结对作业_Two
Part 1.前言
(附:本次编码涵盖的所有功能均为java语言实现)
Part 2.具体分工
本次的结对作业我们简单的拆分成:
- 爬虫部分(高裕祥负责)
- 词频分析部分(柯奇豪负责)
- 附加题部分(柯奇豪负责处理数据、高裕祥负责处理爬取相关内容)
- 单元测试(柯奇豪负责)
Part 3.PSP表
| PSP3.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | --- | --- |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 90 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 240 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 10 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| · Design | · 具体设计 | 120 | 140 |
| · Coding | · 具体编码 | 1800 | 2200 |
| · Code Review | · 代码复审 | 30 | 100 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 10 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 2250 | 3030 |
Part 4.解题思路描述与设计实现说明
1. 爬虫使用
- 使用语言:java
- 本次的爬虫我们主要利用Java爬虫工具Jsoup解析进行爬取,基本上爬虫的流程可以归纳如下:
2. 代码组织与内部实现设计(类图)
我自己在本地是建了三个java项目分别负责不同的功能模块:
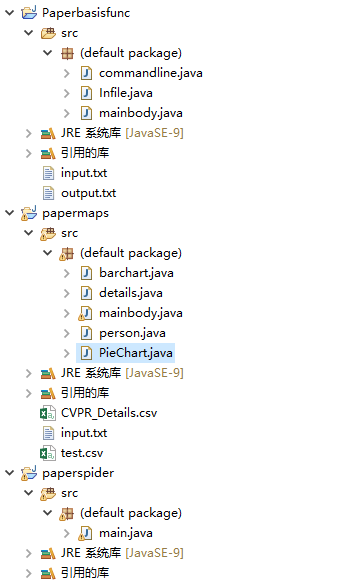
- PaperBasicFuction (处理基础的词频统计功能)
- commandline.java (实现命令行处理功能)
- infile。java (实现基础词频分析功能)
- mainbody.java (构成WordCount的主体main)
- PaperMaps (处理附加的图形化显示功能)
- barchart.java (负责柱状图的生成)
- Piechart.java (负责饼图的功能)
- details.java (javabean模块进行数据处理)
- person.java (论文作者相关性数据处理)
- mainbody.java (构成AdditionalFunction主体main)
- PaperSpider (负责爬虫功能的实现)
3. 说明算法的关键与关键实现部分流程图(含关键代码的解释)

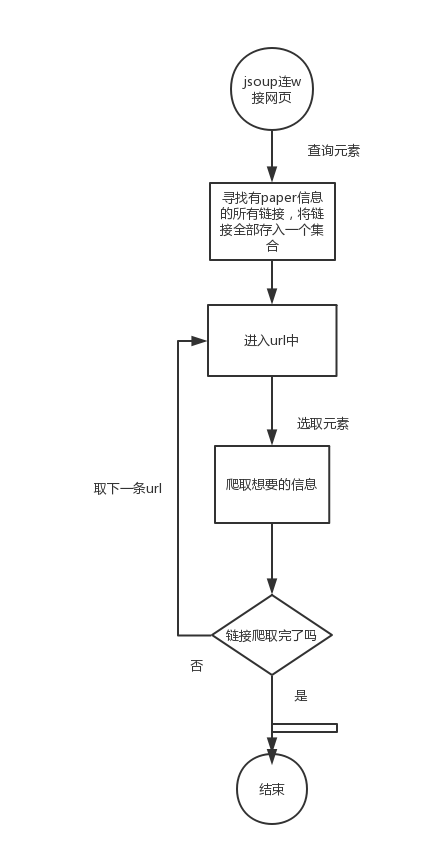
接下来我就简单的介绍一下我这次新补充或者改进优化的几处地方,与上回个人作业相关功能类似的地方在这里我就不再赘述
section 1.命令行功能的实现
options.addOption("h", "help", false,"Helps About this Command");
options.addOption("i", "input", true, "Input this file");
options.addOption("o", "output", true, "Output this file");
options.addOption("w", "weight", true, "Weight of the word");
options.addOption("m", "members", true, "Members of count words");
options.addOption("n", "number", true, "Numbers of output words");
try {
CommandLine commandline = parser.parse(options, args);
if(commandline.hasOption("h")) {
HelpFormatter formatter = new HelpFormatter();
formatter.printHelp("CommandLineParameters",options);
}
if(commandline.hasOption("i")) {
infile = commandline.getOptionValue("i");
}
if(commandline.hasOption("o")) {
outfile = commandline.getOptionValue("o");
}
if(commandline.hasOption("w")) {
weight = commandline.getOptionValue("w");
}
if(commandline.hasOption("o")) {
member = commandline.getOptionValue("m");
}
if(commandline.hasOption("o")) {
number = commandline.getOptionValue("n");
}
} catch (ParseException e) {
e.printStackTrace();
}
原先我的思路是使用命令行读入转String然后用if或者switch-case来逐一的判断匹配,显然这种方式有些许繁琐,为了方便使用命令行的处理,我转而借助于commons-cli来简化工作,显然操作起来就变得简单明了,方便我获取命令行参数
section 2.小细节的优化
关于标题和内容权重不同的情况,我简单的通过两句表达式做处理,不做多余的判断处理
w_title = w*10+(w-1)*(-1); w_content = 1;
依照于题目的要求,文本的格式相对的统一,所以我采用逐行获取后匹配,对应的进行相关操作
while((strline = buffReader.readLine())!=null){
Matcher t_mat = t_pat.matcher(strline);
Matcher c_mat = c_pat.matcher(strline);
if(t_mat.find()) {
t_str=t_mat.group(1).toLowerCase();
t_words.append(t_str).append(" ");
phrase(t_str,w_title,m);
characters += t_str.length()+1;
lines++;
}
if(c_mat.find()) {
c_str=c_mat.group(1).toLowerCase();
c_words.append(c_str).append(" ");
phrase(c_str,w_content,m);
characters += c_str.length();
lines++;
}
}
buffReader.close();
section 3.网页爬虫
for(Element paper:urlLink) { //循环爬取url队列
String URL = paper.attr("href");
if(!URL.contains("https://")){
URL = "openaccess.thecvf.com/"+URL;
}
Document doc = Jsoup.connect("http://"+URL).timeout(80000).maxBodySize(0).get();
Elements paperdatas=doc.select("#content");
Elements title1=paperdatas.select("#papertitle");
Elements abs=paperdatas.select("#abstract");
Elements authors = paperdatas.select("#authors");
Elements opway = paperdatas.select("a[href]");
String author=authors.select("b").text();
String title = title1.text();
paperid=paperid+1;
String abst=abs.text();
String openway=opway.text();
System.out.println("ID: "+paperid);
System.out.println("title:"+ title );
System.out.println("link: "+ URL);
System.out.println("abstract: " +abst);
System.out.println("authors: "+ author);
System.out.println("relate: "+ openway);
System.out.println("relate link: ");
for(Element linklink:opway) {
String oplink = linklink.attr("href");
System.out.println( "http://openaccess.thecvf.com/" + oplink);
}
}
section 4.命令行处异常处理,输出err信息并进入中断
if (commandline.getOptions().length > 0) {
...
if(commandline.hasOption("m")) {
member = commandline.getOptionValue("m");
if(Integer.parseInt(member)<2 | Integer.parseInt(member)>10) {
System.err.println("ERROR_MESSAGE:THE PHRASE LENGTH OUT OF BOUNDS (2<=m<=10)"); //词组包含合法单词数的限制
System.exit(1);
}
}
...
if(commandline.hasOption("n")) {
number = commandline.getOptionValue("n");
if(Integer.parseInt(number)>100|Integer.parseInt(number)<0) {
System.err.println("ERROR_MESSAGE:THE OUTPUT PHRASE LENGTH OUT OF BOUNDS (0<=n<=100)"); //输出top榜的个数限制
System.exit(1);
}
}
...
}
else {
System.err.println("ERROR_MESSAGE:NO ARGS"); //命令行参数的约束
System.exit(1);
}
Part 5.附加题设计与展示
section 1.详情整合生成具体查询目录.csv并存储于新构建的class details中
因为官网上可以获取的相关信息有限,能够直接爬取下来的信息如下图所示
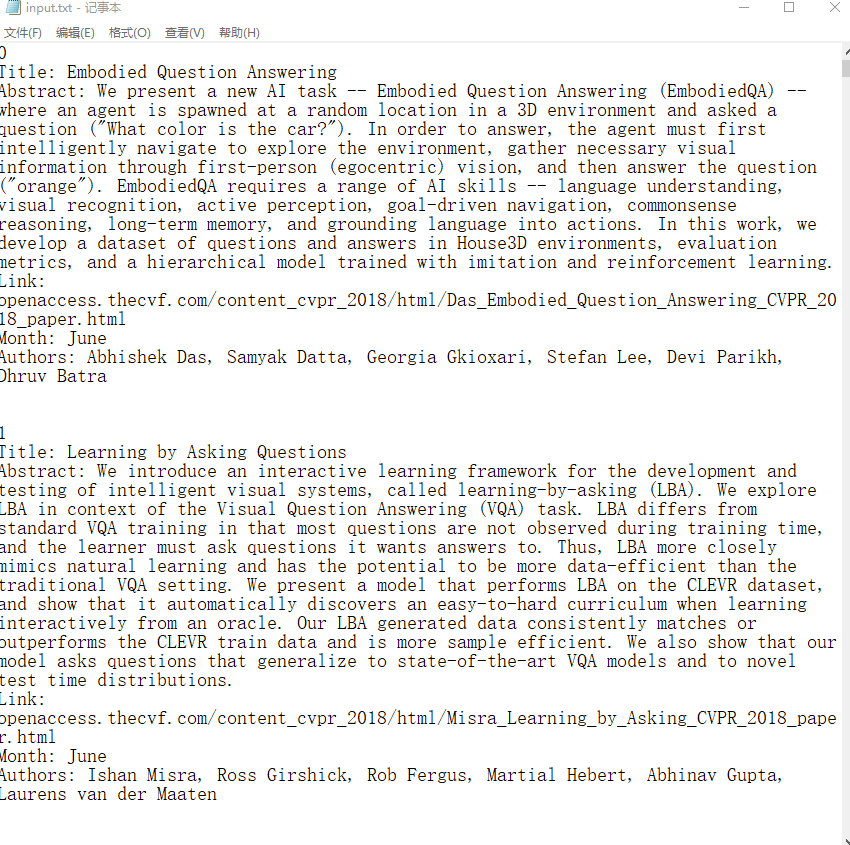
所以不够我们对其更详细信息的参考,故通过爬取所获得信息,我们将其进行整合成一份CVPR_Details.csv详细目录,截图展示如下

而这些信息我们将其存放于新构建的class details中,方便我们后续对其进行操作处理
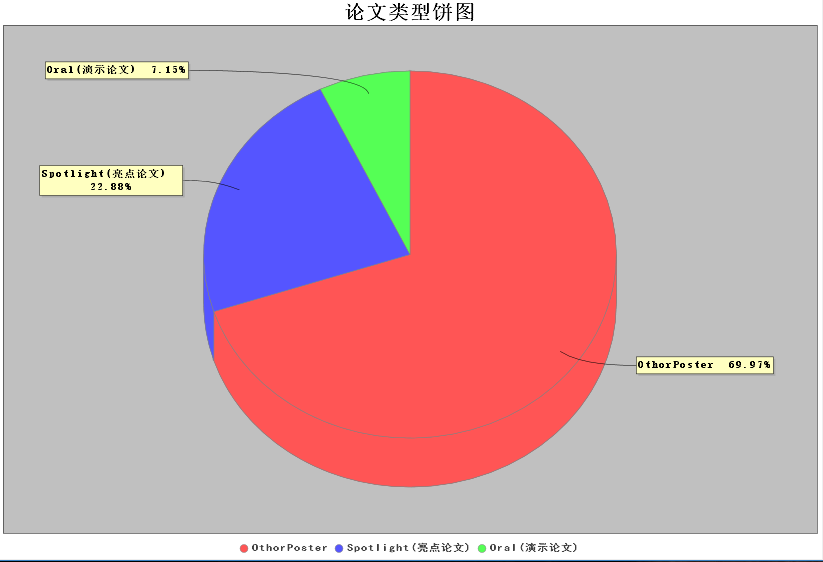
section 2.论文类型的饼图构建
public PieChart(){
DefaultPieDataset data = getDataSet();
JFreeChart chart = ChartFactory.createPieChart3D("论文类型饼图",data,true,false,false); //设置百分比
PiePlot pieplot = (PiePlot) chart.getPlot();
DecimalFormat df = new DecimalFormat("0.00%");//获得一个DecimalFormat对象,主要是设置小数问题
NumberFormat nf = NumberFormat.getNumberInstance();//获得一个NumberFormat对象
StandardPieSectionLabelGenerator sp1 = new StandardPieSectionLabelGenerator("{0} {2}", nf, df);//获得StandardPieSectionLabelGenerator对象
pieplot.setLabelGenerator(sp1);//设置饼图显示百分比 //没有数据的时候显示的内容
pieplot.setNoDataMessage("无数据显示");
pieplot.setCircular(false);
pieplot.setLabelGap(0.02D);
pieplot.setIgnoreNullValues(true);//设置不显示空值
pieplot.setIgnoreZeroValues(true);//设置不显示负值
frame1=new ChartPanel (chart,true);
chart.getTitle().setFont(new Font("宋体",Font.BOLD,20));//设置标题字体
PiePlot piePlot= (PiePlot) chart.getPlot();//获取图表区域对象
piePlot.setLabelFont(new Font("宋体",Font.BOLD,10));//解决乱码
chart.getLegend().setItemFont(new Font("黑体",Font.BOLD,10));
}
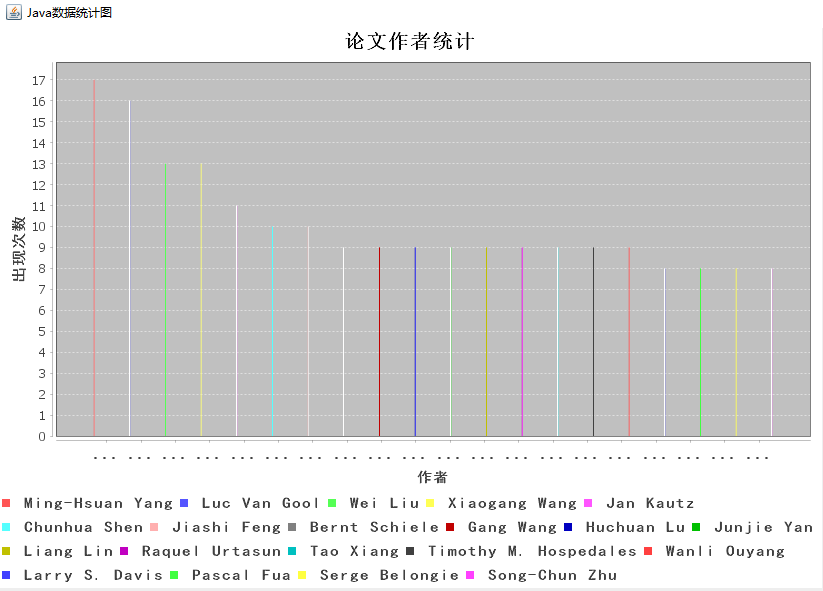
section 3.top作者论文参篇幅与top词频的直方图
public barchart() {
CategoryDataset dataset = getDataSet();
JFreeChart chart = ChartFactory.createBarChart("论文作者统计", "作者","出现次数",dataset,PlotOrientation.VERTICAL,true,false,false);
CategoryPlot plot = chart.getCategoryPlot();
CategoryAxis domainAxis = plot.getDomainAxis();
domainAxis.setLabelFont(new Font("黑体",Font.BOLD,14));
domainAxis.setTickLabelFont(new Font("宋体",Font.BOLD,14));
ValueAxis rangeAxis=plot.getRangeAxis();
rangeAxis.setLabelFont(new Font("黑体",Font.BOLD,15));
chart.getLegend().setItemFont(new Font("黑体", Font.BOLD, 15));
chart.getTitle().setFont(new Font("宋体",Font.BOLD,20));
frame = new ChartPanel(chart,true);
}
public CategoryDataset getDataSet() {
DefaultCategoryDataset dataset = new DefaultCategoryDataset();
// System.out.println(topList.size());
for(int i=0;i<20;i++){
dataset.addValue(topList.get(i).getValue(), topList.get(i).getKey(), topList.get(i).getKey());
}
return dataset;
}
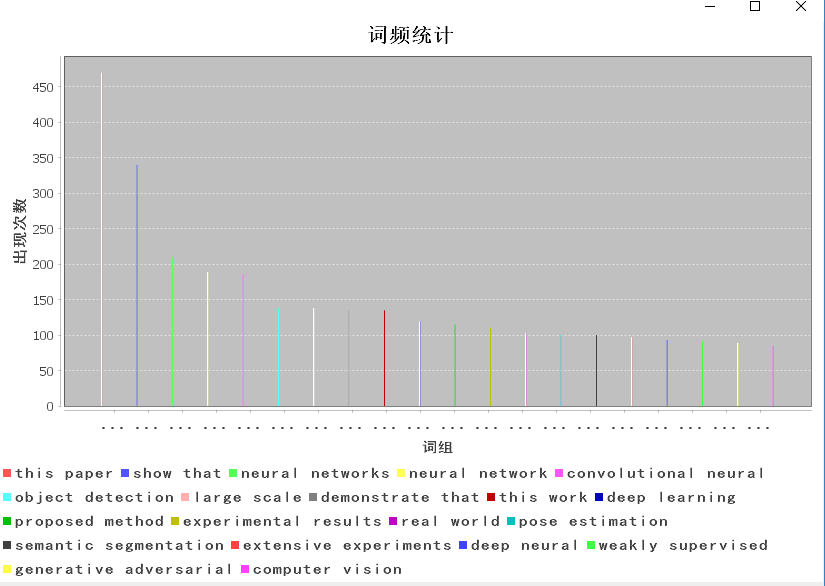
section 4.神经网络的构建(未实现)
辛苦一晚上,想视图将构建神经网络功能植入代码,但很遗憾gephi-tookit没能够很好的实现,目前尚未实现。
可能是自己太过天真,想视图将所有的功能都用java语言实现,看到大家分门别类的工具使用顿时大悟,很遗憾时间不够没办法再进一步推进,其实大概也了解了Gephi工具的使用(获取“对象-目标-权重”数据后就可以生成神经网络图)。
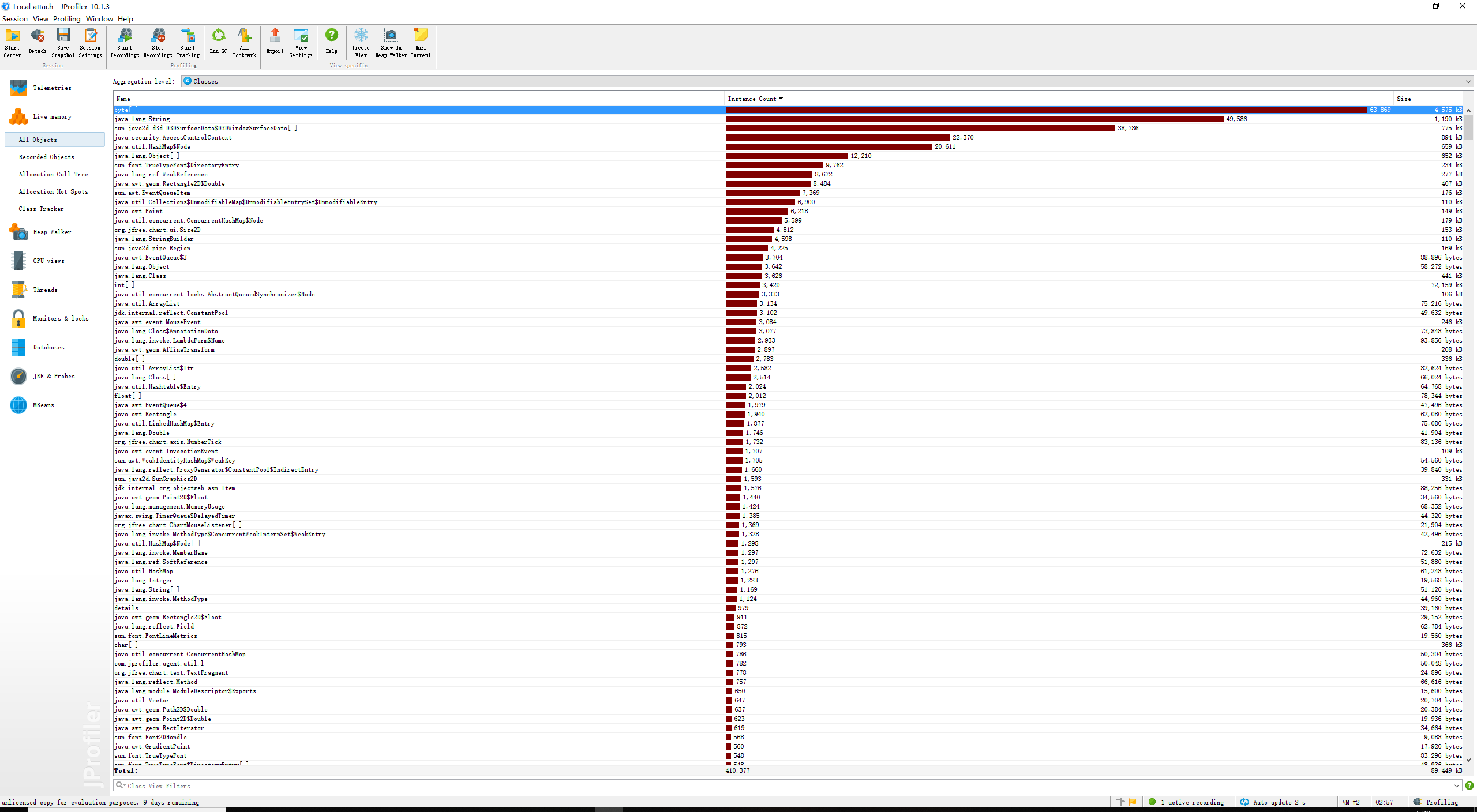
Part 6.性能分析与改进
命令行 -i input.txt -o output.txt -n 20 -m 2 -w 0下的性能测试图
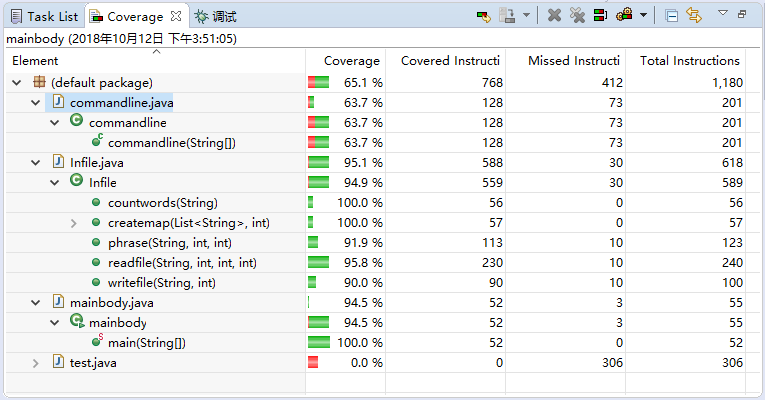
整体正常运行的代码覆盖如下,主要未执行的部分代码存在与commandline.java中,因为其中存在大部分对于异常处理的操作,当正常运行过程中并不会去访问。
Part 7.单元测试
进行了四组单元测试环节,三组针对命令行的不正确输入,一组针对正常运行的代码校验
String args[]={"-i","test.txt","-w","1","-o","output.txt","-n","1","-m","1"};
String args[]={"-i","test.txt","-w","1","-o","output.txt","-n","150","-m","2"};
String args[]={""};
String args[]={"-i","test.txt","-w","1","-o","output.txt","-n","10","-m","2"};
校验的测试文本如下,应检验,代码运行正常
0
Title: E-mbodied Question
Abstract: E-mbodied Question We present a new AI task
1
Title: Embodied Question Answ-ering
Abstract: Embodied Question We present a new AI task
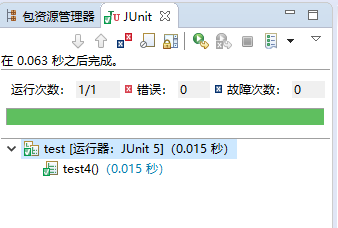
这里仅test 4可正常运行,因为之前的三个test均未通过命令行的异常处理,在输出err信息后程序均进入中断,这里贴上test 4的结果

Part 8.贴出Github的代码签入记录
Part 9.遇到的代码模块异常或结对困难及解决方法
问题描述
- 命令行要求的限制问题:如何在第一时间处理掉非正常的操作
- 两部分文本整合生成详细信息的.csv过程中,存在部分无法匹配的情形
- 内部对于相关文本存在大量需要处理的情形
做过哪些尝试
- 增设判断,抛出异常信息后直接exit()中断程序的运行
- 增设文本的清洗统一化处理:对于title作于key的情形,统一进行
.toLowerCase()操作,各项不合法符号化作分隔符,剩下的属于内容不匹配,即两处title仅部分内容相同的我姑且忽略(当然也可以进行模糊匹配,尽可能去配对映射) - 设置flag标记符作为判断依据,方便多种情况的适应性问题
是否解决
除未能实现gephi-tookit的神经网络生成外,其余均解决
有何收获
需要纠正自己的编码习惯,养成一个自定义deadline的编码原则,在代码的可读性上还需要多下功夫,总体来说,自己在接触新鲜的事物的过程中及时编码很辛苦但是内心很满足。
Part 10.评价你的队友
总的来说,我的队友在任务执行过程中相当配合,遇到不会的问题时及时的反馈与沟通,通过交流加上查找大量资料从而解决问题,关于爬虫jsoup为什么没能够爬取到全部的内容,我也是在和他一起沟通查找资料的过程中了解到:
原来在默认设置下,jsoup最大获取的响应长度正好时1M。所以这个时候需要设置connection.maxBodySize(0)来得到不限响应长度的数据。参考博客链接
但同时存在的问题是需要提高下集中式的独立编码能力,一项任务尽可能在一定时间内完成交付
Part 11.学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 5 | 1000+ | N | 36 | 45 | 学习java数据图形化处理,了解部分数据处理 |
| 6 | 1000+ | N | 18 | 63 | 学习《构建之法》,加深单元测试的应用,补缺补漏 |
结对作业_Two的更多相关文章
- 结对作业1----基于flask框架的四则运算生成器
011.012结对作业 coding地址:https://coding.net/u/nikochan/p/2nd_SE/git 一.作业描述 由于上次作业我没有按时完成,而且庞伊凡同学编程能力超棒,所 ...
- 软件工程第三次作业-结对作业NO.1
第一次结对作业 结对人员: 潘伟靖 170320077 张 松 170320079 方案分析 我们对所供的资料进行分析,如下: 从提供的资料可以看出,需要解决的问题以及满足的需求主要有两类目标用户,各 ...
- 第6次结对作业--郑锦伟&古维城
第6次结对作业 在线英语学习平台客户端原型 1.结对成员 郑锦伟 2015034643034 古维城 2015034643033 2.原型设计工具实现-Photoshop 3.需求分析 使用NABCD ...
- [2019BUAA软件工程]结对作业
Tips Link 作业链接 [2019BUAA软件工程]结对作业 GitHub地址 WordChain PSP表格 psp2.1 预估耗时(分钟) 实际耗时(分钟) Planning 计划 60 ...
- [BUAA软工]第一次结对作业
[BUAA软工]结对作业 本次作业所属课程: 2019BUAA软件工程 本次作业要求: 结对项目 我在本课程的目标: 熟悉结对合作,为团队合作打下基础 本次作业的帮助:理解一个c++ 项目的开发历程 ...
- 软工实践——结对作业2【wordCount进阶需求】
附录: 队友的博客链接 本次作业的博客链接 同名仓库项目地址 一.具体分工 我负责撰写爬虫爬取信息以及代码整合测试,队友子恒负责写词组词频统计功能的代码. 二.PSP表格 PSP2.1 Persona ...
- 第四,五周——Java编写的电梯模拟系统(结对作业)
作业代码:https://coding.net/u/liyi175/p/Dianti/git 伙伴成员:石开洪 http://www.cnblogs.com/shikaihong/(博客) 这次的作业 ...
- 结对作业——随机生成四则运算(Core 第7组)
结对作业 ——随机生成四则运算(core第7组) 吕佳玲 PB16060145 涂涵越 PB16060282 GITHUB地址 https://github.com/hytu99/homework_2 ...
- 结对作业(1.0版)(bug1已修复)
import java.awt.EventQueue; import javax.swing.JFrame; import javax.swing.JPanel; import javax.swing ...
随机推荐
- MySQL----MySQL数据库入门----第三章 添加、更新与删除数据
3.1 添加数据 ①为所有字段添加数据 方法1:字段包含全部定义的字段 insert into 表名(字段1,字段2...字段n) values(值1,值2,......,值n); 方法2:值必须与字 ...
- Yar请求数据接口
//[['u'=>'site.index','d'=>['a'=>2],'k'=>'test']]; public function apiBatch($arr,$timeou ...
- STM32 HAL库学习系列第4篇 定时器TIM----- 开始定时器与PWM输出配置
基本流程: 1.配置定时器 2.开启定时器 3.动态改变pwm输出,改变值 HAL_TIM_PWM_Start(&htim4, TIM_CHANNEL_1); 函数总结: __HAL_TIM ...
- C语言简易三子棋
这是本人依据现学知识写的简易三子棋,也不是那么简洁明了,望大佬指点 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include&l ...
- 二叉树 ADT接口 遍历算法 常规运算
BTree.h (结构定义, 基本操作, 遍历) #define MS 10 typedef struct BTreeNode{ char data; struct BTreeNode * lef ...
- Vue2.5入门-2
todolist功能开发 代码 <!DOCTYPE html> <html> <head> <title>vue 入门</title> &l ...
- IDEA 通过插件jetty-maven-plugin使用 jetty
jetty:run -Djetty.port=8080 pom.xml配置 <build> <plugins> <plugin> <groupId>or ...
- Mac配置MySql
MySql在Mac下的情况如下: 首先,我们进入MySql的官网下载MySql(直接点击即可),打开之后便是这样. 我们点击红色方框标记的内容,之后我等待下载完成. 下载完成之后,我们需要点点,注意一 ...
- 20155217 2016-2017-2 《Java程序设计》第6周学习总结
20155217 2016-2017-2 <Java程序设计>第6周学习总结 教材学习内容总结 第十章 InputStream与OutputStream 10.1.1串流设计的概念 Jav ...
- 20155217 2016-2017-2 《Java程序设计》第3周学习总结
20155217 2016-2017-2 <Java程序设计>第3周学习总结 教材学习内容总结 第四章 要产生对象必须先定义类,类定义时使用class关键词,建立实例要使用new关键词. ...