集成学习之Boosting —— AdaBoost实现
集成学习之Boosting —— AdaBoost原理
集成学习之Boosting —— AdaBoost实现
AdaBoost的一般算法流程
输入: 训练数据集 \(T = \left \{(x_1,y_1), (x_2,y_2), \cdots (x_N,y_N)\right \}\),\(y\in\left\{-1,+1 \right\}\),基学习器\(G_m(x)\),训练轮数M
- 初始化权值分布: \(w_i^{(1)} = \frac{1}{N}\:, \;\;\;\; i=1,2,3, \cdots N\)
- for m=1 to M:
(a) 使用带有权值分布的训练集学习得到基学习器\(G_m(x)\):\[G_m(x) = \mathop{\arg\min}\limits_{G(x)}\sum\limits_{i=1}^Nw_i^{(m)}\mathbb{I}(y_i \neq G(x_i))
\]\(\qquad\) (b) 计算\(G_m(x)\)在训练集上的误差率:
\[\epsilon_m = \frac{\sum\limits_{i=1}^Nw_i^{(m)}\mathbb{I}(y_i \neq G_m(x_i))}{\sum\limits_{i=1}^Nw_i^{(m)}}
\]\(\qquad\)(c) 计算\(G_m(x)\)的系数: \(\alpha_m = \frac{1}{2}ln\frac{1-\epsilon_m}{\epsilon_m}\)
\(\qquad\)(d) 更新样本权重分布: \(w_{i}^{(m+1)} = \frac{w_i^{(m)}e^{-y_i\alpha_mG_m(x_i)}}{Z^{(m)}}\; ,\qquad i=1,2,3\cdots N\)
其中\(Z^{(m)}\)是规范化因子,\(Z^{(m)} = \sum\limits_{i=1}^Nw^{(m)}_ie^{-y_i\alpha_mG_m(x_i)}\),以确保所有的\(w_i^{(m+1)}\)构成一个分布。
3. 输出最终模型: \(G(x) = sign\left[\sum\limits_{m=1}^M\alpha_mG_m(x) \right]\)
- 另外具体实现了real adaboost, early_stopping,weight_trimming和分步预测 (stage_predict,见完整代码)。
import numpy as np
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.base import clone
from sklearn.metrics import zero_one_loss
import time
class AdaBoost(object):
def __init__(self, M, clf, learning_rate=1.0, method="discrete", tol=None, weight_trimming=None):
self.M = M
self.clf = clf
self.learning_rate = learning_rate
self.method = method
self.tol = tol
self.weight_trimming = weight_trimming
def fit(self, X, y):
# tol为early_stopping的阈值,如果使用early_stopping,则从训练集中分出验证集
if self.tol is not None:
X, X_val, y, y_val = train_test_split(X, y, random_state=2)
former_loss = 1
count = 0
tol_init = self.tol
w = np.array([1 / len(X)] * len(X)) # 初始化权重为1/n
self.clf_total = []
self.alpha_total = []
for m in range(self.M):
classifier = clone(self.clf)
if self.method == "discrete":
if m >= 1 and self.weight_trimming is not None:
# weight_trimming的实现,先将权重排序,计算累积和,再去除权重过小的样本
sort_w = np.sort(w)[::-1]
cum_sum = np.cumsum(sort_w)
percent_w = sort_w[np.where(cum_sum >= self.weight_trimming)][0]
w_fit, X_fit, y_fit = w[w >= percent_w], X[w >= percent_w], y[w >= percent_w]
y_pred = classifier.fit(X_fit, y_fit, sample_weight=w_fit).predict(X)
else:
y_pred = classifier.fit(X, y, sample_weight=w).predict(X)
loss = np.zeros(len(X))
loss[y_pred != y] = 1
err = np.sum(w * loss) # 计算带权误差率
alpha = 0.5 * np.log((1 - err) / err) * self.learning_rate # 计算基学习器的系数alpha
w = (w * np.exp(-y * alpha * y_pred)) / np.sum(w * np.exp(-y * alpha * y_pred)) # 更新权重分布
self.alpha_total.append(alpha)
self.clf_total.append(classifier)
elif self.method == "real":
if m >= 1 and self.weight_trimming is not None:
sort_w = np.sort(w)[::-1]
cum_sum = np.cumsum(sort_w)
percent_w = sort_w[np.where(cum_sum >= self.weight_trimming)][0]
w_fit, X_fit, y_fit = w[w >= percent_w], X[w >= percent_w], y[w >= percent_w]
y_pred = classifier.fit(X_fit, y_fit, sample_weight=w_fit).predict_proba(X)[:, 1]
else:
y_pred = classifier.fit(X, y, sample_weight=w).predict_proba(X)[:, 1]
y_pred = np.clip(y_pred, 1e-15, 1 - 1e-15)
clf = 0.5 * np.log(y_pred / (1 - y_pred)) * self.learning_rate
w = (w * np.exp(-y * clf)) / np.sum(w * np.exp(-y * clf))
self.clf_total.append(classifier)
'''early stopping'''
if m % 10 == 0 and m > 300 and self.tol is not None:
if self.method == "discrete":
p = np.array([self.alpha_total[m] * self.clf_total[m].predict(X_val) for m in range(m)])
elif self.method == "real":
p = []
for m in range(m):
ppp = self.clf_total[m].predict_proba(X_val)[:, 1]
ppp = np.clip(ppp, 1e-15, 1 - 1e-15)
p.append(self.learning_rate * 0.5 * np.log(ppp / (1 - ppp)))
p = np.array(p)
stage_pred = np.sign(p.sum(axis=0))
later_loss = zero_one_loss(stage_pred, y_val)
if later_loss > (former_loss + self.tol):
count += 1
self.tol = self.tol / 2
else:
count = 0
self.tol = tol_init
if count == 2:
self.M = m - 20
print("early stopping in round {}, best round is {}, M = {}".format(m, m - 20, self.M))
break
former_loss = later_loss
return self
def predict(self, X):
if self.method == "discrete":
pred = np.array([self.alpha_total[m] * self.clf_total[m].predict(X) for m in range(self.M)])
elif self.method == "real":
pred = []
for m in range(self.M):
p = self.clf_total[m].predict_proba(X)[:, 1]
p = np.clip(p, 1e-15, 1 - 1e-15)
pred.append(0.5 * np.log(p / (1 - p)))
return np.sign(np.sum(pred, axis=0))
if __name__ == "__main__":
#测试各模型的准确率和耗时
X, y = datasets.make_hastie_10_2(n_samples=20000, random_state=1) # data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
start_time = time.time()
model_discrete = AdaBoost(M=2000, clf=DecisionTreeClassifier(max_depth=1, random_state=1), learning_rate=1.0,
method="discrete", weight_trimming=None)
model_discrete.fit(X_train, y_train)
pred_discrete = model_discrete.predict(X_test)
acc = np.zeros(pred_discrete.shape)
acc[np.where(pred_discrete == y_test)] = 1
accuracy = np.sum(acc) / len(pred_discrete)
print('Discrete Adaboost accuracy: ', accuracy)
print('Discrete Adaboost time: ', '{:.2f}'.format(time.time() - start_time),'\n')
start_time = time.time()
model_real = AdaBoost(M=2000, clf=DecisionTreeClassifier(max_depth=1, random_state=1), learning_rate=1.0,
method="real", weight_trimming=None)
model_real.fit(X_train, y_train)
pred_real = model_real.predict(X_test)
acc = np.zeros(pred_real.shape)
acc[np.where(pred_real == y_test)] = 1
accuracy = np.sum(acc) / len(pred_real)
print('Real Adaboost accuracy: ', accuracy)
print("Real Adaboost time: ", '{:.2f}'.format(time.time() - start_time),'\n')
start_time = time.time()
model_discrete_weight = AdaBoost(M=2000, clf=DecisionTreeClassifier(max_depth=1, random_state=1), learning_rate=1.0,
method="discrete", weight_trimming=0.995)
model_discrete_weight.fit(X_train, y_train)
pred_discrete_weight = model_discrete_weight.predict(X_test)
acc = np.zeros(pred_discrete_weight.shape)
acc[np.where(pred_discrete_weight == y_test)] = 1
accuracy = np.sum(acc) / len(pred_discrete_weight)
print('Discrete Adaboost(weight_trimming 0.995) accuracy: ', accuracy)
print('Discrete Adaboost(weight_trimming 0.995) time: ', '{:.2f}'.format(time.time() - start_time),'\n')
start_time = time.time()
mdoel_real_weight = AdaBoost(M=2000, clf=DecisionTreeClassifier(max_depth=1, random_state=1), learning_rate=1.0,
method="real", weight_trimming=0.999)
mdoel_real_weight.fit(X_train, y_train)
pred_real_weight = mdoel_real_weight.predict(X_test)
acc = np.zeros(pred_real_weight.shape)
acc[np.where(pred_real_weight == y_test)] = 1
accuracy = np.sum(acc) / len(pred_real_weight)
print('Real Adaboost(weight_trimming 0.999) accuracy: ', accuracy)
print('Real Adaboost(weight_trimming 0.999) time: ', '{:.2f}'.format(time.time() - start_time),'\n')
start_time = time.time()
model_discrete = AdaBoost(M=2000, clf=DecisionTreeClassifier(max_depth=1, random_state=1), learning_rate=1.0,
method="discrete", weight_trimming=None, tol=0.0001)
model_discrete.fit(X_train, y_train)
pred_discrete = model_discrete.predict(X_test)
acc = np.zeros(pred_discrete.shape)
acc[np.where(pred_discrete == y_test)] = 1
accuracy = np.sum(acc) / len(pred_discrete)
print('Discrete Adaboost accuracy (early_stopping): ', accuracy)
print('Discrete Adaboost time (early_stopping): ', '{:.2f}'.format(time.time() - start_time),'\n')
start_time = time.time()
model_real = AdaBoost(M=2000, clf=DecisionTreeClassifier(max_depth=1, random_state=1), learning_rate=1.0,
method="real", weight_trimming=None, tol=0.0001)
model_real.fit(X_train, y_train)
pred_real = model_real.predict(X_test)
acc = np.zeros(pred_real.shape)
acc[np.where(pred_real == y_test)] = 1
accuracy = np.sum(acc) / len(pred_real)
print('Real Adaboost accuracy (early_stopping): ', accuracy)
print('Discrete Adaboost time (early_stopping): ', '{:.2f}'.format(time.time() - start_time),'\n')
输出结果:
Discrete Adaboost accuracy: 0.954
Discrete Adaboost time: 43.47
Real Adaboost accuracy: 0.9758
Real Adaboost time: 41.15
Discrete Adaboost(weight_trimming 0.995) accuracy: 0.9528
Discrete Adaboost(weight_trimming 0.995) time: 39.58
Real Adaboost(weight_trimming 0.999) accuracy: 0.9768
Real Adaboost(weight_trimming 0.999) time: 25.39
early stopping in round 750, best round is 730, M = 730
Discrete Adaboost accuracy (early_stopping): 0.9268
Discrete Adaboost time (early_stopping): 14.60
early stopping in round 539, best round is 519, M = 519
Real Adaboost accuracy (early_stopping): 0.974
Discrete Adaboost time (early_stopping): 11.64
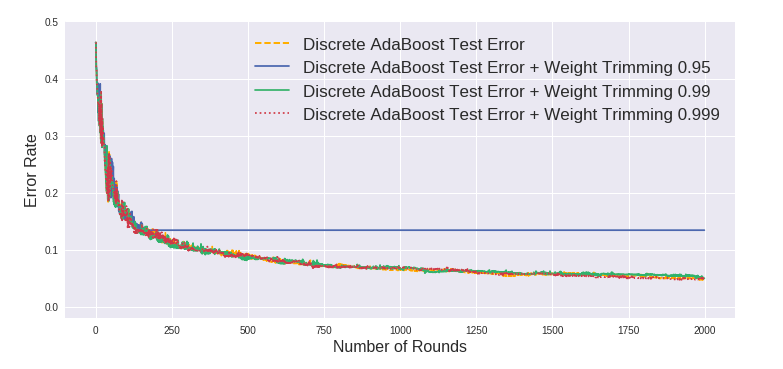
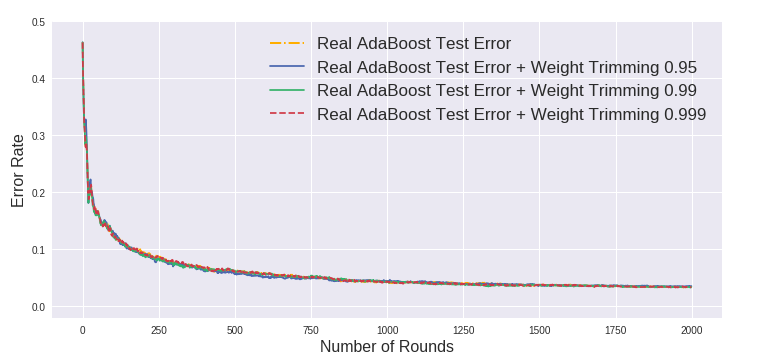
- 可以看到,weight_trimming对于Discrete AdaBoost的训练速度无太大提升,而对于Real AdaBoost则较明显,可能原因是Discrete AdaBoost每一轮的权重较分散,而Real AdaBoost的权重集中在少数的样本上。
- early_stopping分别发生在750和539轮,最后准确率也可以接受。
下两张图显示使用weight_trimming的情况下准确率与正常AdaBoost相差无几 (除了0.95的情况)。
Discrete AdaBoost vs. Real AdaBoost - Overfitting
AdaBoost有一个吸引人的特性,那就是其“不会过拟合”,或者更准确的说法是在训练误差下降到零之后继续训练依然能提高泛化性能。如下图所示,训练10000棵树,Real AdaBoost的训练误差早早下降为零,而测试误差几乎平稳不变。而且可以看到 Real AdaBoost 对比 Discrete AdaBoost 无论是训练速度还是准确率都更胜一筹。
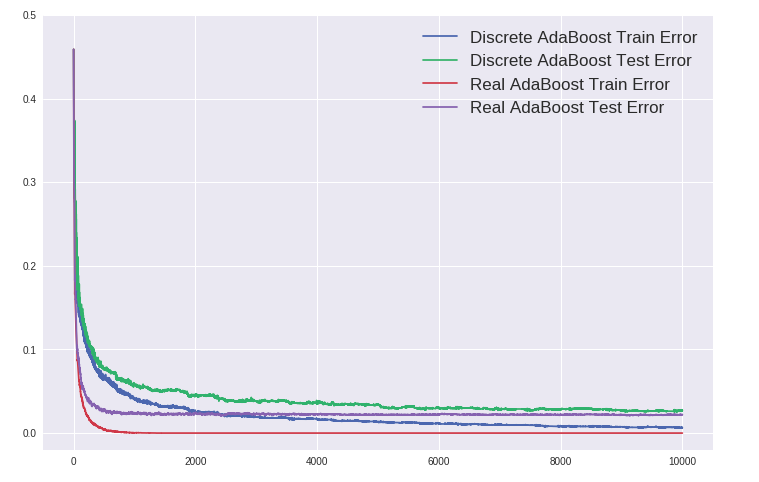
Margin理论可以解释这个现象,认为随着训练轮数的增加,即使训练误差已经至零,对于训练样本预测的margin依然会扩大,这等于会不断提升预测的信心。但过去十几年来学术界一直对该理论存在争议,具体可参阅AdaBoost发明者的论文 [Schapire, Explaining AdaBoost]。
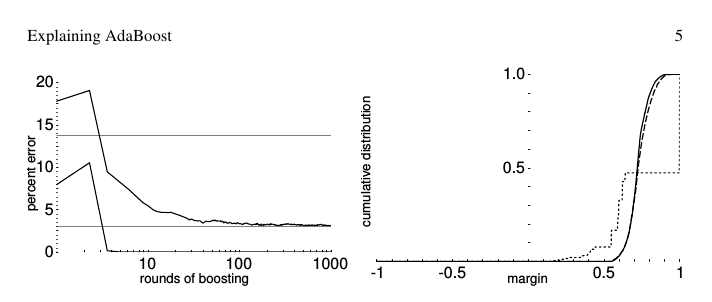
Learning Curve
Learning Curve是另一种评估模型的方法,反映随着训练集的增大,训练误差和测试误差的变化情况。通常如果两条曲线比较接近且误差都较大,为欠拟合;如果训练集误差率低,测试集误差率高,二者的曲线会存在较大距离,则为过拟合。
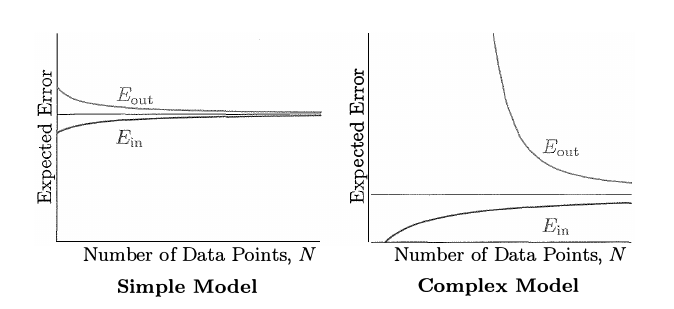
下面来看AdaBoost在上面数据集中的learning curve:
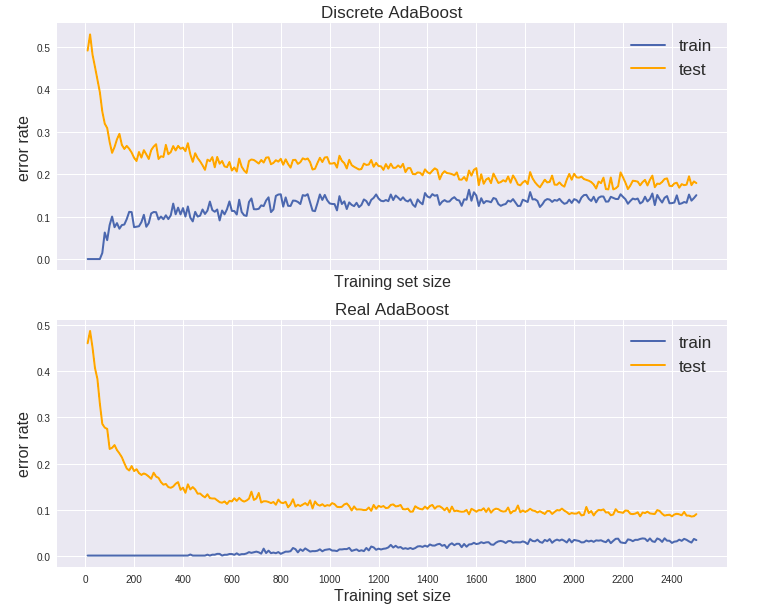
这里总共只选用了5000个数据 (2500训练集 + 2500测试集),因为learning curve的绘制通常需要拟合N个模型 (N为训练样本数),计算量太大。从上图来看Discrete AdaBoost是欠拟合,而Real AdaBoost比较像是过拟合,如果进一步增加数据,Real AdaBoost的测试误差率可能会进一步下降。
完整代码
/
集成学习之Boosting —— AdaBoost实现的更多相关文章
- 集成学习之Boosting —— AdaBoost原理
集成学习大致可分为两大类:Bagging和Boosting.Bagging一般使用强学习器,其个体学习器之间不存在强依赖关系,容易并行.Boosting则使用弱分类器,其个体学习器之间存在强依赖关系, ...
- 集成学习之Boosting —— XGBoost
集成学习之Boosting -- AdaBoost 集成学习之Boosting -- Gradient Boosting 集成学习之Boosting -- XGBoost Gradient Boost ...
- 集成学习之Boosting —— Gradient Boosting原理
集成学习之Boosting -- AdaBoost原理 集成学习之Boosting -- AdaBoost实现 集成学习之Boosting -- Gradient Boosting原理 集成学习之Bo ...
- 集成学习二: Boosting
目录 集成学习二: Boosting 引言 Adaboost Adaboost 算法 前向分步算法 前向分步算法 Boosting Tree 回归树 提升回归树 Gradient Boosting 参 ...
- 大白话5分钟带你走进人工智能-第30节集成学习之Boosting方式和Adaboost
目录 1.前述: 2.Bosting方式介绍: 3.Adaboost例子: 4.adaboost整体流程: 5.待解决问题: 6.解决第一个问题:如何获得不同的g(x): 6.1 我们看下权重与函数的 ...
- 集成学习原理:Adaboost
集成学习通过从大量的特征中挑出最优的特征,并将其转化为对应的弱分类器进行分类使用,从而达到对目标进行分类的目的. 核心思想 它是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器), ...
- 集成学习之Boosting —— Gradient Boosting实现
Gradient Boosting的一般算法流程 初始化: \(f_0(x) = \mathop{\arg\min}\limits_\gamma \sum\limits_{i=1}^N L(y_i, ...
- 机器学习——集成学习之Boosting
整理自: https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1 AdaBoost GB ...
- 决策树(中)-集成学习、RF、AdaBoost、Boost Tree、GBDT
参考资料(要是对于本文的理解不够透彻,必须将以下博客认知阅读): 1. https://zhuanlan.zhihu.com/p/86263786 2.https://blog.csdn.net/li ...
随机推荐
- PROPAGATION_REQUIRES_NEW VS PROPAGATION_NESTED
PROPAGATION_REQUIRES_NEW, in contrast to PROPAGATION_REQUIRED, uses a completely independent transac ...
- redhat 6.6 离线安装docker
本机环境:redhat6.6 uname -a Linux host- -.el6.x86_64 # SMP Tue Sep :: EDT x86_64 x86_64 x86_64 GNU/Linux ...
- centos linux系统日常管理复习 CPU物理数逻辑核数,iftop ,iotop ,sar ,ps,netstat ,一网卡多IP,mii-tool 连接,ethtool速率,一个网卡配置多个IP,mii-tool 连接,ethtool速率 ,crontab备份, 第十八节课
centos linux系统日常管理复习 物理CPU和每颗CPU的逻辑核数,uptime ,w,vmstat,iftop ,iotop ,sar ,ps,netstat ,一个网卡配置多个IP,mii ...
- hbase Java API 介绍及使用示例
几个相关类与HBase数据模型之间的对应关系 java类 HBase数据模型 HBaseAdmin 数据库(DataBase) HBaseConfiguration HTable 表(Table) ...
- 解决FlexPaper分页分段加载问题(转)
FlexPaper是一个开源的PDF文档在线查看控件.用户查看PDF文档不需要安装Acrobat Reader,但需要利用像SwfTools这样的工具预先将PDF文档转成SWF格式的文件.FlexPa ...
- (转)如何让ActiveXObject( "Microsoft.XmlDom ")对象在非IE浏览器下显示数据?firefox(火狐)
如何让ActiveXObject( "Microsoft.XmlDom ")对象在非IE浏览器下显示数据?firefox(火狐) 2013-09-10 16:01 2152人阅读 ...
- uva1416 dijkstra
大白书P330 这题比较麻烦 给出一个n个节点m条边的无向图,每条边上有一个正权.令c等于每对节点的最短路长度之和.例n=3时, c = d(1,1)+d(1,2)+d(1,3)+d(2,1)+d(2 ...
- node学习笔记第一天
ES6---* JavaScript语言随着使用的人越来越多,ECMA语法规范:if/else* 为了让js语言更适应大型应用的开发.旨在消除一些怪异的行为 ### 包含内容(strict严格模式)- ...
- python遗留问题
def assert_element_in_page_source(s): print type(s) print s #assert s in driver.page_sourcecommand=' ...
- python使用cx_Oracle连接oracle
1.使用pip命令安装cx_Oracle $ pip install cx_Oracle 2.安装oracle客户端,并添加到path 下载路径: http://www.oracle.com/tech ...