在pycharm中使用scrapy爬虫
目标在Win7上建立一个Scrapy爬虫项目,以及对其进行基本操作。运行环境:电脑上已经安装了python(环境变量path已经设置好),
以及scrapy模块,IDE为Pycharm 。操作如下:
一、建立Scrapy模板。进入自己的工作目录,shift + 鼠标右键进入命令行模式,在命令行模式下,
输入scrapy startproject 项目名 ,如下:

看到以上的代码说明项目已经在工作目录中建好了。
二、在Pycharm中scrapy的导入。在Pycharm中打开工作目录中的TestDemo,点击File-> Settings->Project: TestDemo->Project Interpreter。
法一: 如图,
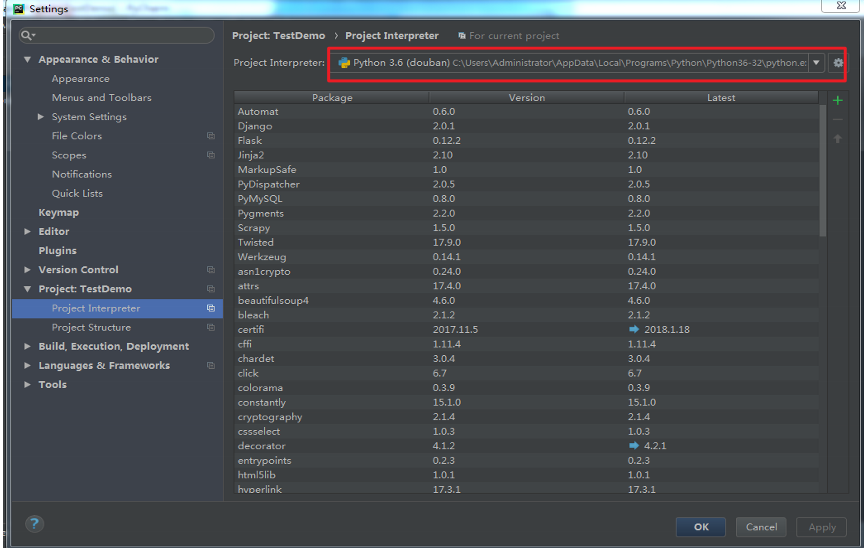
选择红框中右边的下拉菜单点击Show All, 如图:
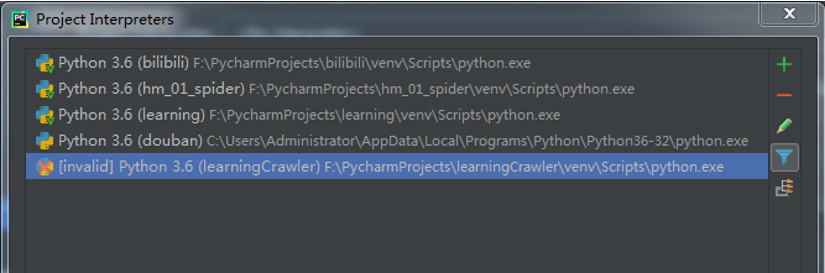
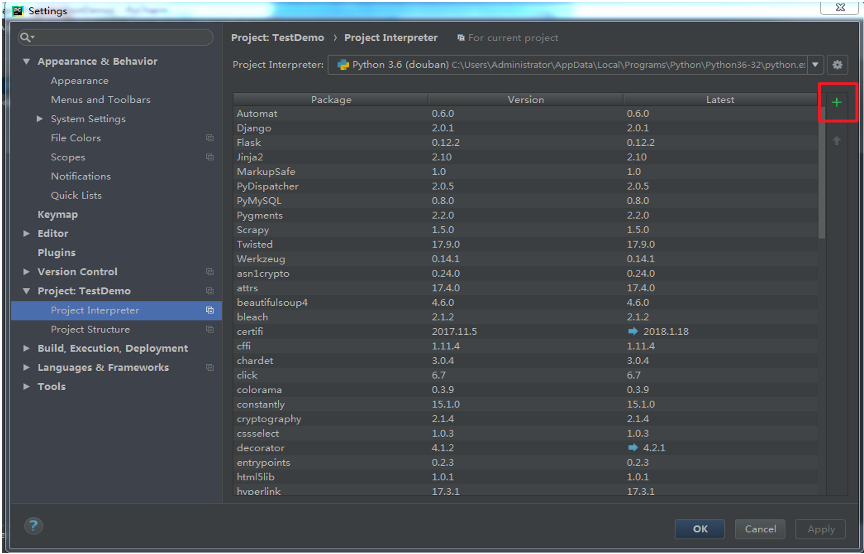
点击右上角加号,如图:
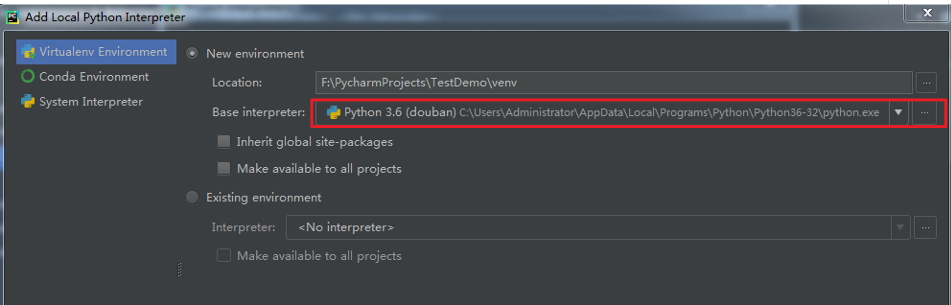
在红色框体内找到电脑里已经安装的python,比如我的是:
C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32\python.exe , 导入即可。
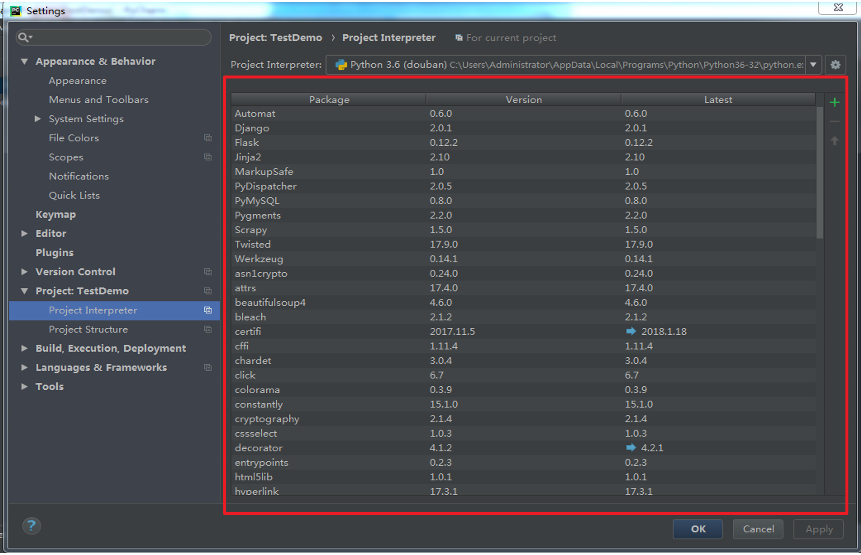
之后,pycharm会自动导入你已经在电脑上安装的scrapy等模块。如图,即红色框体中显示的。
法二:一个不那么麻烦的方法。如图:
点击红色框体,在弹出的框体内另安装一个scrapy, 如图:

需要安装的模块,如图:

模块自下而上进行安装,其中可能出现twisted包不能成功安装,出现
Failed building wheel for Twisted
Microsoft Visual C++ 14.0 is required...
的现象,那就搜一解决方案,这里不多说了。
三、Pycharm中scrapy的运行设置。
Tips:在创建爬虫时使用模板更加方便一些,如:
scrapy genspider [-t template] <name> <domain> 即:scrapy genspider testDemoSpider baidu.com
运行爬虫:
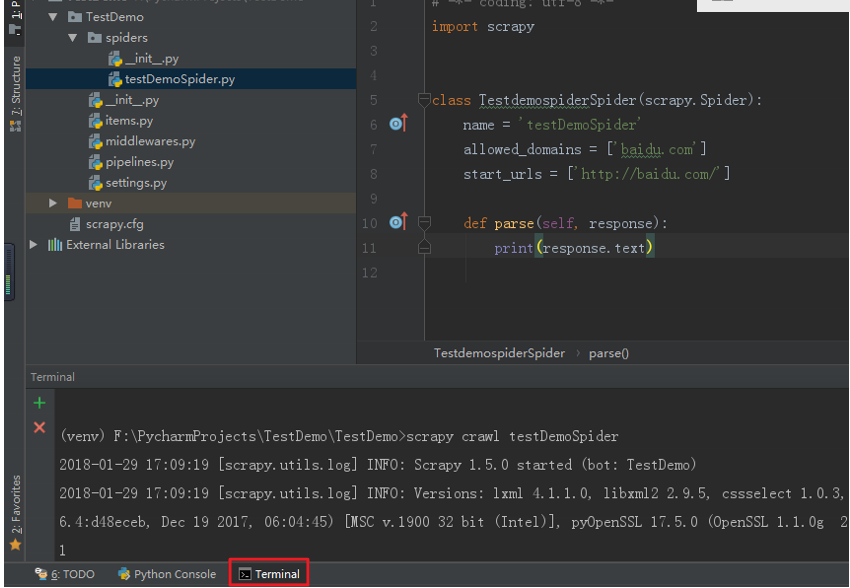
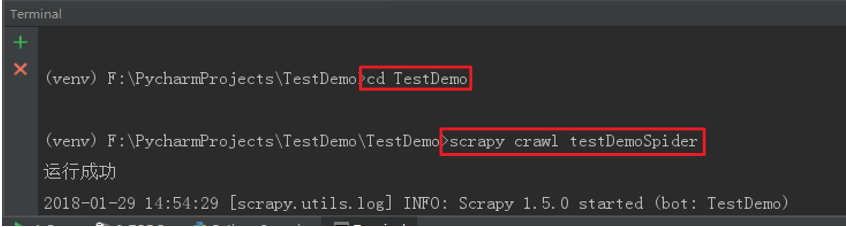
法一:Scrapy爬虫的运行需要到命令行下运行,在pychram中左下角有个Terminal,点开就可以在Pycharm下进入命令行,默认
是在项目目录下的,要运行项目,需要进入下一层目录,使用cd TestDemo 进入下一层目录,然后用scrapy crawl 爬虫名 , 即可运行爬虫。
如图:
法二:在TestDemoSpider目录和scrapy.cfg同级目录下面,新建一个entrypoint.py文件,如图:
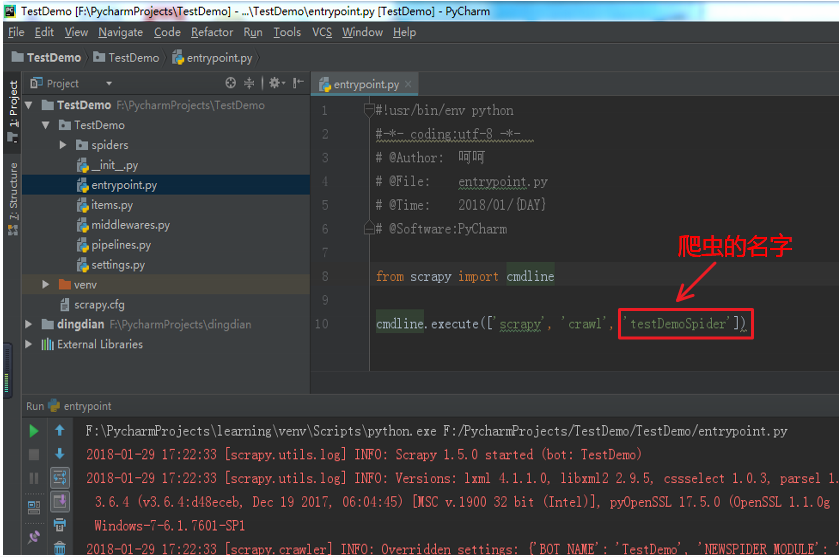
其中只需把红色框体内的内容改成相应的爬虫的名字就可以在不同的爬虫项目中使用了,直接运行该文件就能使得Scrapy爬虫运行
在pycharm中使用scrapy爬虫的更多相关文章
- 在Pycharm中运行Scrapy爬虫项目的基本操作
目标在Win7上建立一个Scrapy爬虫项目,以及对其进行基本操作.运行环境:电脑上已经安装了python(环境变量path已经设置好), 以及scrapy模块,IDE为Pycharm .操作如下: ...
- win10在Pycharm中安装scrapy
查看官网说明 发现推荐是安装Anaconda 或 Miniconda,这东西有点大而全,感觉目前用不上.所以没这样做. 直接安装scrapy 如果直接装会报错的,参考文章就可以解决. 这里记一下组件下 ...
- Pycharm中的scrapy安装教程
在利用pycharm安装scrapy包是遇到了挺多的问题.在折腾了差不多折腾了两个小时之后总算是安装好了.期间各种谷歌和百度,发现所有的教程都是利用命令行窗口安装的.发现安装scrapy需要的包真是多 ...
- 用Scrapy爬虫下载图片(豆瓣电影图片)
用Scrapy爬虫的安装和入门教程,这里有,这篇链接的博客也是我这篇博客的基础. 其实我完全可以直接在上面那篇博客中的代码中直接加入我要下载图片的部分代码的,但是由于上述博客中的代码已运行,已爬到快九 ...
- #0 scrapy爬虫学习中遇到的坑记录
python 基础学习中对于scrapy的使用遇到了一些问题. 首先进行的是对Amazon.cn的检索结果页进行爬取,很顺利,无碍. 下一个目标是对baidu的搜索结果进行爬取 1,反爬虫 1.1 我 ...
- 如何在vscode中调试python scrapy爬虫
本文环境为 Win10 64bit+VS Code+Python3.6,步骤简单罗列下,此方法可以不用单独建一个Py入口来调用命令行 安装Python,从官网下载,过程略,这里主要注意将python目 ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- scrapy爬虫,cmd中执行日志中显示了爬取的内容,但是运行时隐藏日志后(运行命令后添加--nolog),就没有输出结果了
cmd下执行scrapy爬虫程序,不报错也没有输出,解决方案 想要执行parse能够在cmd看到parse函数的执行结果: 解决方法: settings.py 中设置 ROBOTSTXT_OBEY ...
- 【Python】在Pycharm中安装爬虫库requests , BeautifulSoup , lxml 的解决方法
BeautifulSoup在学习Python过程中可能需要用到一些爬虫库 例如:requests BeautifulSoup和lxml库 前面的两个库,用Pychram都可以通过 File--> ...
随机推荐
- django中的auth详解
Auth模块是什么 Auth模块是Django自带的用户认证模块: 我们在开发一个网站的时候,无可避免的需要设计实现网站的用户系统.此时我们需要实现包括用户注册.用户登录.用户认证.注销.修改密码等 ...
- grpc 入门(二)-- 服务接口类型
本节是继上一章节Hello world的进一步深入挖掘; 一.grpc服务接口类型 在godoc的网站上对grpc的端口类型进行了简单的介绍,总共有下面4种类型[1]: gRPC lets you d ...
- LIS(单调队列优化 C++ 版)(施工ing)
#include <iostream> using namespace std; #include <cstdio> ; ,x,stack[MaxN]; int main(){ ...
- django无法加载样式
如果运行的环境是win10,那么首先应该考虑是否是如下问题 win10中Django后台admin无法加载CSS等样式 解决: 修改win10的注册表:[win+R输入Regedit] 因为你安装的某 ...
- 20155207 《Java程序设计》实验报告二:Java面向对象程序设计
实验要求 1.初步掌握单元测试和TDD 2.理解并掌握面向对象三要素:封装.继承.多态 3.初步掌握UML建模 4.熟悉S.O.L.I.D原则 5.了解设计模式 实验内容 一.单元测试 1.三种代码 ...
- pwd命令的实现
pwd 命令描述 Linux中用 pwd 命令来查看"当前工作目录"的完整路径. 简单得说,每当你在终端进行操作时,你都会有一个当前工作目录. 在不太确定当前位置时,就会使用pwd ...
- 20155311 《Java程序设计》实验四 (Android程序设计)实验报告
20155311 <Java程序设计>实验四 (Android程序设计)实验报告 实验内容 基于Android Studio开发简单的Android应用并部署测试; 了解Android.组 ...
- 【笔记学习】Linux系统与虚拟机学习
Part 1 : 基于VirtualBox虚拟机安装Ubuntu 问题剪辑 --给一开始未知的我的科普指南 1. VirtualBox不能创建64位虚拟机 解决办法: 开启虚拟化技术 详细:重启电脑, ...
- PostgreSQL 使用 LDAP 认证方式
磨砺技术珠矶,践行数据之道,追求卓越价值 回到上一级页面: PostgreSQL杂记页 回到顶级页面:PostgreSQL索引页 [作者 高健@博客园 luckyjackgao@gmail. ...
- 【转载】漫谈C++:良好的编程习惯与编程要点
原文: 漫谈C++:良好的编程习惯与编程要点 阅读目录 以良好的方式编写C++ class Class with pointer member(s):记得写Big Three static与类 正文 ...