Hbase(一)基础知识
一、Hbase数据库介绍
1、简介
HBase 是 BigTable 的开源 java 版本。是建立在 HDFS 之上,提供高可靠性、高性能、列存储、 可伸缩、实时读写 NoSQL 的数据库系统。
NoSQL = NO SQL
NoSQL = Not Only SQL
把 NoSQL 数据的原生查询语句 封装成 SQL
HBase Phoenix

以下五点是 HBase 这个 NoSQL 数据库的要点:
① 它介于 nosql 和 RDBMS 之间,仅能通过主键(row key)和主键的 range 来检索数据,仅支 持单行事务(可通过 hive 支持来实现多表 join 等复杂操作)。
② Hbase 查询数据功能很简单, 不支持 join 等复杂操作
③ 不支持复杂的事务(行级的事务)
④ Hbase 中支持的数据类型: byte[]
⑤ 主要用来存储结构化和半结构化的松散数据。
结构化:数据结构字段含义确定,清晰,典型的如数据库中的表结构.
半结构化:具有一定结构,但语义不够确定,典型的如 HTML 网页,有些字段是确定的(title), 有些不确定(table)
非结构化:杂乱无章的数据,很难按照一个概念去进行抽取,无规律性
与 hadoop 一样, Hbase 目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加 计算和存储能力。
HBase 中的表一般有这样的特点:
(1) 大:一个表可以有上十亿行,上百万列
(2) 面向列: 面向列(族)的存储和权限控制,列(族)独立检索。 (同时对两个列做处理,并不影响)
(3) 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
2、表结构逻辑视图
HBase 以表的形式存储数据。表有行和列组成。列划分为若干个列簇 (column family) 建表语句只需表名和列族名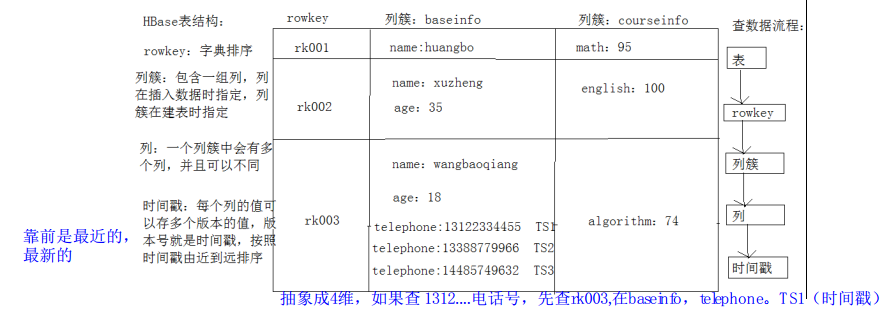
3、RowKey
与 nosql 数据库们一样,row key 是用来检索记录的主键。访问 hbase table 中的行,只有三种 方式:
(1) 通过单个 row key 访问
(2) 通过 row key 的 range
(3) 全表扫描
Row key 行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes), 最好是 16或者8。 在 hbase 内部, row key 保存为字节数组。 Hbase 会对表中的数据按照 rowkey 排序(字典顺序)
存储时,数据按照 Row key 的字典序(byte order)排序存储。设计 key 时,要充分排序存储这 个特性,将经常一起读取的行存储放到一起。 (位置相关性)
注意:
字典序对 int 排序的结果是
1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,„,9,91,92,93,94,95,96,97,98,99。要保持整形的自 然序,行键必须用 0 作左填充。
行的一次读写是原子操作 (不论一次读写多少列)。这个设计决策能够使用户很容易的理解 程序在对同一个行进行并发更新操作时的行为。
4、列簇
hbase 表中的每个列,都归属与某个列族。列族是表的 schema 的一部分(而列不是),必须在 使用表之前定义。
列名都以列族作为前缀。例如 courses:history , courses:math 都属于 courses 这个列族。 访问控制、磁盘和内存的使用统计都是在列族层面进行的。
列族越多,在取一行数据时所要参与 IO、搜寻的文件就越多,所以,如果没有必要,不要 设置太多的列族
(每个列族存放在不同的文件中,建表时列族越少越好)
5、时间戳
HBase 中通过 row 和 columns 确定的为一个存储单元称为 cell。每个 cell 都保存着同一份数 据的多个版本。版本通过时间戳来索引。时间戳的类型是 64 位整型。时间戳可以由 hbase(在 数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显
式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell 中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担, hbase 提供了两种数据版 本回收方式:
保存数据的最后 n 个版本
保存最近一段时间内的版本(设置数据的生命周期 TTL)。
用户可以针对每个列族进行设置。
6、cell
由{row key, column( =<family> + <label>), version} 唯一确定的单元。
cell 中的数据是没有类型的,全部是字节码形式存贮。
二、Hbase集群架构


三、hbase集群搭建
1、安装步骤:
先安装zookeeper集群




10、 如果有节点相应的进程没有启动,那么可以手动启动
hbase-daemon.sh start master
hbase-daemon.sh start regionserver
四、hbase命令行演示
1、 先进入 hbase shell 命令行
在你安装的随意台服务器节点上,执行命令: hbase shell,会进入到你的 hbase shell 客 户端
2、 进入之后先别着急,先看一下提示。 其实是不是有一句很重要的话:
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
意在告诉怎么获得帮助,怎么退出客户端
help 获取帮助
help 获取所有命令提示
help "dml" 获取一组命令的提示
help "put" 获取一个单独命令的提示帮助
exit 退出 hbase shell 客户端
3、下面真正进入命令的演示
(1)显示hbase中的表: list
(2) 第一个表名,多个列簇:
create 'user_info',{NAME=>'base_info',VERSION=>3 },{NAME=>'extra_info',VERSION=>1 }
put 'user_info', 'user0000', 'base_info:name', 'luoyufeng'
put 'user_info', 'user0000', 'base_info:age', '18'
put 'user_info', 'user0000', 'base_info:gender', 'female'
put 'user_info', 'user0000', 'extra_info:size', '34'
获取数据:get 'user_info', 'user0000'
(3)查看集群状态 status 查看集群的版本信息version
4、(1)ddl操作
列出所有表 :list
创建表:create 'user', 'info1', 'data1' 表名:user,包含info1和data1两个列簇
或者 create 'table_test1',{NAME => 'cf1', VERSIONS => 3}, {NAME => 'cf2', VERSIONS => 2} 好处就是可以方便我们给表的每个列簇设置一些属性,如果按照上面的方 式创建,那就表示所有的列簇的属性都是取默认值
查看表的详细信息:desc 'user'
alter修改表的定义:
增加列簇:alter 'table','liezu' 或者alter 'table_test', {NAME => 'another_family', VERSIONS => 4}
删除列簇:alter 'table_test', {NAME => 'another_family', METHOD => 'delete'} 或者 alter 'table_test', 'delete' => 'add_family'
查看表存在不存在:exists 'table'
disable 使表失效
enable 启用表
is_disabled 判断表是否是失效状态
is_enabled 判断表是否是启用状态 (删除表之前先使表失效)
删除表:drop 'table'
(2)dml操作
put插入数据: put 'table_test','rk01','cf1:name','huangbo' 或者 put 'table_test','rk01','cf1:age',20,1482077777777 时间戳是可以自己指定的,如若不指定,则会自动获取系统的当前时间的时间戳
get获取数据:
get 'table_test','rk01 从 table_test 表中查 rowkey 为 rk01 的所有列簇的所有数据
get 'table_test','rk01','cf1:name' 从 table_test 表中查 rowkey 为 rk01 的列为 cf1:name 的最新数据
get 'table_test','rk01',{COLUMNS => 'cf1:name', VERSIONS => 3} 从 table_test 表中查 rowkey 为 rk01 的列为 cf1:name 的所有版本数据, 3 个版本
scan查看某表的数据:
scan 'table_test'
scan 'table_test',{COLUMNS => 'cf1:name'}
scan 'table_test',{COLUMNS => 'cf1:name', TIMESTAMP => 1482018424571}
scan 'user', {COLUMNS => 'info:name', VERSIONS => 5}
scan 'user', {COLUMNS => ['info', 'data'], FILTER => "(QualifierFilter(=,'substring:a'))"} 查询 user 表中列族为 info 和 data 且列标示符中含有 a 字符的信息
scan 'people', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'} 查询 user 表中列族为 info, rk 范围是[rk0001, rk0003)的数据
scan 'user',{FILTER=>"PrefixFilter('rk')"} 查询 user 表中 row key 以 rk 字符开头的
scan 'user', {TIMERANGE => [1392368783980, 1392380169184]} 查询 user 表中指定范围的数据
scan 'car',{LIMIT=>10}
delete删除数据:
delete 'people', 'rk0001', 'info:name' 删除 user 表 row key 为 rk0001,列标示符为 info:name 的数据
delete 'user', 'rk0001', 'info:name', 1392383705316 删除 user 表 row key 为 rk0001,列标示符为 info:name, timestamp 为 1392383705316 的数据
清空表中数据:truncate 'table'
过滤器:
get 'person', 'rk0001', {FILTER => "ValueFilter(=, 'binary:中国')"}
get 'person', 'rk0001', {FILTER => "(QualifierFilter(=,'substring:a'))"}
scan 'person', {COLUMNS => 'info:name'}
scan 'person', {COLUMNS => ['info', 'data'], FILTER => "(QualifierFilter(=,'substring:a'))"}
scan 'person', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
scan 'person', {COLUMNS => 'info', STARTROW => '20140201', ENDROW => '20140301'}
scan 'person', {COLUMNS => 'info:name', TIMERANGE => [1395978233636, 1395987769587]}
alter 'person', NAME => 'ffff'
alter 'person', NAME => 'info', VERSIONS => 10
get 'user', 'rk0002', {COLUMN => ['info:name', 'data:pic']}
修改表结构之前,先使表失效,修改完后,再启用表
补充:
get和scan查看表中数据的区别:
get:指定rowkey获取数据
scan:指定条件获取一批数据
Hbase(一)基础知识的更多相关文章
- HBase的基础知识
1.HBase(NoSQL:不是关系型数据库)的逻辑数据模型 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC S ...
- HBASE基础知识总结
HBASE基础知识总结 一,概要说明 文章首先回顾HBase 的数据模型和数据层级结构,对数据的每个层级的作用和架构进行了详细阐述:随后介绍了数据写入和读取的详细流程.先把架构图和流程图来坐镇. 架构 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- ZooKeeper_基础知识学习
ZooKeeper是Hadoop的开源子项目(Google Chubby的开源实现),它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护.命名服务.分布式同步.组服务等. Zookee ...
- HBase框架基础(五)
* HBase框架基础(五) 本节主要介绍HBase中关于分区的一些知识. * HBase的RowKey设计 我们为什么要讨论rowKey的设计?或者说为什么很多工作岗位要求有rowKey的优化设计经 ...
- HBase框架基础(四)
* HBase框架基础(四) 上一节我们介绍了如何使用HBase搞一些MapReduce小程序,其主要作用呢是可以做一些数据清洗和分析或者导入数据的工作,这一节我们来介绍如何使用HBase与其他框架进 ...
- HBase框架基础(二)
* HBase框架基础(二) 上一节我们了解了HBase的架构原理和模块组成,这一节我们先来聊一聊HBase的读写数据的过程. * HBase的读写流程及3个机制 HBase的读数据流程: 1.HRe ...
- Elasticsearch基础知识学习
概要 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Ap ...
随机推荐
- 利用 Intel Realsense做SLAM开发(一)
最近手里拿到一台Realsense D435,就是这个: https://click.intel.com/intelr-realsensetm-depth-camera-d435.html 所以准备拿 ...
- VIN码识别/车架号识别独家支持云识别
VIN码(车架号)对于懂车的人来说并不陌生,不要小看这一串字符,从VIN码中可以读懂车辆的生产厂家.年代.车型.车身型式及代码.发动机代码及组装地点等信息. 一辆汽车的VIN码也是车辆的唯一身份证明, ...
- python3 selenium实现自动登陆网页
一. 安装python3与pycharm python安装参考链接:https://www.cnblogs.com/hepeilinnow/p/9727922.html pycharm最好安装专业版 ...
- Python教程 深入条件控制
while 和 if 条件句中可以使用任意操作,而不仅仅是比较操作. 比较操作符 in 和 not in 校验一个值是否在(或不在)一个序列里.操作符 is 和 is not 比较两个对象是不是同一个 ...
- springboot 集成 swagger
1. 首先配置swaggerConfigpackage com.lixcx.lismservice.config; import com.lixcx.lismservice.format.Custom ...
- python分割文件目录/文件名和后缀
import os file_path = "D:/test/test.py" (filepath,tempfilename) = os.path.split(file_path) ...
- 扩展Lucas定理 扩展Lucas板子
题意概述:多组询问,给出N,K,M,要求回答C(N,K)%M,1<=N<=10^18,1<=K<=N,2<=M<=10^6 分析: 模数不为质数只能用扩展Lucas ...
- 作业 20181023-11 Alpha发布
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2283 队名:可以低头,但没必要 组长:付佳 组员:张俊余 李文涛 孙赛佳 ...
- Scrum立会报告+燃尽图(Beta阶段第四次)
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2386 项目地址:https://coding.net/u/wuyy694 ...
- Alpha发布—文案+美工展示
目录 团队简介 项目进展 组内分工 队员总结 后期计划 一.团队简介 二.项目进展 从选题发布到今天的Alpha发布,我们团队经历了许许多多的磨难.我们最终设计了如下的功能:首页.班级.个人.更多.打 ...