在sorted range上的操作(includes,set_union,set_intersection,set_difference)
includes
S1内含S2的一个子集合,如果元素在s2出现n次,在S1出现m次,若n>m则会返回false
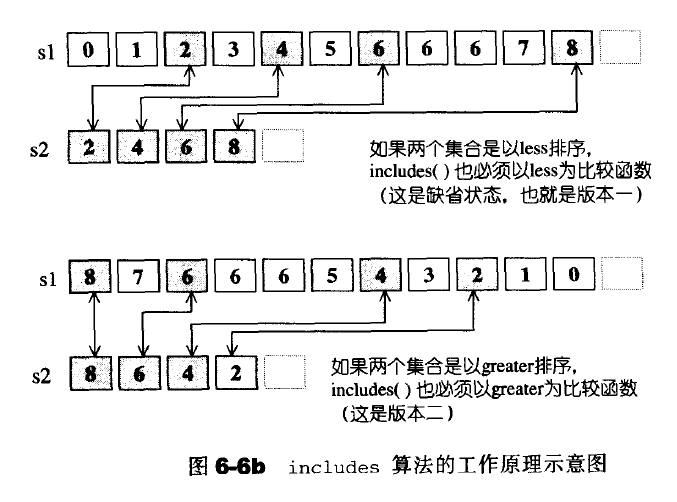
//版本一:用operator <比较元素
template <class InputerIterator1,class InputerIterator2>
bool includes(InputerIterator1 first1,InputerIterator1 last1,InputerIterator2 first2,InputerIterator2 last2); //版本二:用自定义的function object比较元素
template <class InputerIterator1,class InputerIterator2,class StrictWeakOrdering>
bool includes(InputerIterator1 first1,InputerIterator1 last1,InputerIterator2 first2,InputerIterator2 last2,StrictWeakOrdering cmp);
测试已排序的[first2,last2)是否为[first1,last1)的子集,每个集合中的元素不必独一无二,如果某个元素在[first1,last1)出现m次,在[first2,last2)出现n次,如果m<n,则返回false
set_union
//版本一:用operator <比较元素
template <class InputerIterator1,class InputerIterator2,class OutputIterator>
OutputIterator set_union(InputerIterator1 first1,InputerIterator1 last1,
InputerIterator2 first2,InputerIterator2 last2,OutputIterator rseult);
{
while(first1!=last1 && first2!=last2)
{
//两个容器内的元素相比较,把较小者放入结果容器中,并向前移动迭代器
//如果两个元素相等则写入结果中,同时移动两个迭代器
if(*first1<*first2)
{
*result = *first;
++first1;
}
else if(*first2<*first1)
{
*result = *first;
++first2;
}
else
{
*result = *first1;
++first1;
++first2;
}
++result;
}
//把剩余的元素都拷贝进结果中
//copy返回迭代器指向目标容器的插入元素的最后一个元素的下一个元素
return copy(first2, last2, copy(first1, last1, result));
}
//版本二:用自定义的function object比较元素
template <class InputerIterator1,class InputerIterator2,class OutputIterator,class StrictWeakOrdering>
OutputIterator set_union(InputerIterator1 first1,InputerIterator1 last1,
InputerIterator2 first2,InputerIterator2 last2,
OutputIterator result,StrictWeakOrdering cmp);
构造已排序的[first2,last2)和[first1,last1)的并集,每个集合中的元素不必独一无二
- 如果某个元素在[first1,last1)出现m次,在[first2,last2)出现n次,在result中出现的次数为max(m,n)
- 元素的相对顺序不会被改变,如果是两个集合中都有的元素,那么该元素是从第一个集合中复制来的(去除重复的元素)
- 两个集合中的等价元素在result中,m个元素是从第一个range中复制来的,max(n-m,0)个元素从第二个range中复制来
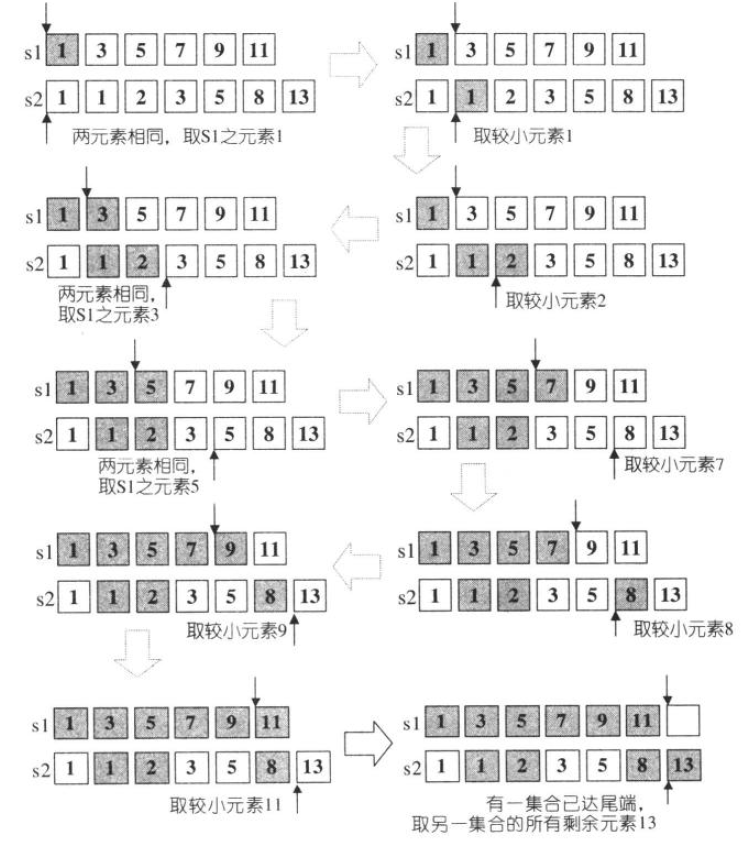
set_intersection
//版本一:用operator <比较元素
template <class InputerIterator1,class InputerIterator2,class OutputIterator>
OutputIterator set_intersection(InputerIterator1 first1,InputerIterator1 last1,
InputerIterator2 first2,InputerIterator2 last2,OutputIterator rseult);
{
while(first1!=last1 && first2!=last2)
{
if(*first1<*first2)
{
++first1;
}
else if(*first2<*first1)
{
++first2;
}
else
{
*result = *first1;
++first1;
++first2;
++result;
}
}
return result;
}
//版本二:用自定义的function object比较元素
template <class InputerIterator1,class InputerIterator2,class OutputIterator,class StrictWeakOrdering>
OutputIterator set_intersection(InputerIterator1 first1,InputerIterator1 last1,
InputerIterator2 first2,InputerIterator2 last2,
OutputIterator result,StrictWeakOrdering cmp);
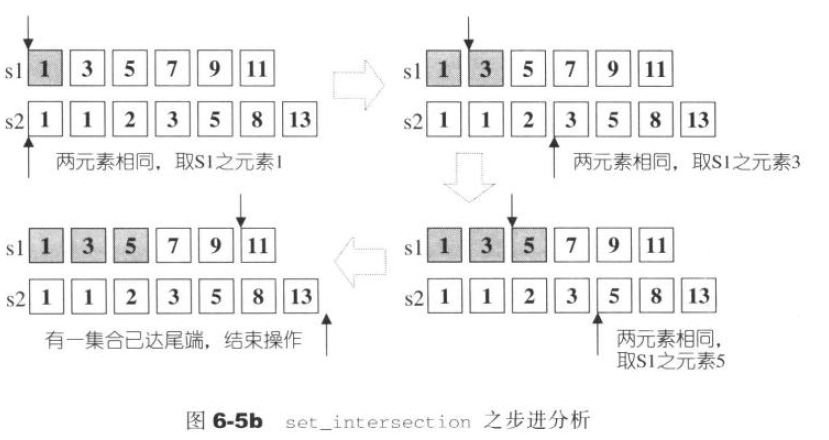
构造两个集合的交集,如果某个元素在[first1,last1)出现n次,在[first2,last2)出现m次,在result中出现的次数为min(n,m),所有元素赋值于[first1,last1),其他的与set_union相同, 他是一种稳定的操作
set_difference
- 构造两个集合的差集,result中的元素出现于第一个range但不出现于第二个range,他也是一种稳定的操作
- 某个元素在[first1,last1)中拥有n个彼此等价的元素,在[first2,last2)中拥有m个彼此等价的元素,result中含有max(n-m)个彼此等价的元素,所有元素都复制于[first1,last1)
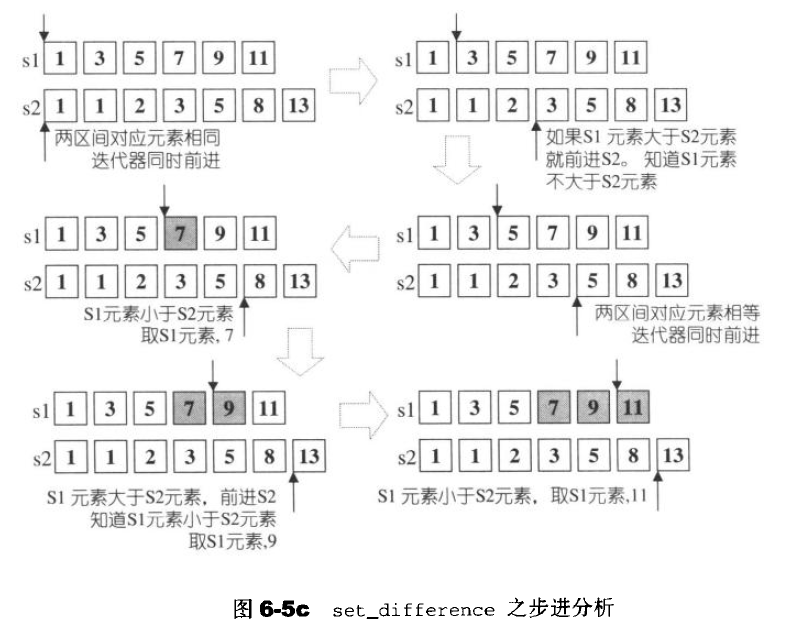
//版本一:用operator <比较元素
template <class InputerIterator1,class InputerIterator2,class OutputIterator>
OutputIterator set_difference(InputerIterator1 first1,InputerIterator1 last1,
InputerIterator2 first2,InputerIterator2 last2,OutputIterator rseult);
{
while(first1!=last1 && first2!=last2)
{
if(*first1<*first2)
{
*result = *first1;
++first;
++result;
}
else if(*first2<*first1)
{
++*first2;
}
else
{
++first1;
++first2;
}
}
return copy(first1, last1, result);
}
//版本二:用自定义的function object比较元素
template <class InputerIterator1,class InputerIterator2,class OutputIterator,class StrictWeakOrdering>
OutputIterator set_difference(InputerIterator1 first1,InputerIterator1 last1,
InputerIterator2 first2,InputerIterator2 last2,
OutputIterator result,StrictWeakOrdering cmp);
set_symmetric_difference
- 构造出两个集合之对称差,结果集包含出现于第一个range的元素但不出现于第二个range的元素以及出现于第二个range的元素但不出现于第一个range的元素,他也是一种稳定的操作,输入区间的元素相对顺序不会被改变
- 某个元素在[first1,last1)中拥有n个彼此等价的元素,在[first2,last2)中拥有m个彼此等价的元素,result中含有|n-m|个彼此等价的元素,若n>m,则result元素中最后n-m个将由[first1,last1)复制来,若n<m,则result元素中最后m-n个将由[first2,last2)复制来
//版本一:用operator <比较元素
template <class InputerIterator1,class InputerIterator2,class OutputIterator>
OutputIterator set_symmetric_difference(InputerIterator1 first1,InputerIterator1 last1,
InputerIterator2 first2,InputerIterator2 last2,OutputIterator rseult);
{
while(first1!=last1 && first2!=last2)
{
if(*first1<*first2)
{
*result = *first1;
++first1;
++result;
}
if(*first2<*first1)
{
*result = *first2;
++first2;
++result;
}
else
{
++first1;
++first2;
}
}
return copy(first1, last1, copy(first2, last2, result));
}
//版本二:用自定义的function object比较元素
template <class InputerIterator1,class InputerIterator2,class OutputIterator,class StrictWeakOrdering>
OutputIterator set_symmetric_difference(InputerIterator1 first1,InputerIterator1 last1,
InputerIterator2 first2,InputerIterator2 last2,
OutputIterator result,StrictWeakOrdering cmp);
在sorted range上的操作(includes,set_union,set_intersection,set_difference)的更多相关文章
- redis数据类型:sorted sets类型及操作
sorted sets类型及操作: sorted set是set的一个升级版本,它是在set的基础上增加了一个顺序 属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会 自动重新按新的值 ...
- C# 使用 Index 和 Range 简化集合操作
C# 使用 Index 和 Range 简化集合操作 Intro 有的语言数组的索引值是支持负数的,表示从后向前索引,比如:arr[-1] 从 C# 8 开始,C# 支持了数组的反向 Index,和 ...
- Web 在线文件管理器学习笔记与总结(11)获取文件夹信息 (12)返回上一级操作
(11)获取文件夹信息 文件夹没有修改操作. index.php: <?php require 'dir.func.php'; require 'file.func.php'; require ...
- Error is 10055 由于系统缓冲区空间不足或队列已满,不能执行套接字上的操作
今天上午,一个同事反映:某系统的某个通过socket来进行通信的服务无法连接上数据库里,在操作系统上用数据库的客户端测试数据库连接也出现这样的错误信息:Error is 10055 由于系统缓冲区空间 ...
- 将项目Demo上传到Github上的操作步骤
之前我有很多代码直接上传到了CSDN上,主要是因为操作方便,今天我就说说将源码Demo上传到Github上的操作步骤. 首先,你要先确定自己在Github上有自己的账户名,账户邮箱和密码.如果没有可以 ...
- Windows服务器【由于系统缓冲区空间不足或队列已满,不能执行套接字上的操作】问题调查
今天测试反应了一个问题,说接口返回的速度变慢了,并且返回的数据也不对.然后就找到了我o(╥﹏╥)o. 第一个反应就是查日志,不查不要紧,一查吓一跳,整个服务器上所有的站点都报错了.异常信息如下: Sy ...
- python-web自动化-文件上传操作(非input标签的上传,需要借助第三方工具)
文件上传操作 一.文件上传分两种情况:1. 如果是input可以直接输入路径的,可以直接调send_keys输入路径 2. 非input标签的上传,需要借助第三方工具: 2.1 Autolt 需 ...
- 定时备份windows机器上的文件到linux服务器上的操作梳理(rsync)
由于需要对网络设备做备份,备份文件是放到windows机器上的.现在需要将备份数据同步到linux备份机器上,想到的方案有三种: 1)将windows的备份目录共享出来,然后在linux服务器上进行挂 ...
- tf.reduce_sum tensorflow维度上的操作
tensorflow中有很多在维度上的操作,本例以常用的tf.reduce_sum进行说明.官方给的api reduce_sum( input_tensor, axis=None, keep_dims ...
随机推荐
- calc()
width:calc(): cale(a)计算出表达式a的值. e.g: height:cale(100vh-200px):vh,是指CSS中相对长度单位,表示相对视口高度,通常视口长度单位会被分成1 ...
- 自动化创建tornado项目
tornado目录结构: index.py 入口文件 app app目录 |___ __init__.py 初始化脚本 |___ templates 模板目录 | |___ index ...
- Docker(2):快速入门及常用命令
什么是Docker? Docker 是世界领先的软件容器平台.开发人员利用 Docker 可以消除协作编码时“在我的机器上可正常工作”的问题.运维人员利用 Docker 可以在隔离容器中并行运行和管理 ...
- oracle语句优化
摘录来自https://blog.csdn.net/sap_jack/article/details/3766703 1.选用适合的Oracle优化器 Oracle的优化器共有3种: a.RULE(基 ...
- apache rewrite 规则
啥是虚拟主机呢?就是说把你自己的本地的开发的机子变成一个虚拟域名,比如:你在开发pptv下面的一个项目 127.0.0.1/pptv_trunk,你想把自己的机器域名变成www.pptv.com.那么 ...
- python之pandas简单介绍及使用(一)
python之pandas简单介绍及使用(一) 一. Pandas简介1.Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据 ...
- Strassen algorithm(O(n^lg7))
Let A, B be two square matrices over a ring R. We want to calculate the matrix product C as {\displa ...
- 【Python】爬虫-1
#练习1:获取搜狐网页上所有的URL并且把与篮球有关的内容筛选出来 #算法: #.获取搜狐网站所有内容 #.判断哪些是链接,获取URL格式有效的链接 #.获取每个有效URL网页的内容 #.判断内容是否 ...
- rtsp 学习之路一
http://baijiahao.baidu.com/s?id=1587715130853990653&wfr=spider&for=pc https://www.cnblogs.co ...
- logminer实战之生产环境写入数据字典,dg环境查询拷贝日志,测试环境进行挖掘,输出结果
应客户需要,对某一天的日志进行挖掘,分析日均归档日志切换数量20增长至40的原因,是什么表的dml操作导致的日志量剧增,最终定位某个应用(需要客户自己进行甄别) 操作说明及介绍: 1.客户10.2.0 ...