HashMap,Hash优化与高效散列
OverView
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
This implementation provides constant-time performance for the basic operations (get and put), assuming the hash function disperses the elements properly among the buckets. Iteration over collection views requires time proportional to the "capacity" of the HashMap instance (the number of buckets) plus its size (the number of key-value mappings). Thus, it's very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important.
An instance of HashMap has two parameters that affect its performance: initial capacity and load factor. The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
If many mappings are to be stored in a HashMap instance, creating it with a sufficiently large capacity will allow the mappings to be stored more efficiently than letting it perform automatic rehashing as needed to grow the table.
Note that this implementation is not synchronized. If multiple threads access a hash map concurrently, and at least one of the threads modifies the map structurally, it must be synchronized externally. (A structural modification is any operation that adds or deletes one or more mappings; merely changing the value associated with a key that an instance already contains is not a structural modification.) This is typically accomplished by synchronizing on some object that naturally encapsulates the map. If no such object exists, the map should be "wrapped" using the Collections.synchronizedMap method. This is best done at creation time, to prevent accidental unsynchronized access to the map: Map m = Collections.synchronizedMap(new HashMap(...));The iterators returned by all of this class's "collection view methods" are fail-fast: if the map is structurally modified at any time after the iterator is created, in any way except through the iterator's own remove method, the iterator will throw a ConcurrentModificationException. Thus, in the face of concurrent modification, the iterator fails quickly and cleanly, rather than risking arbitrary, non-deterministic behavior at an undetermined time in the future.
Note that the fail-fast behavior of an iterator cannot be guaranteed as it is, generally speaking, impossible to make any hard guarantees in the presence of unsynchronized concurrent modification. Fail-fast iterators throw ConcurrentModificationException on a best-effort basis. Therefore, it would be wrong to write a program that depended on this exception for its correctness: the fail-fast behavior of iterators should be used only to detect bugs.
This class is a member of the Java Collections Framework.
Feild
DEFAULT_INITIAL_CAPACITY 初始容量
The default initial capacity - MUST be a power of two.
不论传入的initial capacity是多少,都会转化比他小且离他最近的2的幂
至于为什么是2的幂,呵呵呵呵,往下看
| default=16
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
DEFAULT_INITIAL_CAPACITY 初始容量
元素个数永远不会超过这个上限,不论如何设置和扩展。
| MAXIMUM = 1<<30 = 2^29
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
DEFAULT_LOAD_FACTOR 复制因子
当容量达到当前最大容量的多少时需要启动复制
| default = 0.75
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
threshold 复制门槛
当前容量超过(put时检查)threshold时,复制底层数据结果以扩展
if (size++ >= threshold)
resize(2 * table.length);
modCount 修改计数
This field is used to make iterators on Collection-views of
the HashMap fail-fast
Hash
良好的hash保证,所有元素恰好落入数组的中(尽可能减少重复,以便减少指针移动次数)
当出现重复时,以链表的形式保存(新元素插入链表第一个!important)
| HashCode = Object.hashCode()
Magic
| 优化hash与更高效的散列算法
基于位的散列算法
//该方法返回此hash值应该储存在数组的下标
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
| PHP实现的测试代码
<?php
$arr = array();
$length = 10; //array length - 1
$data_length = 2001; //hashcode from 1 to 2002 for($i = 1; $i< $data_length; $i++) { if( !isset($arr[$i & $length]) ) {
$arr[$i & $length] = 1;
} else {
$arr[$i & $length]++;
}
} var_dump($arr);
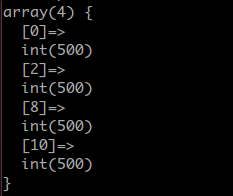
case 1
| $length = 10
| $data_length = 2001
运行结果:
很巧的是,有的下标上居然没有落值,而有值得下标的值非常均匀
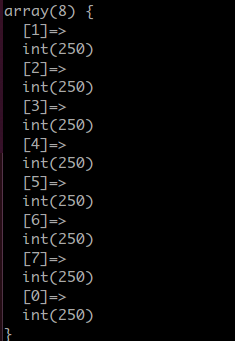
case 2
| $length = 7 = 2^3 - 1
| $data_length = 2001
实验一下数组长度为2的幂
运行结果:
恰好均匀的落在了每一个上面
注意1<<n - 1 的所有位都是1,这样恰好可以保证从任意数恰好均匀落在所有位置上,原理等同于取余,但是限制是底数必须为2的幂,但是全是位操作 ![]()
优化Hash或抵制低效Hash
/**
* Applies a supplemental hash function to a given hashCode, which
* defends against poor quality hash functions. This is critical
* because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
由于ForIndex方法的存在,为了避免出现低位相同的情况(低位相同会导致虽然高位不同的hashcode落在同样的下标上)
例如:原始数组3个(代表3个hash值),分别为 31,63,95,另外初始容量为16 = 2 ^ 4 = 10000
31=00000000000000000000000000011111
63=00000000000000000000000000111111
95=00000000000000000000000001011111
直接使用indexFor()结果如下
31=00000000000000000000000000011111 & 1111 = 1111 & 1111 = 15
63=00000000000000000000000000111111 & 1111 = 1111 & 1111 = 15
95=00000000000000000000000001011111 & 1111 = 1111 & 1111 = 15 //这说明质量低下的hash的低位总是相同,不适应indexFor
使用hash(),结果如下
31=00000000000000000000000000011111 => 00000000000000000000000000011110
63=00000000000000000000000000111111 => 00000000000000000000000000111100
95=00000000000000000000000001011111 => 00000000000000000000000001011010 //这样一来低位就不同了
00000000000000000000000000011110 & 1111 = 1110 & 1111 = 14
00000000000000000000000000111100 & 1111 = 1100 & 1111 = 12
00000000000000000000000001011010 & 1111 = 1010 & 1111 = 10
散列操作的主要目的是使在低位的散列码的差异明显,使得散列映射元件能够均匀地分布
Put & Get
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
e.hash == hash && ((k = e.key) == key || key.equals(k)
Hooks
init
初始化的时候的hook
/**
* Initialization hook for subclasses. This method is called
* in all constructors and pseudo-constructors (clone, readObject)
* after HashMap has been initialized but before any entries have
* been inserted. (In the absence of this method, readObject would
* require explicit knowledge of subclasses.)
*/
void init() {
}
remove & access
//Class.Entry /**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
} /**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
HashMap,Hash优化与高效散列的更多相关文章
- HashMap的实现原理--链表散列
1. HashMap概述 HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变. ...
- Hash算法:双重散列
双重散列是线性开型寻址散列(开放寻址法)中的冲突解决技术.双重散列使用在发生冲突时将第二个散列函数应用于键的想法. 此算法使用: (hash1(key) + i * hash2(key)) % TAB ...
- 【Java集合学习】HashMap源码之“拉链法”散列冲突的解决
1.HashMap的概念 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射. HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io ...
- java 散列与散列码探讨 ,简单HashMap实现散列映射表运行各种操作示列
java 散列与散列码探讨 ,简单HashMap实现散列映射表运行各种操作示列 package org.rui.collection2.maps; /** * 散列与散列码 * 将土拔鼠对象与预报对象 ...
- JDK1.8中对hashmap的优化
在Java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外.HashMap实际上是一个“链表散列”的数据结 ...
- 【数据结构】之散列链表(Java语言描述)
散列链表,在JDK中的API实现是 HashMap 类. 为什么HashMap被称为“散列链表”?这与HashMap的内部存储结构有关.下面将根据源码进行分析. 首先要说的是,HashMap中维护着的 ...
- Android数据加密之SHA安全散列算法
前言: 对于SHA安全散列算法,以前没怎么使用过,仅仅是停留在听说过的阶段,今天在看图片缓存框架Glide源码时发现其缓存的Key采用的不是MD5加密算法,而是SHA-256加密算法,这才勾起了我的好 ...
- 【Java-加密算法】对称加密、非对称加密、单向散列(转)
一提到加密,就会联想到数字签名,这两个经常被混淆的概念到底是什么呢? 加密:加密是一种以密码方式发送信息的方法.只有拥有正确密钥的人才能解开这个信息的密码.对于其他人来说,这个信息看起来就像是一系列随 ...
- JDK8;HashMap:再散列解决hash冲突 ,源码分析和分析思路
JDK8中的HashMap相对JDK7中的HashMap做了些优化. 接下来先通过官方的英文注释探究新HashMap的散列怎么实现 先不给源码,因为直接看源码肯定会晕,那么我们先从简单的概念先讲起 ...
随机推荐
- POJ 2689 筛法求素数
DES:给出一个区间[L, U].找出这个区间内相邻的距离最近的两个素数和距离最远的两个素数.其中1<=L<U<=2147483647 区间长度不超过1000000. 思路:因为给出 ...
- mysql迁移oracle
有很多应用项目, 刚起步的时候用MYSQL数据库基本上能实现各种功能需求,随着应用用户的增多,数据量的增加,MYSQL渐渐地出现不堪重负的情况:连接很慢甚至宕机,于是就有把数据从MYSQL迁到Orac ...
- 如何处理HTML5新标签的兼容性问题
支持HTML5新标签: * IE8/IE7/IE6支持通过document.createElement方法产生的标签, 可以利用这一特性让这些浏览器支持HTML5新标签, 浏览器支持新标签后,还需要添 ...
- 在jenkins和sonar中集成jacoco(四)--在sonar中集成jacoco
首先要得到之前的单元测试和集成测试的覆盖率文件,还有对应的class文件以及单元测试的覆盖率报告,材料准备齐全之后,使用如下命令: build.xml 1 2 3 4 5 6 7 8 9 10 11 ...
- timer Compliant Controller project (4)layout and gerber, paning
1 LAYOUT 2 Gerber 3 CAM350-Paining
- 关于protel 99se 汉化后某些菜单消失的解决方法
本人在使用protel 99se 画PCB时,遇到了好些问题,通过网上查资料基本都解决了. 下面给大家分享 关于protel 99se 汉化后某些菜单消失的解决方法. 其他的许多看不见的菜单也可以自己 ...
- 转:Android-apt
转自http://blog.csdn.net/zjbpku/article/details/22976291 What is this? The Android-apt plugin assists ...
- 第8课 goto和void分析
遭人遗弃的goto: C语言是一种面向过程的结构化语言,其中主要结构有三种,顺序执行.选择执行.循环执行.再复杂的程序也是由这三种结构组合而成的. goto破坏了结构化特性,使程序以第四种方式执行,结 ...
- 使用cmd命令打开文件夹
在命令行中输入你想要打开文件所在的磁盘,这里我以打开E:\homework\1.jpg来给大家做示范.在命令行中输入 E: 输入后按下enter键.就进入E盘中,效果如图所示! 如果你想要查 ...
- oracle中union和minus的用法【oracle技术】
UNION是将两个或者两个以上的搜索结果集合并在一起!这个合并是有条件滴!记录的类型要匹配啦,记录的列数要一样啦!看看下面简单的例子: 有的朋友会说为什么要用union呢,直接用txt3 in ('I ...