取决于调没调MFC函数. 2. 删除入口函数.仅仅留下#include "st ...
- t:formvalid中定义callback函数
如果dialog="true"的话 callback="@Override functionName" 调用的是当前页面的方法 call ...
- 有限狀態機FSM coding style整理 (SOC) (Verilog)
AbstractFSM在數位電路中非常重要,藉由FSM,可以讓數位電路也能循序地執行起演算法.本文將詳細討論各種FSM coding style的優缺點,並歸納出推薦的coding style. In ...
- [svc]运维知识体系及职业
知识点: 1,运维命令基础 100个命令 三剑客 正则 2,运维基础知识 linux启动 目录结构 常见配置路径 文件属性 链接知识 权限 用户管理 磁盘管理 网络基础(配置ip路由等) 3,基础核心 ...