数据挖掘-逻辑Logistic回归
逻辑回归的基本过程:a建立回归或者分类模型--->b 建立代价函数 ---> c 优化方法迭代求出最优的模型参数 --->d 验证求解模型的好坏。
1.逻辑回归模型:
逻辑回归(Logistic Regression):既可以看做是回归算法,也可以看做是分类算法。通常作为分类算法,一般用于解决二分类问题。
线性回归模型如下:
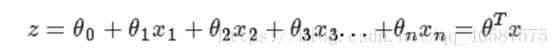
逻辑回归思想是基于线性回归(Logistic Regression是广义的线性回归模型),公式如下:
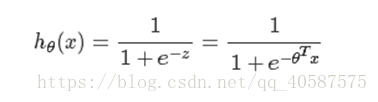
其中,
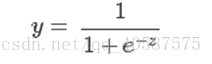
称为Sigmoid函数
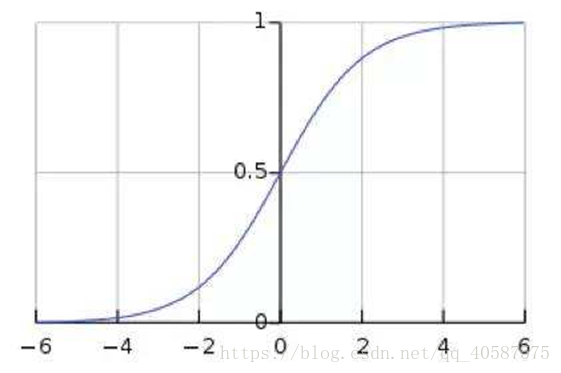
由图可知:Sigmoid函数值域是在(0 , 1)之间,中间值为0.5 ,所以逻辑回归函数可以表示数据属于某一类别的概率:
h_θ(x) ≥ 0.5,预测 y=1 类
h_θ(x) < 0.5,预测 y=0类
2.代价函数
代价函数是基于最大似然函数推导出来的。
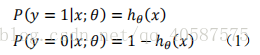
将上式(1)可写成下面这个式子:
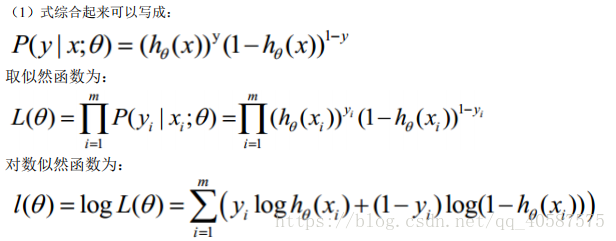
将式子乘一个(-1/m),使用梯度下降法求最优解 θ 参数
当x和y为多维时:

2.1 梯度下降法求解最小值
求解函数的最优解(极大值和极小值),在数学中我们一般会对函数求导,然后让导数等于0,获得方程,然后通过解方程直接得到结果。但是在机器学习中,我们的函数常常是多维高阶的,得到导数为0的方程后很难直接求解(有些时候甚至不能求解),所以就需要通过其他方法来获得这个结果,而梯度下降就是其中一种。
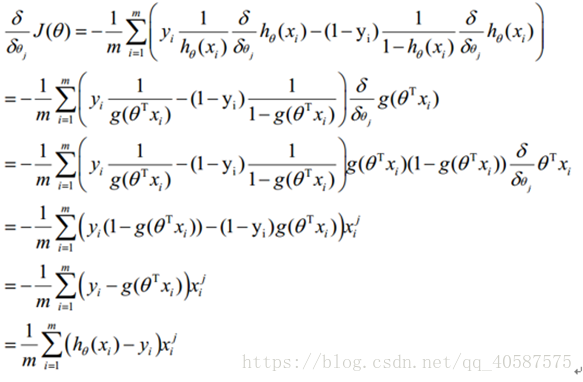
对θ 参数进行更新:
α 为学习率

3.正则化:
(1)过拟合问题
过拟合即是过分拟合了训练数据,使得模型的复杂度提高,但是泛化能力较差。
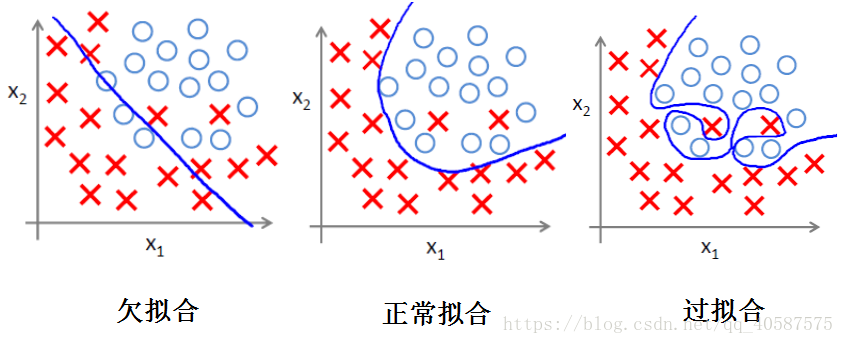
(2)正则化方法 :
正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项或惩罚项。
正则项可以取不同的形式,在回归问题中取平方损失,就是参数的L2范数,也可以取L1范数。取平方损失时,模型的损失函数变为:
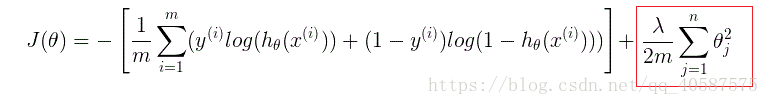
lambda是正则项系数(λ):
• 如果它的值很大,说明对模型的复杂度惩罚大,可能导致欠拟合; (使得J(θ) 最小化,当λ 值很大时,θ→0)
如:曲线为 z=θ_0+θ_1 x_1+θ_2 x_1^2+λθ_3 x_2^3 ----> θ_3→0
• 如果它的值很小,说明比较注重对训练数据的拟合,在训练数据上的偏差会小,但是可能会导致过拟合。(保留更多的θ)
正则化后的梯度下降算法θ的更新变为:
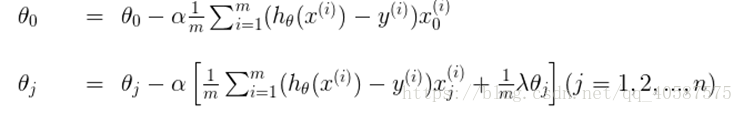
4.逻辑回归的优缺点:
优点:(1)速度快, 适合二分类问题
(2)简单易于理解, 直接看到各个特征的权重
(3)能容易吸收新的数据
缺点:对数据和场景的使用能力有限, 不如决策树算法适应性强
对某一银行在降低贷款拖欠率的数据进行逻辑回归建模:
使用稳定性选择方法中的随机逻辑回归进行特征筛选, 然后对筛选后的特征建立逻辑回归模型
#coding=gbk
#使用稳定性选择方法中的随机逻辑回归进行特征筛选, 然后对筛选后的特征建立逻辑回归模型
import pandas as pd
import numpy as np
filename = r'D:\datasets\bankloan.xls'
data = pd.read_excel(filename)
print(data.head())
# 年龄 教育 工龄 地址 收入 负债率 信用卡负债 其他负债 违约
# 0 41 3 17 12 176 9.3 11.359392 5.008608 1
# 1 27 1 10 6 31 17.3 1.362202 4.000798 0
# 2 40 1 15 14 55 5.5 0.856075 2.168925 0
# 3 41 1 15 14 120 2.9 2.658720 0.821280 0
# 4 24 2 2 0 28 17.3 1.787436 3.056564 1
x = data.iloc[:,:8].as_matrix()
y = data.iloc[:,8].as_matrix() #转换成矩阵形式,使其没有索引项 是否违约1,0
from sklearn.linear_model import RandomizedLogisticRegression as RLR
rlr = RLR()
rlr.fit(x, y)
rlr.get_support() #获取特征筛选结果,
print(rlr.get_support()) #[False False True True False True True False]
print(rlr.scores_) #[0.085 0.045 0.995 0.395 0. 0.995 0.595 0.04 ] 获取特征结果的分数
print('通过随机逻辑回归模型筛选特征结束')
# print(u'有效特征为:%s' % ','.join(data.columns[rlr.get_support()]))
# x = data[data.columns[rlr.get_support()]].as_matrix()
print(u'有效特征为:%s' % ','.join(np.array(data.iloc[:,:8].columns)[rlr.get_support()]))
x = data[np.array(data.iloc[:,:8].columns)[rlr.get_support()]].as_matrix() #筛选好特征
from sklearn.linear_model import LogisticRegression as LR
lr = LR()
lr.fit(x,y)
print('通过逻辑回归模型训练结束')
print('模型的平均正确率为: %s' % lr.score(x,y))
# 通过随机逻辑回归模型筛选特征结束
# 有效特征为:工龄,地址,负债率,信用卡负债
# 通过逻辑回归模型训练结束
# 模型的平均正确率为: 0.8142857142857143
Python中逻辑回归的实现:
#coding=gbk
'''
Created on 2018年7月2日
@author: Administrator
'''
from math import exp
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets.samples_generator import make_blobs
#定义一个sigmoid函数
def sigmoid(num):
if type(num)==int or type(num)== float:
return 1.0/(1 + exp(-1 * num))
else:
raise ValueError('只有int and float 类型才能进行计算')
#定义一个逻辑回归的类
class logistic():
def __init__(self,x,y): #判断输入的数据是否符合,并将其转换成ndarray
if type(x) == type(y) == list:
self.x = np.array(x)
self.y = np.array(y)
elif type(x) == type(y) ==np.ndarray:
self.x = x
self.y = y
else:
raise ValueError('输入数据错误')
def sigmoid(self,x): #输出向量整体进行sigmoid 计算后的向量结果
s = np.frompyfunc(lambda x: sigmoid(x), 1,1) #得到矩阵
return s(x)
def train_and_punish(self,alpha, errors , punish = 0.0001):
'''
alpha 为学习率
errors 为误差小于多少时停止迭代的次数
punish 为惩罚系数
times 为最大迭代次数
'''
self.punish = punish
dimension = self.x.shape[1] #得到列的数量
self.theta = np.random.random(dimension) #对theta 去随机数
computer_error = 100000000
times = 0
while computer_error > errors:
res = np.dot(self.x, self.theta)
delta = self.sigmoid(res) - self.y #这里使用了向量化,计算sigmoid函数得出的结果与0,1的差
self.theta = self.theta - alpha * np.dot(self.x.T, delta) - punish * self.theta #更新学习率
computer_error = np.sum(delta)
times+=1
def predict(self, x):
x = np.array(x)
if self.sigmoid(np.dot(x, self.theta)) > 0.5:
return 1
else:
return 0
def test():
#scikit中的make_blobs方法常被用来生成聚类算法的测试数据,
#直观地说,make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果。
# n_samples是待生成的样本的总数。
# n_features是每个样本的特征数。
# centers表示类别数。
# cluster_std表示每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0]。
#center_box 表示x,y轴的范围
x, y = make_blobs(n_samples=200, centers =2, n_features=2, random_state=0, center_box=(10,20))
x1=[]
y1=[]
x2=[]
y2=[]
#生成两类数据
for i in range(len(y)):
if y[i] ==0:
x1.append(x[i][0])
y1.append(x[i][1])
elif y[i] == 1:
x2.append(x[i][0])
y2.append(x[i][1])
p = logistic(x,y)
p.train_and_punish(alpha=0.00001, errors=0.005, punish=0.01)
x_test = np.arange(10,20,0.01)
y_test = (-1* p.theta[0] / p.theta[1]) * x_test
plt.plot(x_test, y_test, c='g', label = 'logistic_line')
plt.scatter(x1, y1, c='r', label = 'positive')
plt.scatter(x2, y2, c='b',label ='negtive')
plt.legend(loc =2)
plt.title('punish value = ' + p.punish.__str__())
plt.show()
if __name__ == '__main__':
test()

LogisticRegression类的各项参数的含义:
class sklearn.linear_model.LogisticRegression(penalty='l2',
dual=False, tol=0.0001, C=1.0, fit_intercept=True,
intercept_scaling=1, class_weight=None,
random_state=None, solver='liblinear', max_iter=100,
multi_class='ovr', verbose=0, warm_start=False, n_jobs=1)
penalty='l2' : 字符串‘l1’或‘l2’,默认‘l2’。
- 用来指定惩罚的基准(正则化参数)。只有‘l2’支持‘newton-cg’、‘sag’和‘lbfgs’这三种算法。
- 如果选择‘l2’,solver参数可以选择‘liblinear’、‘newton-cg’、‘sag’和‘lbfgs’这四种算法;如果选择‘l1’的话就只能用‘liblinear’算法。
dual=False : 对偶或者原始方法。Dual只适用于正则化相为l2的‘liblinear’的情况,通常样本数大于特征数的情况下,默认为False。C=1.0 : C为正则化系数λ的倒数,必须为正数,默认为1。和SVM中的C一样,值越小,代表正则化越强。fit_intercept=True : 是否存在截距,默认存在。intercept_scaling=1 : 仅在正则化项为‘liblinear’,且fit_intercept设置为True时有用。solver='liblinear' : solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择。
- a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
| 正则化 | 算法 | 适用场景 |
|---|---|---|
| L1 | liblinear | liblinear适用于小数据集;如果选择L2正则化发现还是过拟合,即预测效果差的时候,就可以考虑L1正则化;如果模型的特征非常多,希望一些不重要的特征系数归零,从而让模型系数稀疏化的话,也可以使用L1正则化。 |
| L2 | liblinear | libniear只支持多元逻辑回归的OvR,不支持MvM,但MVM相对精确。 |
| L2 | lbfgs/newton-cg/sag | 较大数据集,支持one-vs-rest(OvR)和many-vs-many(MvM)两种多元逻辑回归。 |
| L2 | sag | 如果样本量非常大,比如大于10万,sag是第一选择;但不能用于L1正则化。 |
multi_class='ovr' : 分类方式。官网有个对比两种分类方式的例子:链接地址。
- ovr即one-vs-rest(OvR),multinomial是many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
- ovr不论是几元回归,都当成二元回归来处理。mvm从从多个类中每次选两个类进行二元回归。如果总共有T类,需要T(T-1)/2次分类。
- OvR相对简单,但分类效果相对略差(大多数样本分布情况)。而MvM分类相对精确,但是分类速度没有OvR快。
- 如果选择了ovr,则4种损失函数的优化方法liblinear,newton-cg,lbfgs和sag都可以选择。但是如果选择了multinomial,则只能选择newton-cg, lbfgs和sag了。
class_weight=None : 类型权重参数。用于标示分类模型中各种类型的权重。默认不输入,即所有的分类的权重一样。
- 选择‘balanced’自动根据y值计算类型权重。
- 自己设置权重,格式:
{class_label: weight}。例如0,1分类的er'yuan二元模型,设置class_weight={0:0.9, 1:0.1},这样类型0的权重为90%,而类型1的权重为10%。
random_state=None : 随机数种子,默认为无。仅在正则化优化算法为sag,liblinear时有用。
max_iter=100 : 算法收敛的最大迭代次数。
tol=0.0001 : 迭代终止判据的误差范围。
verbose=0 : 日志冗长度int:冗长度;0:不输出训练过程;1:偶尔输出; >1:对每个子模型都输出
warm_start=False : 是否热启动,如果是,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)。布尔型,默认False。
n_jobs=1 : 并行数,int:个数;-1:跟CPU核数一致;1:默认值。
LogisticRegression类的常用方法
fit(X, y, sample_weight=None)- 拟合模型,用来训练LR分类器,其中X是训练样本,y是对应的标记向量
- 返回对象,self。
fit_transform(X, y=None, **fit_params)- fit与transform的结合,先fit后transform。返回
X_new:numpy矩阵。
- fit与transform的结合,先fit后transform。返回
predict(X)- 用来预测样本,也就是分类,X是测试集。返回array。
predict_proba(X)- 输出分类概率。返回每种类别的概率,按照分类类别顺序给出。如果是多分类问题,multi_class="multinomial",则会给出样本对于每种类别的概率。
- 返回array-like。
score(X, y, sample_weight=None)- 返回给定测试集合的平均准确率(mean accuracy),浮点型数值。
- 对于多个分类返回,则返回每个类别的准确率组成的哈希矩阵。
参考:机器学习之逻辑回归
数据挖掘-逻辑Logistic回归的更多相关文章
- 机器学习实战3:逻辑logistic回归+在线学习+病马实例
本文介绍logistic回归,和改进算法随机logistic回归,及一个病马是否可以治愈的案例.例子中涉及了数据清洗工作,缺失值的处理. 一 引言 1 sigmoid函数,这个非线性函数十分重要,f( ...
- 《机器学习实战》-逻辑(Logistic)回归
目录 Logistic 回归 本章内容 回归算法 Logistic 回归的一般过程 Logistic的优缺点 基于 Logistic 回归和 Sigmoid 函数的分类 Sigmoid 函数 Logi ...
- 机器学习入门-逻辑(Logistic)回归(1)
原文地址:http://www.bugingcode.com/machine_learning/ex3.html 关于机器学习的教程确实是太多了,处于这种变革的时代,出去不说点机器学习的东西,都觉得自 ...
- 机器学习入门 - 逻辑(Logistic)回归(5)
原文地址:http://www.bugingcode.com/machine_learning/ex7.html 把所有的问题都转换为程序问题,可以通过程序来就问题进行求解了. 这里的模拟问题来之于C ...
- Logistic回归(逻辑回归)和softmax回归
一.Logistic回归 Logistic回归(Logistic Regression,简称LR)是一种常用的处理二类分类问题的模型. 在二类分类问题中,把因变量y可能属于的两个类分别称为负类和正类, ...
- 机器学习之逻辑回归(logistic回归)
前言 以下内容是个人学习之后的感悟,转载请注明出处~ 逻辑回归 一.为什么使用logistic回归 一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大 ...
- 数据挖掘算法(三)--logistic回归
数据挖掘算法学习笔记汇总 数据挖掘算法(一)–K近邻算法 (KNN) 数据挖掘算法(二)–决策树 数据挖掘算法(三)–logistic回归 在介绍logistic回归之前先复习几个基础知识点,有助于后 ...
- 【机器学习实战】第5章 Logistic回归(逻辑回归)
第5章 Logistic回归 <script type="text/javascript" src="http://cdn.mathjax.org/mathjax/ ...
- 常见算法(logistic回归,随机森林,GBDT和xgboost)
常见算法(logistic回归,随机森林,GBDT和xgboost) 9.25r早上面网易数据挖掘工程师岗位,第一次面数据挖掘的岗位,只想着能够去多准备一些,体验面这个岗位的感觉,虽然最好心有不甘告终 ...
随机推荐
- iOS 注冊本地通知(推送)
注:按Home键让App进入后台执行时.方可查看通知. - (BOOL)application:(UIApplication *)application didFinishLaunchingWithO ...
- php 如何得到不含前导0的时分秒
通常我们获取时分秒是用 date("H:i:s") ,得到的效果是这样的 而如果想获取不含前导0的时分秒的话,就需要把前导0去掉. 如何去掉呢?我们来分析一下,07变7,20还是2 ...
- Android NDK开发-3-环境搭建
1.创建Android工程 2.打开android-ndk32-r10-windows-x86_64\android-ndk-r10\samples例子 3.打开hello-jni,拷贝java代码和 ...
- Access数据操作-01
1.未在本地计算机上注册“Microsoft.Jet.OLEDB.4.0”提供程序 在菜单 “项目”的最下面 工程属性 菜单,选择“生成”选项卡,将目标平台由“Amy CPU”或者“*64”改成“* ...
- python远程登录服务器(paramiko模块安装和使用)
转自:http://www.jb51.net/article/46285.htm 一:简介 由paramiko是用python语言写的一个模块,遵循SSH2协议,支持以加密和认证的方式,进行远程服务器 ...
- Python3 requests 库
requests 安装 使用 requests 发送 GET 请求 使用 requests 发送 POST 请求 使用 requests 维持会话 使用 requests 访问 HTTPS 使用 re ...
- lua和C++交互的lua栈操作——以LuaTinker为例
一. -- C++类注册函数(LuaTinker) 的lua栈操作: -- lua栈内容(执行到pop语句) 栈地址 <--执行语句 space_name[name] = t1 -- (2b8) ...
- Excel 2010 统计行数
1. 首先选择一个空行 2.然后点击如下:公式 --- 3. 第一行:填写“103”,当然我也不能明白为啥填写103.照做就是了. 4.鼠标定位到 第二行 “Ref1”位置,然后 鼠标+shfit 按 ...
- 卸载vue-cli
全局安装:npm install vue-cli -g; 全局卸载:npm uninstall vue-cli -g; 查看vue版本,vue -V 回车,查看vue最新的版本.
- 2.void 0 与 不可靠的undefined
在 ES5 之前,全局的 undefined 也是可以被修改的,而在 ES5 中,该标识符被设计为了只读标识符, 假如你现在的浏览器不是太老,你可以在控制台中输入以下语句测试一下: undefined ...