H01-Linux系统中搭建Hadoop和Spark集群
前言
1.操作系统:Centos7
2.安装时使用的是root用户。也可以用其他非root用户,非root的话要注意操作时的权限问题。
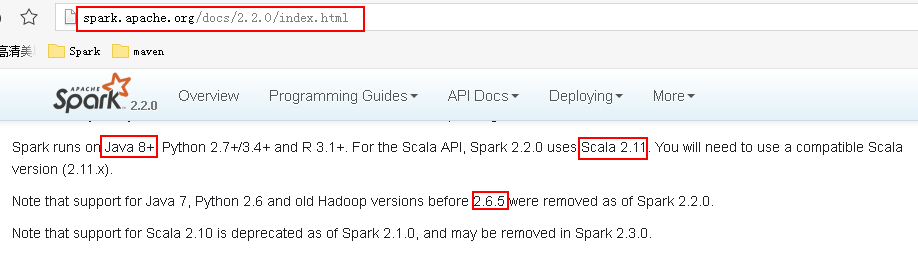
3.安装的Hadoop版本是2.6.5,Spark版本是2.2.0,Scala的版本是2.11.8。
如果安装的Spark要同Hadoop搭配工作,则需注意他们之间的版本依赖关系。可以从Spark官网上查询到Spark运行需要的环境,如下:
4.需要的安装包:

安装包下载地址:
JDK: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Hadoop2.6.5:http://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/
Scala2.11.8:https://www.scala-lang.org/download/all.html
Spark2.2.0:http://archive.apache.org/dist/spark/spark-2.2.0/
1.基础环境配置
1.1集群规划:
|
服务器 |
进程 |
||||||||
|
Hostname |
IP |
配置 |
Namenode |
SecondaryNamenode |
Datanode |
ResourceManager |
NodeManager |
Master |
Worker |
|
Hadoop1 |
192.168.137.21 |
1G内存、1核 |
√ |
√ |
|
√ |
|
√ |
|
|
Hadoop2 |
192.168.137.22 |
1G内存、1核 |
|
|
√ |
|
√ |
|
√ |
|
Hadoop3 |
192.168.137.23 |
1G内存、1核 |
|
|
√ |
|
√ |
|
√ |
注:因为我自己的笔记本配置并不高,所以这里给每台虚拟机分配的资源都很少,可以的话应尽量分配多一点的资源。
1.2所有节点都增加ip和机器名称的映射关系,且3个节点可以相互ping通。
命令:
vim /etc/hosts
在文件中加入如下内容
192.168.137.21 hadoop1
192.168.137.22 hadoop2
192.168.137.23 hadoop3
如下:

1.3所有节点关闭防火墙
查看防火墙状态:
systemctl status firewalld
关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
如下:

注:如果你的系统是6.5,则参考该博文《centOS 6.5关闭防火墙步骤》来关闭防火墙。
1.4 SSH免密登录设置
SSH免密登录设置参考《L07-Linux配置ssh免密远程登录》
通过配置,使得hadoop1、hadoop2、和hadoop3之间都可以相互免密登录(至少要使得hadoop1可以免密登录hadoop2和hadoop3)。
1.5配置NTP
这一步在测试环境中可有可无。生产环境的话,毕竟集群之间需要协同工作,几个节点之间的时间同步还是比较重要的。
集群中配置NTP可参考《L01-RHEL6.5中部署NTP(ntp server + client)》
1.6配置JDK(所有节点)
JDK的配置可参考《L02-RHEL6.5环境中安装JDK1.8》
如下:

注:到这一步,基础环境算是配置好了,这时可以给各个节点做个快照,后面步骤出错了也可以快速恢复。
2.安装Hadoop
下面的2.1~2.2的步骤在所有节点上都要如此操作。我们先在hadoop1上做这些操作,然后在2.3步用scp命令将配置好的hadoop文件发送到hadoop2、hadoop3节点。
2.1解压安装包到/usr/local/目录下(hadoop1上操作)
命令:
cd /data/soft
tar -xvf hadoop-2.6.5.tar.gz -C /usr/local/
如下:

2.2进入到/usr/local/hadoop-2.6.5/etc/hadoop目录下,修改配置文件。(hadoop1上操作)
2.2.1配置hadoop-env.sh
命令:
vim hadoop-env.sh
在hadoop-env.sh中修改JAVA_HOME
export JAVA_HOME=/usr/local/jdk
如下:

注:需根据实际java路径进行修改
2.2.2配置core-site.xml
命令:
vim core-site.xml
在文件中加入如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
如下:

注:该文件的这项配置其实就是指定了NameNode所在的节点
2.2.3配置hdfs-site.xml
命令:
vim hdfs-site.xml
在文件中加入如下内容
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
如下:

注:该文件其实也可以保持默认,其他个性化操作比如有:
<property>
<name>dfs.namenode.name.dir</name>
<value> /bigdata/dfs/name</value>
<description>需要创建相应的/bigdata/dfs/name目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value> /bigdata/dfs/data</value>
<description>需要创建相应的/bigdata/data/name目录</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
2.2.4配置yarn-site.xml
命令:
vim yarn-site.xml
在文件中添加如下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
如下:

注:
可以看到上面有许多端口的配置,网上很多文章的教程中是没有的,这是因为这些端口默认就是8032、8031这样,感觉没有必要显式地再次配置。
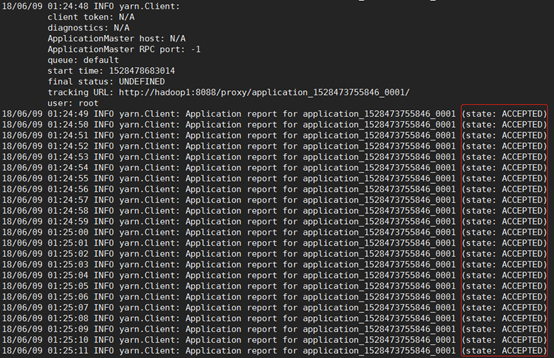
最开始我也没配,结果出错了,出错的情形表现为:通过主节点可以启动yarn集群,子节点上有NodeManager进程,但是,在http://192.168.137.22:8088/cluster/nodes页面却没有显示子节点的信息,同时在主节点上通过yarn node -list -all命令查看也没有子节点的信息。然后在nodemanager节点的相关日志日志文件里(/usr/local/hadoop-2.6.5/logs/yarn-root-nodemanager-hadoop2.log)有org.apache.hadoop.ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8031异常,如下图一所示。我的理解是,因为在yarn-site.xml文件中没有显式地将这些端口配置出来的原因,导致子节点无法向主节点注册(Registered)——然后,从报错的信息看貌似是只要把8031端口配置上了就可以了,其实也不是so easy的……如果不配置其他端口,则提交spark-on-yarn任务的时候会无限地卡在ACCEPTED状态上,卡在该状态上的日志我看不出问题来,但是确实把上面的端口都配置了之后就好了。
因此,最好是将这些端口都显式配置好!!!
图一:

注:判定上图信息是异常的原因,是因为子节点要去连接主节点,它需要连接到正确的主节点IP才行,而上图中连接的却是0.0.0.0——在子节点上,0.0.0.0的IP代表的是子节点自己,它连接错了,自然无法向主节点注册。
关于最后两项配置
yarn.nodemanager.pmem-check-enabled:是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true;
yarn.nodemanager.vmem-check-enabled:是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
因为我实验时给3台机器分配的资源都很少,所以必须得设置它们都为false,否则运行yarn程序的时候会报如下错误。

报错是因为,执行程序时,yarn对于机器能分配的资源进行了检查,结果发现运行程序需要的资源超出了机器所能分配资源的上限,然后就粗错了。如果把上面两项设置为false,则运行程序时就不会去进行对应的资源检查了,此时虽然机器能分配的资源依然不足,但是yarn不会像之前那样立马把container干掉了,而是会花较长的时间才能把程序跑完。
2.2.5配置mapred-site.xml
命令:
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
文件中加入如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
注:这里指定运行mapreduce程序时使用yarn作为资源调度器。
若运行mapreduce程序时不需要以yarn作为资源调度器的话也可以不配置此项,不会出错,也不会影响Spark以spark-on-yarn模式运行spark程序。
2.2.6配置slaves
命令:
vim slaves
在文件中加入如下内容
hadoop2
hadoop3
如下:

注:本次配置中hadoop1是管理节点,hadoop2和hadoop3是数据节点。如果如果想使得hadoop1既是管理节点又是数据节点,可以把hadoop1也写到slaves文件中来。
2.3将hadoop1上配置好的hadoop文件分发到hadoop2和hadoop3节点上(hadoop1上操作)
命令:
scp -r /usr/local/hadoop-2.6.5 root@hadoop2:/usr/local/
scp -r /usr/local/hadoop-2.6.5 root@hadoop3:/usr/local/
2.4修改环境变量,在hadoop1上执行以下命令
命令:
vim /etc/profile
在文件中添加如下内容:
export HADOOP_HOME=/usr/local/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

用source /etc/profile命令使修改的环境变量生效,接着用which hdfs命令查看是否修改成功。

2.5配置完成,接着格式化hdfs
在主节点hadoop1上执行以下命令
hdfs namenode -format
如下:
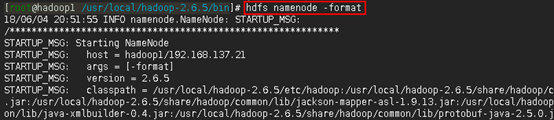

注:命令执行完之后从结果上很难看出是否格式化成功了,这时可以紧接着通过echo $? 命令查看hdfs namenode -format命令是否执行成功。如果输出0,则说明上一条执行成功,如上图所示。
2.6启动hdfs,在hadoop1上执行以下命令
cd /usr/local/hadoop-2.6.5/sbin
./start-dfs.sh
如下:
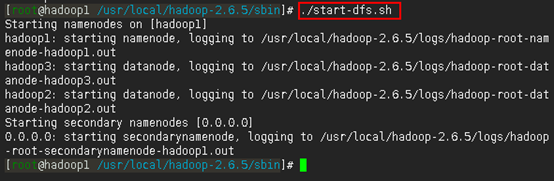
注:从输出信息中可以看出,启动hdfs时,先启动NameNode,然后启动DataNode,最后才启动Secondary NameNode。
2.7验证hdfs是否启动成功
方法一:
在主节点hadoop1上用jps命令查看是否存在SecondaryNameNode和NameNode进程:

在任一子节点上用jps命令可以查是否存在DataNode进程

由上面两张图的查询结果可知,在相应节点上可以查看到相应的SecondaryNameNode、NameNode和DataNode进程。如此,可以认为,从主节点上可以成功启动hdfs集群了。
但是是否一定没有问题了呢?不一定。
我们知道,hadoop集群启动成功之后,子节点会定时向主节点发送心跳信息,主节点以此判断子节点的状态。所以,有时即使我们通过主节点启动hadoop集群成功了,使用jps命令也能查询到相应的SecondaryNameNode、NameNode和DataNode进程——但如果由于某些原因,比如某个子节点的某个配置配错了,如我搭建时的情况是子节点的core-site.xml文件中fs.defaultFS项配置错了,或者是由于防火墙的原因,又或者是由于前面格式化次数太多了出问题导致子节点的cluster_id跟主节点的cluster_id不一致——导致子节点无法向主节点发送心跳信息,那么对主节点来说,该子节点就是dead的了。关于启动hdfs可能出现的几个问题,可参考《H02-启动hdfs时可能遇到的几个问题》。
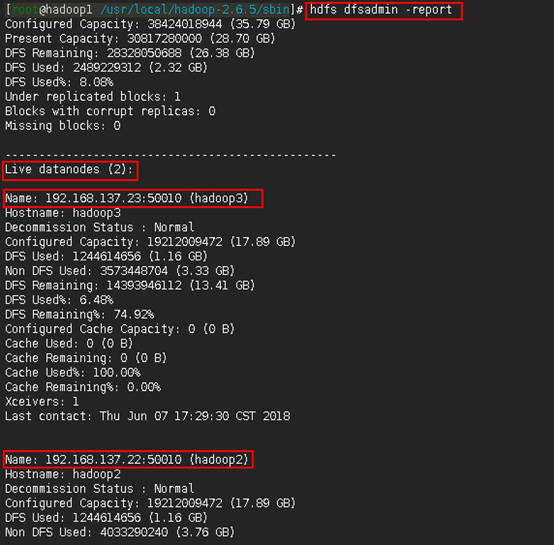
于是,作为进一步验证的方法,是在主节点上使用hdfs dfsadmin -report来观察集群配置情况。如下:
方法二:
通过本地浏览器查看192.168.137.21:50070,验证否部署成功
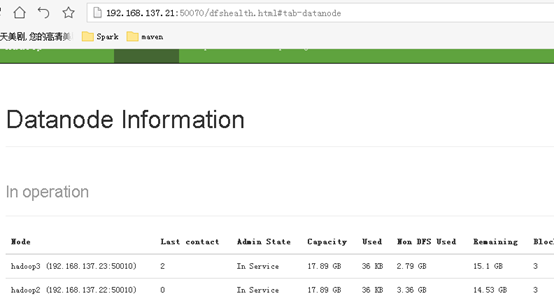
注:一定要在页面看到所有子节点信息才算hdfs集群没有问题。
2.8启动yarn,在hadoop1上执行以下命令
cd /usr/local/hadoop-2.6.5/sbin
./start-yarn.sh
如下:

2.9验证yarn是否启动成功
方法一:
在主节点上用jps命令查看是否有ResourceManager进程

在子节点上用jps命令查看是否有NodeManager进程

由上面两张图可以看到相应的ResourceManager和NodeManager进程已经启动起来了。
但是,同样还不能认为yarn集群就没有问题了,原因如2.2.4中所说的那样(即:可能由于某些原因,导致子节点在启动之后却无法向主节点注册)。
因此,保险起见,应在主节点上再通过yarn node -list -all命令查看一下。如下:

如上图所示,说明yarn启动成功。
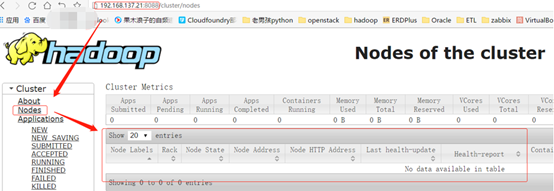
如果像下图一那样,说明yarn集群是有问题的——这种时候如果提交了以yarn作为资源调度器的Spark任务,则任务会永远卡在ACCEPTED状态(如下图二),这是因为此时yarn集群只剩下ResourceManager这个光杆司令了,没有资源可以给它调度,所以它会一直卡在分配资源的状态下,要命的是它会一直很顽强地不断地努力尝试分配资源,还不报错......
图一:

图二:
方法二:
通过本地浏览器访问192.168.137.21:8088,查看yarn是否正常工作
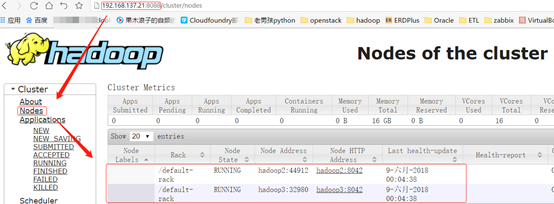
如上图,在页面上能看到子节点的信息,说明yarn集群没有问题。如果像下图这样,说明你的yarn集群是有问题的。
2.10 hadoop集群验证
经过前面的步骤,简单的hadoop集群已经搭建完毕,接下来利用hadoop自带的jar包执行一个wordcount的mapreduce程序进行验证。
(1)首先在linux系统中有一个hello.txt文件,文件的内容如下所示

(2)接下来在hdfs中新建一个目录input,然后将hello.txt上传到该目录下
命令:
hadoop fs -mkdir /input
hadoop fs -put /data/my_jar/hello.txt /input
使用hadoop fs -ls -R /input命令可以看到已经将hello.txt文件放到hdfs上了

使用hadoop fs -text /input/hello.txt命令可以看到hdfs中hello.txt文件的内容

(3)输入已经准备好了。接下来使用以下命令执行wordcount例子程序。
命令:
hadoop jar /usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /input /output
注:
(1)由于我们前面已经配置mapred-site.xml文件使得mapreduce程序使用yarn作为资源调度器,因此在执行命令时,可以在http://192.168.137.21:8088/cluster/apps页面上看到相应的application信息。
(2)该命令使用的是hadoop自带的jar包:/usr/local/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar
(3)注意到到命令的最后两个参数/input和/output——程序将读取hdfs中的/input目录下的文件作为输入,最后将运算结果保存在hdfs的/output目录下。
(4)注意执行命令前需保证/output目录不存在,否则将会报错。
如下:

注:由上图的Connecting to ResourceManager at hadoop1/192.168.137.21:8032可以看出此次运行的mapreduce程序使用yarn作为资源调度器。
在yarn的http://192.168.137.21:8088/cluster/apps页面上可以看到相应的application信息(下图的第二个application):
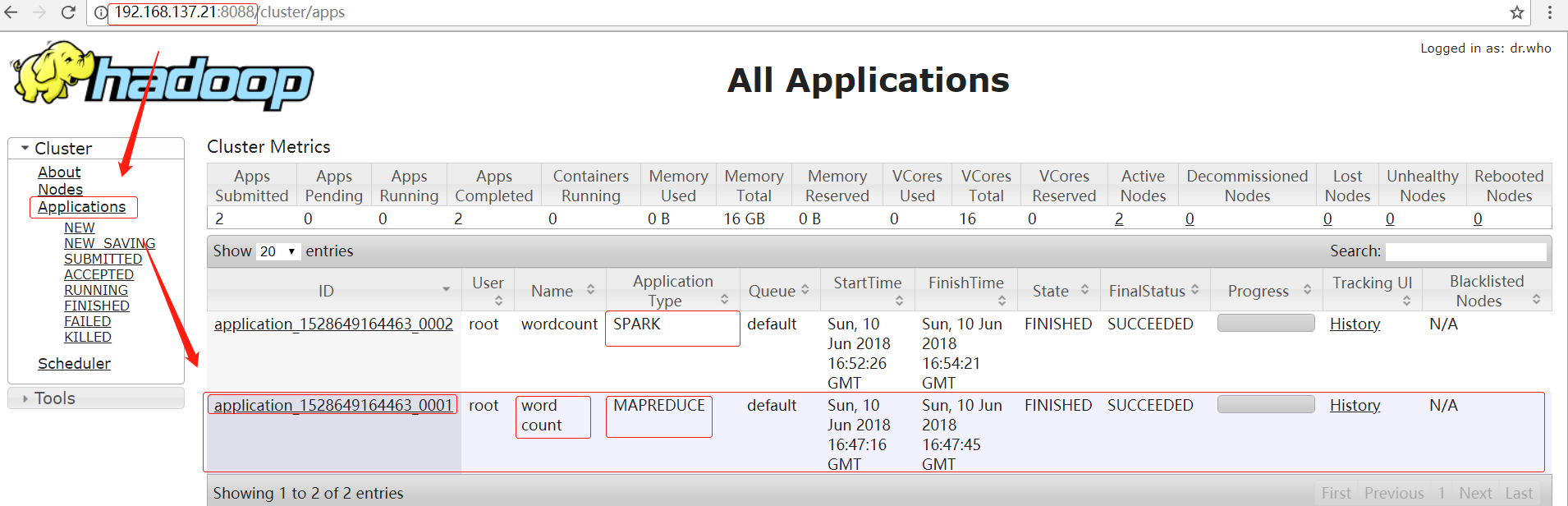
注:由图中的Application Type可以看出这里跑的是mapreduce程序,如果是以spark-on-yarn模式跑的Spark程序,则这里的显示会是SPARK,如上图的第一个application所示。
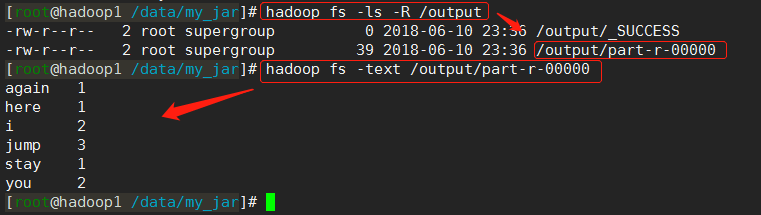
(4)查看输出
由命令我们知道,该mapreduce程序将运算结果保存在了/output目录下
命令:
hadoop fs -ls -R /output
hadoop fs -text /output/part-r-00000
如下:
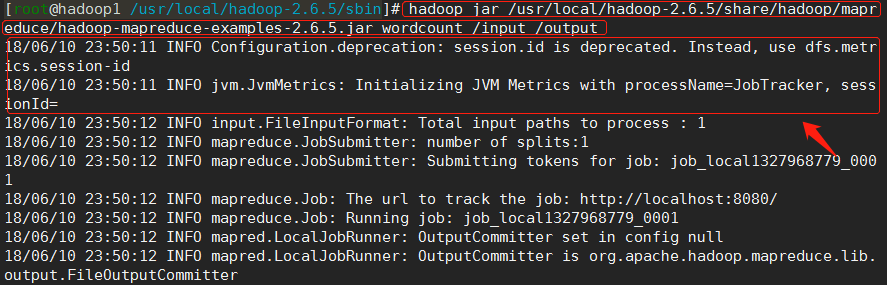
(5)刚才跑的mapreduce程序是用yarn来做资源调度的,而该程序之所以会以yarn作为资源调度器,是因为前面在第2.2.5步骤中配置了mapred-site.xml,指定mapreduce程序运行时以yarn作为资源调度器。
倘若在2.2.5步中没有如此指定,则mapreduce程序照样可以运行,如下图所示。
不过此时的mapreduce程序就不是以yarn作为资源调度器了,并且这时候yarn甚至都可以不启动。
3.安装Spark
Spark的安装跟hadoop(包括yarn)是相对独立的,即使是需要以spark-on-yarn模式运行Spark程序。Spark和hadoop的关系,不像hadoop和jdk之间的关系那样——安装hadoop之前必须配置好jdk,但安装Spark之前并不必须得先安装hadoop。
Spark和hadoop的关系,更像是你和楼下饭店的关系,当你自己做饭吃的时候,楼下饭店存不存在是与你无关的;只有当你不自己做饭了,你才需要楼下有家饭店。拿Spark来说,就是:如果只是需要以local或者standalone模式运行Spark程序,那么集群中有没有安装hadoop都无关紧要;只有当Spark程序需要以spark-on-yarn模式运行或者需要读取hdfs中的文件时,它才需要hadoop的存在。所以如果没有以spark-on-yarn模式运行Spark程序的需求的话,可以不安装第2步中的hadoop环境,不过第1步的基础环境还是需要配置的。——这是我初学Spark时一直迷糊的一个点,希望这里说明清楚了。
3.1安装Scala
关于安装Spark之前要不要安装scala?其实我也不确定。有教程说不用安装,因为Spark安装包中自带scala了。也有的教程说需要先安装scala。
对于我来说,首先因为安装scala也没多难,其次后期我还要用scala来开发Spark程序,所以也就安装了。
不管怎样,安装步骤如下。
3.1.1用root用户解压scala安装包到/usr/local目录下(hadoop1上操作)
命令:
cd /data/soft
tar -xvf scala-2.11.8.tgz -C /usr/local/
3.1.2将解压后的scala目录拷贝到hadoop2和hadoop3(hadoop1上操作)
命令:
scp -r /usr/local/scala-2.11.8 root@hadoop2:/usr/local/
scp -r /usr/local/scala-2.11.8 root@hadoop3:/usr/local/
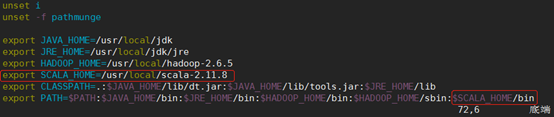
3.1.3分别在三台虚拟机上修改环境变量:
命令:
vi /etc/profile
加入如下内容
export SCALA_HOME=/usr/local/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
如下:
3.1.4使修改的环境变量生效
命令:
source /etc/profile
接着用which scala命令查看scala的安装目录是不是我们想要的

3.1.5测试是否安装成功
命令:
scala
或者
scala -version

3.2安装Spark(hadoop1上操作)
3.2.1解压Spark安装包到/usr/local/目录下
命令:
cd /data/soft
tar -xvf spark-2.2.0-bin-hadoop2.6.tgz -C /usr/local/
3.2.2参数配置
3.2.2.1配置slaves
命令:
cd /usr/local/spark-2.2.0-bin-hadoop2.6/conf
cp slaves.template slaves
vim slaves
写入如下内容
hadoop2
hadoop3
如下:

3.2.2.2配置spark-env.sh
命令:
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
在文件中加入以下内容:
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_HOST=hadoop1
export SPARK_MASTER_PORT=7077
如下:

注:
1) JAVA_HOME是一定要配置的
2) 配置HADOOP_HOME和HADOOP_CONF_DIR是因为,之后我需要以spark-on-yarn模式运行Spark程序,配置HADOOP_CONF_DIR才能使得Spark可以找到正确的hadoop环境,否则每次以spark-on-yarn模式运行Spark程序时都需要手动export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.5/etc/hadoop才行。如果只想以local或standalone模式运行Spark程序,则这两项可以不配置。
3) 至于SPARK_MASTER_HOST和SPARK_MASTER_PORT,感觉没有必要显式地配置,因为人家使用默认值也是没有问题的,但是我还是配上了,不配置的话会不会有问题我就不知道了。
3.2.3将配置好的spark文件拷贝到hadoop2和hadoop3节点上
命令:
scp -r /usr/local/spark-2.2.0-bin-hadoop2.6 root@hadoop2:/usr/local/
scp -r /usr/local/spark-2.2.0-bin-hadoop2.6 root@hadoop3:/usr/local/
3.2.4在hadoop1节点上配置环境变量
命令:
vim /etc/profile
在文件中加入以下内容:
export SPARK_HOME=/usr/local/spark-2.2.0-bin-hadoop2.6
export PATH=$PATH: ${SPARK_HOME}/bin
如下:
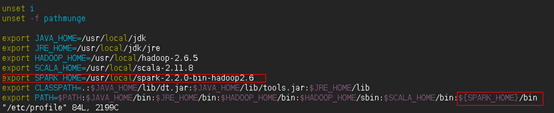
注:这里之所以没有在PATH中加入${SPARK_HOME}/sbin,是因为该目录和$HADOOP_HOME/sbin目录下都存在start-all.sh和stop-all.sh脚本,如果在PATH中加入${SPARK_HOME}/sbin,当然也是没有问题的,但是有可能会产生误操作(有时候你想关闭Spark集群,于是在任意位置执行stop-all.sh命令,极有可能就把hadoop集群给关咯),所以为了避免这种情况,干脆不配置了,当要执行start-all.sh和stop-all.sh时再手动切换到${SPARK_HOME}/sbin目录下去执行即可。
使修改的环境变量生效:
source /etc/profile
3.2.5启动spark集群
命令:
cd /usr/local/spark-2.2.0-bin-hadoop2.6/sbin
./start-all.sh
如下:

3.2.6 通过网页192.168.137.21:8080查看是否成功
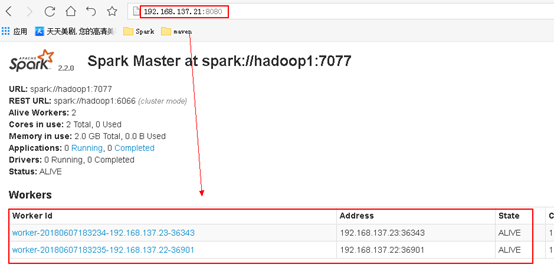
注:同样也是要在页面上看到所有的Woker子节点的信息才算是成功了。
3.3运行spark程序测试
安装完Spark之后,应该测试一下安装的Spark在local模式、standalone模式和spark-on-yarn模式下是否等能成功运行程序。
对于安装的Spark集群,有必要测试一下Spark程序是否可以以standalone模式运行。
倘若以后需要以spark-on-yarn模式进行开发,则spark-on-yarn模式的测试也非常有必要,因为有的时候虽然yarn集群启动成功了,但是由于yarn默认参数配置不一定适合你当时的集群硬件配置,极有可能是有问题的,只有跑一个程序测试一下才能试出问题来。
Spark中也自带了测试例子,测试方式参考:https://blog.csdn.net/pucao_cug/article/details/72453382
至此,配置完成
H01-Linux系统中搭建Hadoop和Spark集群的更多相关文章
- AWS EC2 搭建 Hadoop 和 Spark 集群
前言 本篇演示如何使用 AWS EC2 云服务搭建集群.当然在只有一台计算机的情况下搭建完全分布式集群,还有另外几种方法:一种是本地搭建多台虚拟机,好处是免费易操控,坏处是虚拟机对宿主机配置要求较高, ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
- Docker中提交任务到Spark集群
1. 背景描述和需求 数据分析程序部署在Docker中,有一些分析计算需要使用Spark计算,需要把任务提交到Spark集群计算. 接收程序部署在Docker中,主机不在Hadoop集群上.与Spa ...
- Linux系统下安装Redis和Redis集群配置
Linux系统下安装Redis和Redis集群配置 一. 下载.安装.配置环境: 1.1.>官网下载地址: https://redis.io/download (本人下载的是3.2.8版本:re ...
- 用三台虚拟机搭建Hadoop全分布集群
用三台虚拟机搭建Hadoop全分布集群 所有的软件都装在/home/software下 虚拟机系统:centos6.5 jdk版本:1.8.0_181 zookeeper版本:3.4.7 hadoop ...
- CentOS中搭建Redis伪分布式集群【转】
解压redis 先到官网https://redis.io/下载redis安装包,然后在CentOS操作系统中解压该安装包: tar -zxvf redis-3.2.9.tar.gz 编译redis c ...
- Hadoop、Spark 集群环境搭建问题汇总
Hadoop 问题1: Hadoop Slave节点 NodeManager 无法启动 解决方法: yarn-site.xml reducer取数据的方式是mapreduce_shuffle 问题2: ...
随机推荐
- SFTP 安装与配置
SFTP 安装与配置 sftp 是 Secure File Transfer Protocol 的缩写,安全文件传送协议.可以为传输文件提供一种安全的加密方法.SFTP 为 SSH 的一部分,由于这种 ...
- 关于流程图设计,你需要Get的几点必备知识
流程图(Flow Chart)这个概念对很多人来说并不陌生,但如果让你定义或者举例说明什么是产品流程图,恐怕还是有难度的.或许诸如“用户体验”.“交互设计”.“逻辑关系”等词会像走马灯般闪现在你的脑海 ...
- http://angular.github.io/router/
Angular New Router Guide Configuring the Router- This guide shows the many ways to map URLs to compo ...
- 16 Finding a Protein Motif
Problem To allow for the presence of its varying forms, a protein motif is represented by a shorthan ...
- BASE64Encoder及BASE64Decoder编译器找不到问题
编译器自带这两个类,但是会报错找不到,需要手动让编译器识别这个类 第一步.右键项目,然后选择properties 第二步,打开如图位置 第三部,选择如图位置,双击 第四部,add添加 更改值 改为如图 ...
- context:propertyPlaceholder
Activates replacement of ${...} placeholders by registering a PropertySourcesPlaceholderConfigurer w ...
- Appium之手机屏幕亮度控制条处理
手机设置下的屏幕亮度控制条看上去是悬浮的,想手动调整亮度有两种方法:一.在控制条上左右任意拖动:二.在控制条上点击任意一点.如下图:
- [label][Chrome-Extension] How to start Chrome Extension's development
Firstly , you should read these two pages. https://developer.chrome.com/extensions/overview https:/ ...
- [label][git-commands] Several Git Commands
The process of Git commands Operation 1. git commit -m 'fist post' Windows PowerShellCopyright (C) 2 ...
- Android-应用安装/替换/卸载/广播监听
在上一篇博客Android-开关机的广播,中介绍了,如何订阅接收者,去接收系统发送的开机/关机广播, 而这篇博客是订阅接收者 去接收应用的(安装/替换/卸载) 三种广播 订阅 接收者 去接收 应用的 ...