python中的shallow copy 与 deep copy
今天在写代码的时候遇到一个奇葩的问题,问题描述如下:
代码中声明了一个list,将list作为参数传入了function1()中,在function1()中对list进行了del()即删除了一个元素。
而function2()也把list作为参数传入使用,在调用完function1()之后再调用function2()就出现了问题,list中的值已经被改变了,就出现了bug。
直接上代码:
list = [0, 1, 2, 3, 4, 5] def function1(list):
del list[1]
print(list) def function2(list):
print(list) function1(list)
function2(list)
我并不希望function2()中的list改变,查了一下解决办法说是可对list进行copy:
newList = list.copy()
function2(newList)
在查解决办法的过程中发现了还有一个方法叫做deepcopy(),那么问题来了,deepcopy()与copy()的区别是什么?
先点到源码里看了下源码,发现有注释,很开心。注释如下:
"""Generic (shallow and deep) copying operations.
Interface summary:
import copy
x = copy.copy(y) # make a shallow copy of y
x = copy.deepcopy(y) # make a deep copy of y
For module specific errors, copy.Error is raised.
The difference between shallow and deep copying is only relevant for
compound objects (objects that contain other objects, like lists or
class instances).
- A shallow copy constructs a new compound object and then (to the
extent possible) inserts *the same objects* into it that the
original contains.
- A deep copy constructs a new compound object and then, recursively,
inserts *copies* into it of the objects found in the original.
Two problems often exist with deep copy operations that don't exist
with shallow copy operations:
a) recursive objects (compound objects that, directly or indirectly,
contain a reference to themselves) may cause a recursive loop
b) because deep copy copies *everything* it may copy too much, e.g.
administrative data structures that should be shared even between
copies
Python's deep copy operation avoids these problems by:
a) keeping a table of objects already copied during the current
copying pass
b) letting user-defined classes override the copying operation or the
set of components copied
This version does not copy types like module, class, function, method,
nor stack trace, stack frame, nor file, socket, window, nor array, nor
any similar types.
Classes can use the same interfaces to control copying that they use
to control pickling: they can define methods called __getinitargs__(),
__getstate__() and __setstate__(). See the documentation for module
"pickle" for information on these methods.
"""
然而看了看,一脸懵逼。还是百度继续查资料吧:
https://iaman.actor/blog/2016/04/17/copy-in-python大佬总结的很好。
copy其实就是shallow copy,与之相对的是deep copy
结论:
1.对于简单的object,shallow copy和deep copy没什么区别
>>> import copy
>>> origin = 1
>>> cop1 = copy.copy(origin)
#cop1 是 origin 的shallow copy
>>> cop2 = copy.deepcopy(origin)
#cop2 是 origin 的 deep copy
>>> origin = 2
>>> origin
2
>>> cop1
1
>>> cop2
1
#cop1 和 cop2 都不会随着 origin 改变自己的值
>>> cop1 == cop2
True
>>> cop1 is cop2
True
2.复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的子list,并未从原 object 真的「独立」出来。
如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。
>>> import copy
>>> origin = [1, 2, [3, 4]]
#origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
#cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, ['hey!', 4]]
>>> cop1
[1, 2, ['hey!', 4]]
>>> cop2
[1, 2, [3, 4]]
#把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2
cop1,也就是shallow copy 跟着 origin 改变了。而 cop2 ,也就是 deep copy 并没有变。
那么问题又来了,有deepcopy直接用就好了为啥还要有copy?
这个问题的解决要从python变量存储的方法说起,在python中,与其说是把值赋给了变量,不如说是给变量建立了一个到具体值的reference(引用)
>>> a = [1, 2, 3]
>>> b = a
>>> a = [4, 5, 6] //赋新的值给 a
>>> a
[4, 5, 6]
>>> b
[1, 2, 3]
# a 的值改变后,b 并没有随着 a 变 >>> a = [1, 2, 3]
>>> b = a
>>> a[0], a[1], a[2] = 4, 5, 6 //改变原来 list 中的元素
>>> a
[4, 5, 6]
>>> b
[4, 5, 6]
# a 的值改变后,b 随着 a 变了
上面代码,都改变了a的值,不同的是:第一段是给a赋新值,第二段是直接改变了list中的元素。
下面解释下这诡异的现象:
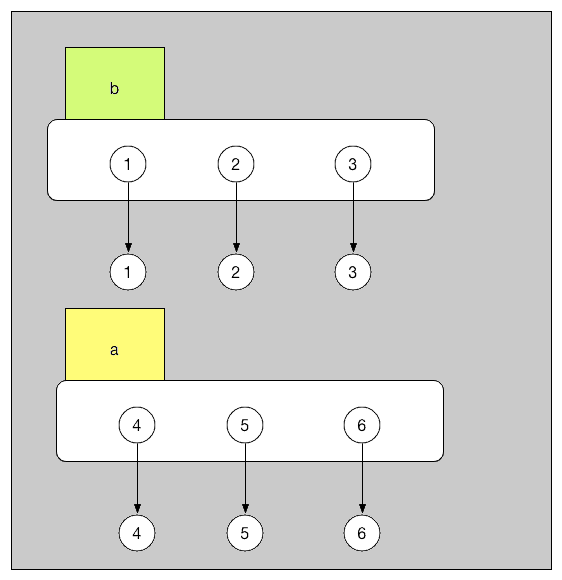
首次把 [1, 2, 3] 看成一个物品。a = [1, 2, 3] 就相当于给这个物品上贴上 a 这个标签。而 b = a 就是给这个物品又贴上了一个 b的标签。

第一种情况:
a = [4, 5, 6] 就相当于把 a 标签从 [1 ,2, 3] 上撕下来,贴到了 [4, 5, 6] 上。
在这个过程中,[1, 2, 3] 这个物品并没有消失。 b 自始至终都好好的贴在 [1, 2, 3] 上,既然这个 reference 也没有改变过。 b 的值自然不变。
第二种情况:
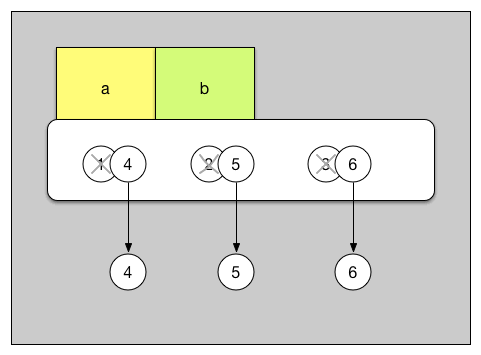
a[0], a[1], a[2] = 4, 5, 6 则是直接改变了 [1, 2, 3] 这个物品本身。把它内部的每一部分都重新改装了一下。内部改装完毕后,[1, 2, 3] 本身变成了 [4, 5, 6]。
而在此过程当中,a 和 b 都没有动,他们还贴在那个物品上。因此自然 a b 的值都变成了 [4, 5, 6]。
用copy.copy()。结果却发现本体与 copy 之间并不是独立的。有的时候改变其中一个,另一个也会跟着改变。也就是本文一开头提到的例子:
>>> import copy
>>> origin = [1, 2, [3, 4]]
#origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
#cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, ['hey!', 4]]
>>> cop1
[1, 2, ['hey!', 4]]
>>> cop2
[1, 2, [3, 4]]
#把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2
官方解释:
The difference between shallow and deep copying is only relevant for compound objects (objects that contain other objects, like lists or class instances): A shallow copy constructs a new compound object and then (to the extent possible) inserts references into it to the objects found in the original. A deep copy constructs a new compound object and then, recursively, inserts copies into it of the objects found in the original. 两种 copy 只在面对复杂对象时有区别,所谓复杂对象,是指对象中含其他对象(如复杂的 list 和 class)。 由 shallow copy 建立的新复杂对象中,每个子对象,都只是指向自己在原来本体中对应的子对象。而 deep copy 建立的复杂对象中,存储的则是本体中子对象的 copy,并且会层层如此 copy 到底。
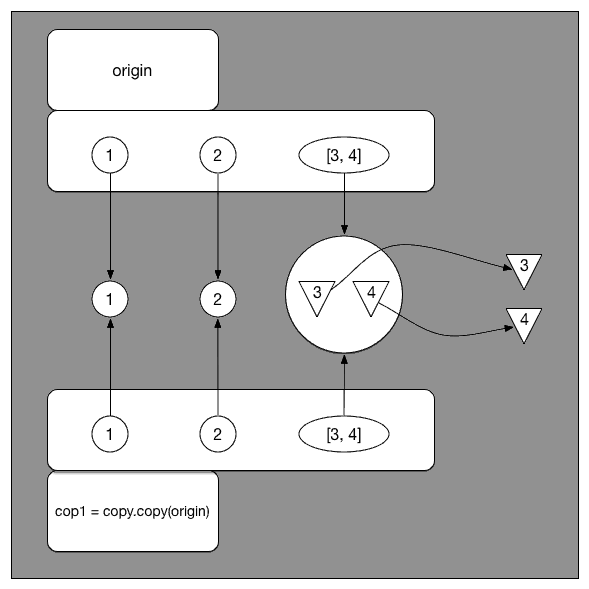
先看这里的 shallow copy。 如图所示,cop1 就是给当时的 origin 建立了一个镜像。origin 当中的元素指向哪, cop1 中的元素就也指向哪。这就是官方 doc 中所说的 inserts references into it to the objects found in the original 。
这里的关键在于,origin[2],也就是 [3, 4] 这个 list。根据 shallow copy 的定义,在 cop1[2] 指向的是同一个 list [3, 4]。那么,如果这里我们改变了这个 list,就会导致 origin 和 cop1 同时改变。这就是为什么上边 origin[2][0] = "hey!" 之后,cop1 也随之变成了 [1, 2, ['hey!', 4]]。
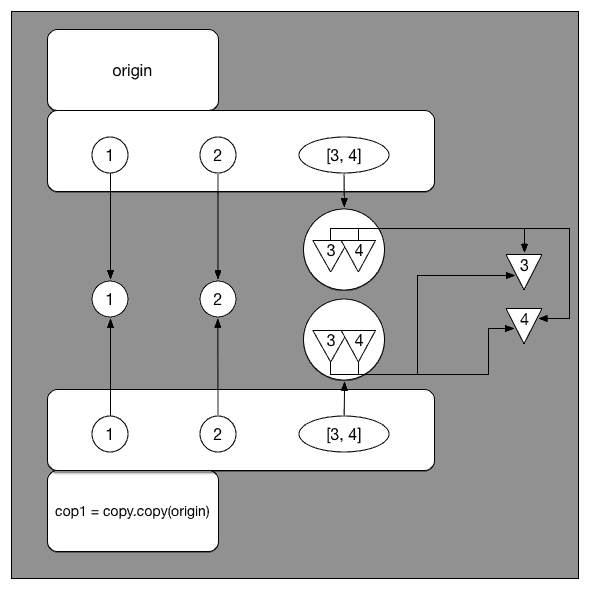
再来看 deep copy。 从图中可以看出,cop2 是把 origin 每层都 copy 了一份存储起来。这时候的 origin[2] 和 cop2[2] 虽然值都等于 [3, 4],但已经不是同一个 list了。
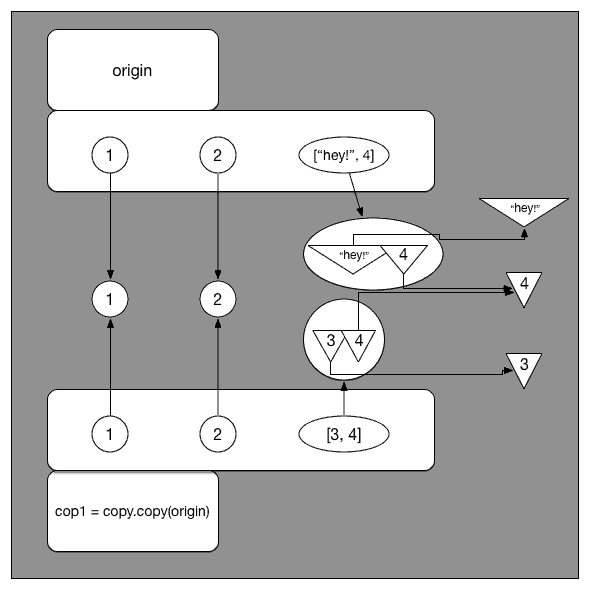
既然完全独立,那无论如何改变其中一个,另一个自然不会随之改变。
python中的shallow copy 与 deep copy的更多相关文章
- Shallow copy and Deep copy
Shallow copy and Deep copy 第一部分: 一.来自wikipidia的解释: Shallow copy One method of copying an object is t ...
- NumPy学习(索引和切片,合并,分割,copy与deep copy)
NumPy学习(索引和切片,合并,分割,copy与deep copy) 目录 索引和切片 合并 分割 copy与deep copy 索引和切片 通过索引和切片可以访问以及修改数组元素的值 一维数组 程 ...
- shallow copy 和 deep copy 的示例
本文属原创,转载请注明出处:http://www.cnblogs.com/robinjava77/p/5481874.html (Robin) Student package base; impo ...
- copy&mutableCopy 浅拷贝(shallow copy)深拷贝 (deep copy)
写在前面 其实看了这么多,总结一个结论: 拷贝的初衷的目的就是为了:修改原来的对象不能影响到拷贝出来得对象 && 修改拷贝出来的对象也不能影响到原来的对象 所以,如果原来对象就是imm ...
- copy和deep.copy
https://blog.csdn.net/qq_32907349/article/details/52190796 加上crossin公众号上的可变对象与不可变对象 a=[1,2,3,[4]] b= ...
- Python 浅拷贝copy()与深拷贝copy.deepcopy()
首先我在这介绍两个新的小知识,要在下面用到.一个是函数 id() ,另一个是运算符 is.id() 函数就是返回对象的内存地址:is 是比较两个变量的对象引用是否指向同一个对象,在这里请不要和 == ...
- Python中的Copy和Deepcopy
一,Python的对象: Python存在大量的对象,我们一般提到的对象都是C中的结构体在堆中申请的一块内存(以CPython为例),每一个对象都有ID,可以通过ID(Object)获得.对象的范围包 ...
- python中copy()和deepcopy()详解
**首先直接上结论: —–我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在.所以改变原有被复制对象不会对已经复制出来的新对象产生影响.—–而浅复制并不会产生一个独立的 ...
- shallow copy & deep copy
1.深复制与浅复制的概念 ->浅复制(shallow copy)概念 在SDK Guides中(搜索copy),官方给出的浅复制概念为: Copying compound objects, ...
随机推荐
- BigDecimal类(精度计算类)的加减乘除
BigDecimal类 对于不需要任何准确计算精度的数字可以直接使用float或double,但是如果需要精确计算的结果,则必须使用BigDecimal类,而且使用BigDecimal类也可以进行大数 ...
- org.apache.ibatis.builder.IncompleteElementException: Could not find parameter map com.hyzn.historicalRecord.dao.ITB_HISTORYLOGDAO.TB_HISTORYLOGResultMap
用了很久的myBatis,忽然出现这个错误,感觉配置什么的都是正确的,错误如下: org.apache.ibatis.builder.IncompleteElementException: Could ...
- windows命令之PING DIR DEL CD TASKLIST (转)
最简单的莫过于PING命令了. PING命令的功能就是给对方主机发送IP数据包. 一般都是测试主机是否在线. 用法如下: PING 192.168.1.1.PING命令默认发送的是四个数据包,当然也可 ...
- Sphinx以及coreseek的安装及使用 .No1
检索结构php -> sphinx -> mysql非结构化数据又叫全文数据,非固定长度字段例如文章标题搜索这类适用sphinx 全文数据搜索:顺序扫描 : 如like查找索引扫描 : 把 ...
- 基于Cocos2d-x学习OpenGL ES 2.0系列——纹理贴图(6)
在上一篇文章中,我们介绍了如何绘制一个立方体,里面涉及的知识点有VBO(Vertex Buffer Object).IBO(Index Buffer Object)和MVP(Modile-View-P ...
- 阿里大于短信返回XML
返回异常和成功的两种不同,XML返回直接拿alibaba_aliqin_fc_sms_num_send_response判断节点是否有这个名字 官方API地址: https://api.alidayu ...
- 【BZOJ5109】[CodePlus 2017]大吉大利,晚上吃鸡! 最短路+拓扑排序+DP
[BZOJ5109][CodePlus 2017]大吉大利,晚上吃鸡! Description 最近<绝地求生:大逃杀>风靡全球,皮皮和毛毛也迷上了这款游戏,他们经常组队玩这款游戏.在游戏 ...
- 【BZOJ4523】[Cqoi2016]路由表 Trie树模拟
[BZOJ4523][Cqoi2016]路由表 Description 路由表查找是路由器在转发IP报文时的重要环节.通常路由表中的表项由目的地址.掩码.下一跳(Next Hop)地址和其他辅助信息组 ...
- Python - 3.6 学习第一天
开始之前 基础示例 Python语法基础,python语法比较简单,采用缩紧方式. # print absolute value of a integer a = 100 if a >= 0: ...
- ThinkPHP的增删改查!
对表的操作: 增加:M('表名')->add($data); (可以是数组) 删除:M('表名')->delete($data); (不可以是数组,删除多个有另外的方法) 修改:M('表 ...