Python 爬虫 ajax爬取马云爸爸微博内容
ajax爬取情况
有时候我们在用 Requests 抓取页面的时候,得到的结果可能和在浏览器中看到的是不一样的,在浏览器中可以看到正常显示的页面数据,但是使用 Requests 得到的结果并没有,这其中的原因是 Requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是页面又经过 JavaScript 处理数据后生成的结果,这些数据的来源有多种,可能是通过 Ajax 加载的,可能是包含在了 HTML 文档中的,也可能是经过 JavaScript 经过特定算法计算后生成的
项目代码如下
- import requests
- from fake_useragent import UserAgent
- from pyquery import PyQuery
- from urllib.parse import urlencode
- from requests.packages import urllib3
- from pymongo import MongoClient
- # 关闭警告
- urllib3.disable_warnings()
- base_url = 'https://m.weibo.cn/api/container/getIndex?'
- # 激活本地MongoDB客户端
- client = MongoClient('localhost',27001)
- # 创建数据库
- pages = client['pages']
- # 创建集合
- ma_yun = pages['ma_yun']
- # 保存到mongoDB中
- def save_to_mongo(result):
- if ma_yun.insert_one(result):
- print('saved to Mongo','已获取{number}条数据'.format(number=ma_yun.count()))
- # 生成UA
- def create_user_agent():
- ua = UserAgent(use_cache_server=False)
- # print(ua.chrome)
- return ua.chrome
- # 生成headers
- def create_headers():
- headers = {
- 'User-Agent': create_user_agent()
- }
- return headers
- # 获取页面
- def get_page(page):
- # 设置参数
- params = {
- 'sudaref':'germey.gitbooks.io',
- 'display':'',
- 'retcode':'',
- 'type':'uid',
- 'value':'',
- 'containerid':'',
- 'page':page
- }
- url = base_url + urlencode(params)
- try:
- response = requests.get(url,create_headers(),verify=False)
- if response.status_code == 200:
- return response.json()
- except requests.ConnectionError as e:
- print('Error',e.args)
- # 解析页面
- def parse_page(json):
- if json:
- items = json.get('data').get('cards')
- if items != None:
- for item in items:
- item = item.get('mblog')
- weibo = {}
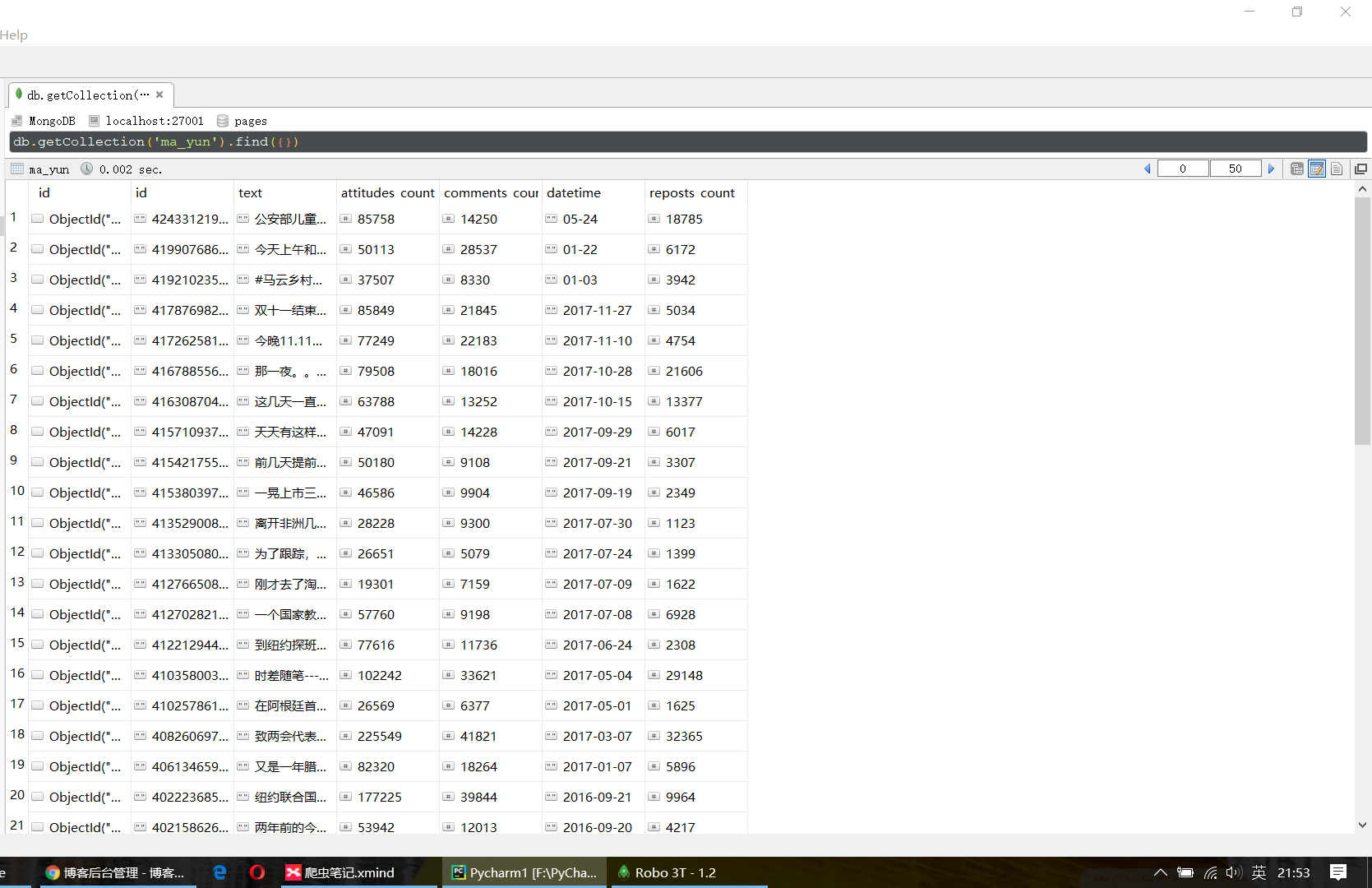
- weibo['id'] = item.get('id')
- # 将正文中的 HTML 标签去除掉
- weibo['text'] = PyQuery(item.get('text')).text()
- # 点赞数
- weibo['attitudes_count'] = item.get('attitudes_count')
- # 评论数
- weibo['comments_count'] = item.get('comments_count')
- # 发布时间
- weibo['datetime'] = item.get('created_at')
- # 转发数
- weibo['reposts_count'] = item.get('reposts_count')
- yield weibo
- # 设置主方法进行调用其他方法
- def main():
- for page in range(1,30):
- json = get_page(page)
- results = parse_page(json)
- for result in results:
- save_to_mongo(result)
- if __name__ == '__main__':
- main()
项目运行情况
Python 爬虫 ajax爬取马云爸爸微博内容的更多相关文章
- python爬虫:爬取读者某一期内容
学会了怎么使用os模块 #!/usr/bin/python# -*- encoding:utf-8 -*- import requestsimport osfrom bs4 import Beauti ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
随机推荐
- ok6410 android driver(1)
target system : Android (OK6410) host system : Debian Wheezy AMD64 1.Set up android system in ok6410 ...
- javac之Method Invocation Expressions
15.12.1. Compile-Time Step 1: Determine Class or Interface to Search 15.12.2. Compile-Time Step 2: D ...
- javaweb 实现跨域
现在的一个web应用会涉及到多个地方的restAPi的调用,传统的jsonp虽然支持跨域,但是只是支持get请求. 传统的ajax请求是不支持跨域的,是为了安全考虑. 跨域的思路是跟http机制有关, ...
- 王亮:游戏AI探索之旅——从alphago到moba游戏
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由云加社区技术沙龙 发表于云+社区专栏 演讲嘉宾:王亮,腾讯AI高级研究员.2013年加入腾讯,从事大数据预测以及游戏AI研发工作.目前 ...
- Object的原型拷贝-create、assign、getPrototypeOf 方法的结合
一.实现原型拷贝 1.1.代码 tips:为了体现原型链,写了继承实现的代码,这部分可跳过- <script> /* 创建包含原型链的实验对象obj1-- start */ ...
- vue中添加Echarts图表的使用,Echarts的学习笔记
项目中需要使用一些折线图.柱状图.饼状图等等,之前使用过heightCharts(关于heightCharts请看我的另一篇 http://www.cnblogs.com/jasonwang2y60/ ...
- 关于Hall定理的学习
基本定义 \(Hall\) 定理是二分图匹配的相关定理 用于判断二分图是否存在完美匹配 存在完美匹配的二分图即满足最大匹配数为 \(min(|X|,|Y|)\) 的二分图,也就是至少有一边的点全部被匹 ...
- html锚点使用示例
<html> <body> <h1>HTML 教程目录</h1> <ul> <li><a href="#C1&q ...
- 从0开始整合SSM框架--3.整合SpringMvc
前面面已经完成了2大框架的整合,SpringMVC的配置文件单独放,然后在web.xml中配置整合.1.配置spring-mvc.xml <beans xmlns="http://ww ...
- 激活 IntelliJ IDEA
1.点击下面的链接下载 JetbrainsIdesCrack-4.2-release.jar 链接:https://pan.baidu.com/s/1eNY_bwxF7Efl4QG0yh6l1A 提 ...