分布式数据库主键id生成策略
分布式数据库部署主要分为两种,一种是读写分离。这个需要弄主从数据库。主要是写的时候写主数据库,读的时候读从数据库。分散读取压力,对于读多写少的系统有利于
提高其性能。还有一种是分布式存储,这种主要是将一张表拆分成多张分表部署到各个服务器中,主要针对写操作频繁的系统,如微博,淘宝的订单系统。
这两种方案都会遇到主键类型及生成方式的问题,还有主从数据库不同步和主键冲突问题。
主键类型主要有GUID和数字类型,这里我们不讨论GUID;
数字主键主要存在唯一性、可同步性两个方面的不足
可同步性:可以不使用主键自增方案。
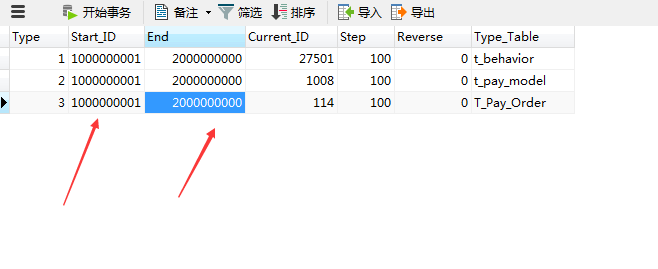
唯一性:可以单独使用存储过程生成ID,设置主键ID的初始值步长和最大值,及所对应的表,当然主从数据库的主表和分表初始值和最大值是不一样的,一样的话会造成主键重复。
存储过程:
- -- ----------------------------
- -- Procedure structure for getId
- -- ----------------------------
- DROP PROCEDURE IF EXISTS `getId`;
- DELIMITER ;;
- CREATE DEFINER=`sawyer`@`%` PROCEDURE `getId`(OUT aId INT, OUT aIdEnd INT, aType TINYINT)
- BEGIN
- DECLARE id,eid,iStep INT;
- DECLARE rev TINYINT;
- SELECT Current_ID,END,Step,REVERSE INTO id,eid,iStep,rev FROM t_id WHERE TYPE=aType;
- IF id<eid THEN
- SET aId = id;
- IF id+iStep >= eid THEN
- SET aIdEnd = eid;
- IF rev = 1 THEN
- UPDATE t_id SET Current_ID=Start_ID WHERE TYPE=aType;
- ELSE
- UPDATE t_id SET Current_ID=eid WHERE TYPE=aType;
- END IF;
- ELSE
- SET aIdEnd = id+iStep;
- UPDATE t_id SET Current_ID=aIdEnd WHERE TYPE=aType;
- END IF;
- ELSE
- SET aId = 0, aIdEnd = 0;
- END IF;
- END
- ;;
- DELIMITER ;
主表
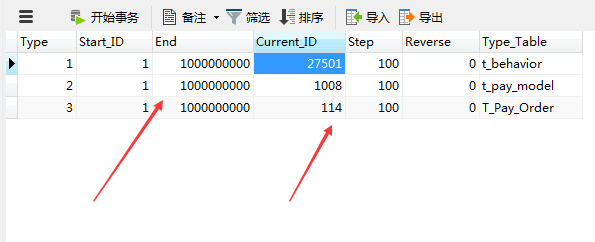
从表
写一个java类去调用这个存储过程生成主键。
- /* */ package btir.dao.jdbc;
- /* */
- /* */ import btir.BtirException;
- /* */ import btir.dao.ha.DBMgr;
- /* */ import btir.dao.ha.PooledStmt;
- /* */ import btir.utils.MiscUtil;
- /* */ import org.apache.commons.logging.Log;
- /* */ import org.apache.commons.logging.LogFactory;
- /* */
- /* */
- /* */
- /* */
- /* */
- /* */
- /* */
- /* */ public class IdHolder
- /* */ {
- /* */ public static final int NO_ID_AVAILABLE = 0;
- /* 19 */ private static final Log log = LogFactory.getLog(IdHolder.class);
- /* */
- /* */
- /* */
- /* */ private int current;
- /* */
- /* */
- /* */ private int end;
- /* */
- /* */
- /* */
- /* */ public synchronized int getId(byte type, int stmtId)
- /* */ {
- /* 32 */ if (end <= current)
- /* */ {
- /* */ try
- /* */ {
- /* 36 */ PooledStmt stmt = DBMgr.borrowSingleStmt(stmtId);
- /* */
- /* */
- /* 39 */ stmt.setByte(3, type);
- /* 40 */ stmt.executeUpdate();
- /* 41 */ current = stmt.getInt(1);
- /* 42 */ end = stmt.getInt(2);
- /* 43 */ stmt.returnMe();
- /* */ } catch (BtirException e) {
- /* 45 */ current = (end = 0);
- /* 46 */ log.error("can't get id for type=" + type);
- /* 47 */ log.error(MiscUtil.traceInfo(e));
- /* 48 */ return 0;
- /* */ }
- /* 50 */ if (end <= current)
- /* 51 */ return 0;
- /* */ }
- /* 53 */ return current++;
- /* */ }
- /* */
- /* */ public synchronized int getId(byte type, PooledStmt stmt) {
- /* 57 */ if (end <= current) {
- /* */ try {
- /* 59 */ stmt.setByte(3, type);
- /* 60 */ stmt.executeUpdate();
- /* 61 */ current = stmt.getInt(1);
- /* 62 */ end = stmt.getInt(2);
- /* */ } catch (BtirException e) {
- /* 64 */ current = (end = 0);
- /* 65 */ return 0;
- /* */ }
- /* 67 */ if (end <= current)
- /* 68 */ return 0;
- /* */ }
- /* 70 */ return current++;
- /* */ }
- /* */ }
上面这段代码主要是调用存储过程,对应配置的表的ID自增。。。
分布式数据库主键id生成策略的更多相关文章
- 数据库主键ID生成策略
前言: 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实现分库 ...
- 数据库分库分表(一)常见分布式主键ID生成策略
主键生成策略 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实 ...
- mybatis 针对SQL Server 的 主键id生成策略
SQL Server中命令: select newId() ,可以得到SQL server数据库原生的UUID值,因此我们可以将这条指令写到 Mybatis的主键生成策略配置selectKey中. ...
- Hibernate系列之ID生成策略
一.概述 hibernate中使用两种方式实现主键生成策略,分别是XML生成id和注解方式(@GeneratedValue),下面逐一进行总结. 二.XML配置方法 这种方式是在XX.hbm.xml文 ...
- JPA ID生成策略(转---)
尊重原创:http://tendyming.iteye.com/blog/2024985 JPA ID生成策略 @Table Table用来定义entity主表的name,catalog,schema ...
- 分库分表的 9种分布式主键ID 生成方案,挺全乎的
<sharding-jdbc 分库分表的 4种分片策略> 中我们介绍了 sharding-jdbc 4种分片策略的使用场景,可以满足基础的分片功能开发,这篇我们来看看分库分表后,应该如何为 ...
- hibernate(四)ID生成策略
一.ID生成策略配置 1.ID生成方式在xml中配置方式: <?xml version="1.0"?> <!DOCTYPE hibernate-mapping P ...
- 业务ID 生成策略
业务ID 生成策略,从技术上说,基本要借助一个集中式的引擎来帮忙实现. 为了扩大业务ID生成策略的并发问题,还有更为技巧性的提升. 先来介绍普遍的分布式ID生成策略: 1. 利用DB的自增主键 这里又 ...
- Rhythmk 学习 Hibernate 03 - Hibernate 之 延时加载 以及 ID 生成策略
Hibernate 加载数据 有get,跟Load 1.懒加载: 使用session.load(type,id)获取对象,并不读取数据库,只有在使用返回对象值才正真去查询数据库. @Test publ ...
随机推荐
- mysql 创建新用户并添加权限
1.添加用户 1.1 添加一个新用户: mysql>grant usage on *.* to " with grant option; 上面这种只支持mysql服务器本地登录. 1. ...
- 关于Cocos2d-x中音效重复播放问题的解决
在做一些动作的时候,有时候只希望播放一次音效,但是触发音效的前提条件是要按着某个按钮,如果直接把播放音效的语句写在MOVED的case中,就会重复播放音效 解决方法就是把播放音效的语句写在BEGAN的 ...
- Intellij Idea14 jstl标签的引入
习惯了eclipse和myeclipse开发的我们总是依赖于系统的插件,而当我想当然的以为IntelliJ IDEA 的jstl 的使用应该和myeclispe一样,当时使用起来却到处碰壁,完全找不到 ...
- Unable to resolve target 'android-20'
使用eclipse编写android的app时,出现错误:Unable to resolve target 'android-20'. 参看链接: http://blog.csdn.net/u0134 ...
- ubuntu下使用VI编辑文件必知的常用命令
进入vi的命令 vi filename :打开或新建文件,并将光标置于第一行首 vi +n filename :打开文件,并将光标置于第n行首 vi + filename :打开文件,并将光标置于最后 ...
- Pacbio 纯三代组装复活草基因组
对于植物等真核生物基因组来说,重复序列, 多倍体,高杂合度等特征在利用二代数据进行组装的时候都会有很大的问题: 利用二代数据组装出来的基因组,大多达不到完成图的水准,通常只是覆盖到编码蛋白的基因区域, ...
- CentOS开关机命令
命令简介 shutdown,poweroff,reboot,halt,init都可以进行关机,大致用法. /sbin/halt [-n] [-w] [-d] [-f] [-i] [-p] [- ...
- 单例模式(singleton pattern)--------创造型模式
缺点: 1.单例模式没有抽象层,单例模式的扩展较困那(开闭原则) 2.单例类的职责过重,既提供了业务方法,又提供了创建对象的方法,将对象的创建和对象本身的功能耦合在一起(违反单一职责原则,但是似乎又无 ...
- HDFS特点
- .Net中的序列化和反序列化详解
序列化通俗地讲就是将一个对象转换成一个字节流的过程,这样就可以轻松保存在磁盘文件或数据库中.反序列化是序列化的逆过程,就是将一个字节流转换回原来的对象的过程. 然而为什么需要序列化和反序列化这样的机制 ...