Python爬虫框架Scrapy实例(二)
目标任务:使用Scrapy框架爬取新浪网导航页所有大类、小类、小类里的子链接、以及子链接页面的新闻内容,最后保存到本地。
大类小类如下图所示:
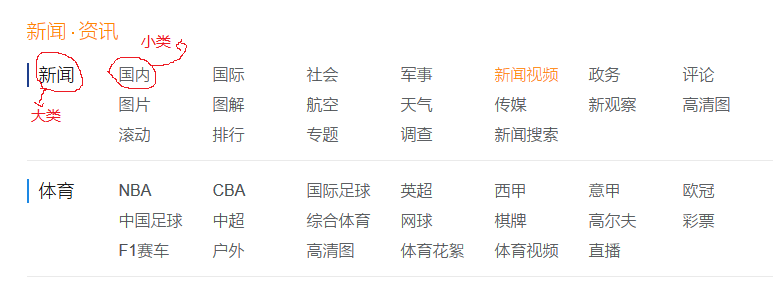
点击国内这个小类,进入页面后效果如下图(部分截图):

查看页面元素,得到小类里的子链接如下图所示:

有子链接就可以发送请求来访问对应新闻的内容了。
首先创建scrapy项目
# 创建项目
scrapy startproject sinaNews
# 创建爬虫
scrapy genspider sina "sina.com.cn"
一、根据要爬取的字段创建item文件:
# -*- coding: utf-8 -*- import scrapy
import sys
reload(sys)
sys.setdefaultencoding("utf-8") class SinanewsItem(scrapy.Item):
# 大类的标题和url
parentTitle = scrapy.Field()
parentUrls = scrapy.Field() # 小类的标题和子url
subTitle = scrapy.Field()
subUrls = scrapy.Field() # 小类目录存储路径
subFilename = scrapy.Field() # 小类下的子链接
sonUrls = scrapy.Field() # 文章标题和内容
head = scrapy.Field()
content = scrapy.Field()
二、编写spiders爬虫文件
# -*- coding: utf-8 -*- import scrapy
import os
from sinaNews.items import SinanewsItem
import sys
reload(sys)
sys.setdefaultencoding("utf-8") class SinaSpider(scrapy.Spider):
name = "sina"
allowed_domains = ["sina.com.cn"]
start_urls = ['http://news.sina.com.cn/guide/'] def parse(self, response):
items= []
# 所有大类的url 和 标题
parentUrls = response.xpath('//div[@id="tab01"]/div/h3/a/@href').extract()
parentTitle = response.xpath('//div[@id="tab01"]/div/h3/a/text()').extract() # 所有小类的ur 和 标题
subUrls = response.xpath('//div[@id="tab01"]/div/ul/li/a/@href').extract()
subTitle = response.xpath('//div[@id="tab01"]/div/ul/li/a/text()').extract() #爬取所有大类
for i in range(0, len(parentTitle)):
# 指定大类目录的路径和目录名
parentFilename = "./Data/" + parentTitle[i] #如果目录不存在,则创建目录
if(not os.path.exists(parentFilename)):
os.makedirs(parentFilename) # 爬取所有小类
for j in range(0, len(subUrls)):
item = SinanewsItem() # 保存大类的title和urls
item['parentTitle'] = parentTitle[i]
item['parentUrls'] = parentUrls[i] # 检查小类的url是否以同类别大类url开头,如果是返回True (sports.sina.com.cn 和 sports.sina.com.cn/nba)
if_belong = subUrls[j].startswith(item['parentUrls']) # 如果属于本大类,将存储目录放在本大类目录下
if(if_belong):
subFilename =parentFilename + '/'+ subTitle[j]
# 如果目录不存在,则创建目录
if(not os.path.exists(subFilename)):
os.makedirs(subFilename) # 存储 小类url、title和filename字段数据
item['subUrls'] = subUrls[j]
item['subTitle'] =subTitle[j]
item['subFilename'] = subFilename items.append(item) #发送每个小类url的Request请求,得到Response连同包含meta数据 一同交给回调函数 second_parse 方法处理
for item in items:
yield scrapy.Request( url = item['subUrls'], meta={'meta_1': item}, callback=self.second_parse) #对于返回的小类的url,再进行递归请求
def second_parse(self, response):
# 提取每次Response的meta数据
meta_1= response.meta['meta_1'] # 取出小类里所有子链接
sonUrls = response.xpath('//a/@href').extract() items= []
for i in range(0, len(sonUrls)):
# 检查每个链接是否以大类url开头、以.shtml结尾,如果是返回True
if_belong = sonUrls[i].endswith('.shtml') and sonUrls[i].startswith(meta_1['parentUrls']) # 如果属于本大类,获取字段值放在同一个item下便于传输
if(if_belong):
item = SinanewsItem()
item['parentTitle'] =meta_1['parentTitle']
item['parentUrls'] =meta_1['parentUrls']
item['subUrls'] = meta_1['subUrls']
item['subTitle'] = meta_1['subTitle']
item['subFilename'] = meta_1['subFilename']
item['sonUrls'] = sonUrls[i]
items.append(item) #发送每个小类下子链接url的Request请求,得到Response后连同包含meta数据 一同交给回调函数 detail_parse 方法处理
for item in items:
yield scrapy.Request(url=item['sonUrls'], meta={'meta_2':item}, callback = self.detail_parse) # 数据解析方法,获取文章标题和内容
def detail_parse(self, response):
item = response.meta['meta_2']
content = ""
head = response.xpath('//h1[@id="main_title"]/text()')
content_list = response.xpath('//div[@id="artibody"]/p/text()').extract() # 将p标签里的文本内容合并到一起
for content_one in content_list:
content += content_one item['head']= head
item['content']= content yield item
三、编写pipelines文件
# -*- coding: utf-8 -*- from scrapy import signals
import sys
reload(sys)
sys.setdefaultencoding("utf-8") class SinanewsPipeline(object):
def process_item(self, item, spider):
sonUrls = item['sonUrls'] # 文件名为子链接url中间部分,并将 / 替换为 _,保存为 .txt格式
filename = sonUrls[7:-6].replace('/','_')
filename += ".txt" fp = open(item['subFilename']+'/'+filename, 'w')
fp.write(item['content'])
fp.close() return item
四、settings文件的设置
# 设置管道文件
ITEM_PIPELINES = {
'sinaNews.pipelines.SinanewsPipeline': 300,
}
执行命令
scrapy crwal sina
效果如下图所示:
打开工作目录下的Data目录,显示大类文件夹
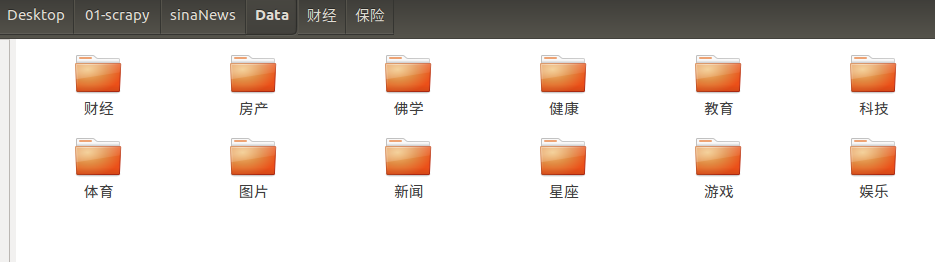
大开一个大类文件夹,显示小类文件夹:

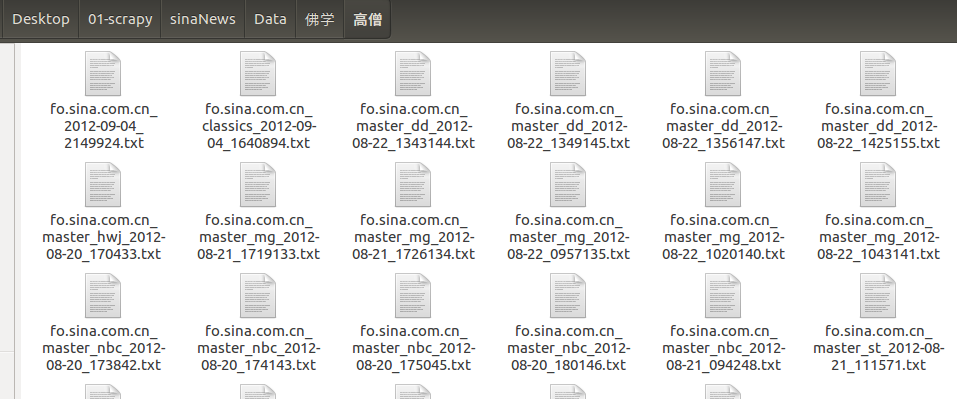
打开一个小类文件夹,显示文章:
Python爬虫框架Scrapy实例(二)的更多相关文章
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- Python爬虫框架Scrapy实例(一)
目标任务:爬取腾讯社招信息,需要爬取的内容为:职位名称,职位的详情链接,职位类别,招聘人数,工作地点,发布时间. 一.创建Scrapy项目 scrapy startproject Tencent 命令 ...
- python爬虫框架scrapy初试(二)
将该导航网站搜索出结果的页面http://www.dmoz.org/Computers/Programming/Languages/Python/Books/里面标题,及标题的超链接和描述爬下来. 使 ...
- python爬虫框架scrapy实例详解
生成项目scrapy提供一个工具来生成项目,生成的项目中预置了一些文件,用户需要在这些文件中添加自己的代码.打开命令行,执行:scrapy st... 生成项目 scrapy提供一个工具来生成项目,生 ...
- Python爬虫框架Scrapy实例(四)下载中间件设置
还是豆瓣top250爬虫的例子,添加下载中间件,主要是设置动态Uesr-Agent和代理IP Scrapy代理IP.Uesr-Agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控 ...
- python爬虫框架scrapy初试(二点一)
功能:爬取某网站部分新闻列表和对应的详细内容. 列表页面http://www.zaobao.com/special/report/politic/fincrisis 实现代码: import scra ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Linux 安装python爬虫框架 scrapy
Linux 安装python爬虫框架 scrapy http://scrapy.org/ Scrapy是python最好用的一个爬虫框架.要求: python2.7.x. 1. Ubuntu14.04 ...
随机推荐
- electron-searchMovies
之前学了electron,前段时间又学了一下vue,为了增加熟练度决定将两者结合做个有趣的东西.想来想去最后决定将原来用 PyQt 写的MovieHeavens重新写一遍,使用electron-vue ...
- Eclipse的调试功能的10个小窍门
你可能已经看过一些类似“关于调试的N件事”的文章了.但我想我每天大概在调试上会花掉1个小时,这是非常多的时间了.所以非常值得我们来了解一些用得到的功能,可以帮我们节约很多时间.所以在这个主题上值得我再 ...
- 告诉你html5比普通html多了哪些东西?
- 如何将ppt转换为高清图片?
PPT2010版本直接提供了“另存为”图片的功能,但另存为后的图片清晰度不够,这是因为office提供的默认点每英寸点数 (dpi)为96dpi,也就是说图片的尺寸为960x720像素,通过注册表可以 ...
- linux,crontab定时任务中为脚本指定使用参数,crontab的脚本中是否可以带参数
需求描述: 今天在写脚本的时候,脚本的运行需要给出几个参数,那么就考虑 在crontab写定时任务的时候,是否也是能够在脚本中,增加参数呢, 因为以前没有这么用过,所以呢,就进行一次测试. 测试过程: ...
- Leetcode: mimimum depth of tree, path sum, path sum II
思路: 简单搜索 总结: dfs 框架 1. 需要打印路径. 在 dfs 函数中假如 vector 变量, 不用 & 修饰的话就不需要 undo 2. 不需要打印路径, 可设置全局变量 ans ...
- VC++第三方库配置-OpenSpirit 4.2.0 二次开发
在VS中右击项目,点击属性 1.配置属性--常规--输出目录:Windows\VS2010\debug\ 2.配置属性--常规--中间目录:Windows\VS2010\debug\ 3.配置属性-- ...
- CH7-WEB开发(集成在一起)
- php学习十二:其他魔术方法
__clone():克隆的时候会调用__clone方法: __cal:当类里面没有方法的时候会调用__call方法: __toString:当echo的时候会调用__toString方法: __aut ...
- iOS性能调优系列(全)
总结: 三类工具 基础工具 (NSLog的方式记录运行时间.) 性能工具.检测各个部分的性能表现,找出性能瓶颈 内存工具.检查内存正确性和内存使用效率 性能工具: 可以衡量CPU的使用,时间的消耗,电 ...