【RL系列】SARSA算法的基本结构
SARSA算法严格上来说,是TD(0)关于状态动作函数估计的on-policy形式,所以其基本架构与TD的$v_{\pi}$估计算法(on-policy)并无太大区别,所以这里就不再单独阐述之。本文主要通过两个简单例子来实际应用SARSA算法,并在过程中熟练并总结SARSA算法的流程与基本结构。
强化学习中的统计方法(包括Monte Carlo,TD)在实现episode task时,无不例外存在着两层最基本的循环结构。如果我们将每一个episode task看作是一局游戏,那么这个游戏有开始也有结束,统计方法是就是一局接着一局不停的在玩,然后从中总结出最优策略。Monte Carlo与TD的区别在于,Monte Carlo是玩完一局,总结一次,而TD算法是边玩边总结。所以这两层基本结构的外层是以游戏次数为循环,内层则是以游戏过程为循环。
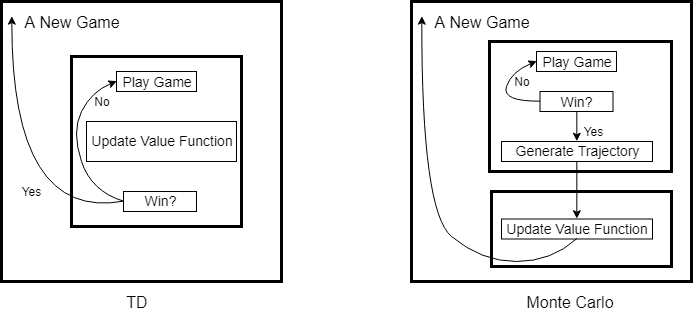
SARSA作为TD算法下的on-policy control算法,只需边进行游戏边更新动作值函数和Policy即可,所以SARSA算法的内层可以由TD算法细化为如下结构:

NumOfGames = 500
while(index < NumOfGames)
[Q, Policy] = PlayGame(Q, Policy);
end function [Q, Policy] = PlayGame(Q, Policy)
while(1)
% Begin Game
while(1)
Action = ChooseAction(Policy(State));
NextState = State + Action + windy(State);
try
Grid(NextState) % Check for exception
catch
break;
end
NextAction = ChooseAction(Policy(NextState));
Q(State, Action) = Q(State, Action) + alpha*(R + gamma*Q(NextState, NextAction)...
- Q(State, Action));
Policy = UpdatePolicy(Policy);
State = NextState;
if(State == Target)
return;
end
end
end
【RL系列】SARSA算法的基本结构的更多相关文章
- 【RL系列】马尔可夫决策过程——状态价值评价与动作价值评价
请先阅读上两篇文章: [RL系列]马尔可夫决策过程中状态价值函数的一般形式 [RL系列]马尔可夫决策过程与动态编程 状态价值函数,顾名思义,就是用于状态价值评价(SVE)的.典型的问题有“格子世界(G ...
- 【RL系列】从蒙特卡罗方法步入真正的强化学习
蒙特卡罗方法给我的感觉是和Reinforcement Learning: An Introduction的第二章中Bandit问题的解法比较相似,两者皆是通过大量的实验然后估计每个状态动作的平均收益. ...
- 【RL系列】Multi-Armed Bandit笔记——UCB策略与Gradient策略
本篇主要是为了记录UCB策略与Gradient策略在解决Multi-Armed Bandit问题时的实现方法,涉及理论部分较少,所以请先阅读Reinforcement Learning: An Int ...
- 【RL系列】Multi-Armed Bandit笔记补充(一)
在此之前,请先阅读上一篇文章:[RL系列]Multi-Armed Bandit笔记 本篇的主题就如标题所示,只是上一篇文章的补充,主要关注两道来自于Reinforcement Learning: An ...
- openssl之EVP系列之7---信息摘要算法结构概述
openssl之EVP系列之7---信息摘要算法结构概述 ---依据openssl doc/crypto/EVP_DigestInit.pod翻译和自己的理解写成 (作者:Dragon ...
- CRL快速开发框架系列教程十(导出对象结构)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- 【RL系列】马尔可夫决策过程中状态价值函数的一般形式
请先阅读上一篇文章:[RL系列]马尔可夫决策过程与动态编程 在上一篇文章里,主要讨论了马尔可夫决策过程模型的来源和基本思想,并以MAB问题为例简单的介绍了动态编程的基本方法.虽然上一篇文章中的马尔可夫 ...
- 【RL系列】On-Policy与Off-Policy
强化学习大致上可分为两类,一类是Markov Decision Learning,另一类是与之相对的Model Free Learning 分为这两类是站在问题描述的角度上考虑的.同样在解决方案上存在 ...
- 增强学习--Sarsa算法
Sarsa算法 实例代码 import numpy as np import random from collections import defaultdict from environment i ...
随机推荐
- 用jQuery编写简单九宫格抽奖
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- K3CLOUD开发-动态表单树形单据体实现银行交易对账
背景:系统手机开单生成销售单据,通过银行pos机收款,系统收款流水与银行流水可能存在差异,所以通过获取银行接口,获取消费信息自动插入到生产系统数据库,开发对账报表,实现差异汇总! 展示效果如下: 开发 ...
- linux学习笔记一:远程连接linux服务器
环境介绍:win7电脑,通过VM虚拟出linux系统,安装centOS7 通过Xshell连接linux,ftp访问服务器资源. 遇到的问题,ftp连不上linux 解决:linux上安装ftp服务 ...
- linux 命令 uniq
linux命令uniq去重 实例详细说明linux下去除重复行命令uniq 一,uniq干什么用的 文本中的重复行,基本上不是我们所要的,所以就要去除掉.linux下有其他命令可以去除重复行,但是我觉 ...
- 搭建最小linux系统
Busybox简介 • 制作文件系统我们需要使用到Busybox 工具 – 版本为busybox-1.21.1.tar.bz2 – 开源网址是http://www.busybox.net/ – Bus ...
- docker环境下构建flannel 网络
flannel 是coreos 开发的网络解决方案,为每一台主机分配一个 subnet,容器从此subnet 中分配ip,ip可以在主机间路由.每个subnet从更大的ip池中划分,为了在各个主机间共 ...
- IP组播 MulticastChannel接口 DatagramChannel实现
监听者 import java.io.IOException; import java.net.InetAddress; import java.net.InetSocketAddress; impo ...
- Go 学习之路:Println 与 Printf 的区别
Println 和Printf 都是fmt包中公共方法:在需要打印信息时常用的函数,那么二函数有什么区别呢? 附上代码 package main import ("time"&qu ...
- 一个sqoop export案例中踩到的坑
案例分析: 需要将hdfs上的数据导出到mysql里的一张表里. 虚拟机集群的为:centos1-centos5 问题1: 在centos1上将hdfs上的数据导出到centos1上的mysql里: ...
- R语言-正则表达式1
R语言的正则表达式主要用来处理文本资料,比如进行查找.替换等等. 首先是一些处理文本时会用到的函数: 字符串分割:strsplit() 字符串连接:paste(),paste0() 计算字符串长度:n ...