看到篇博文,用python pandas改写了下
看到篇博文,https://blog.csdn.net/young2415/article/details/82795688
需求是需要统计部门礼品数量,自己简单绘制了个表格,如下:
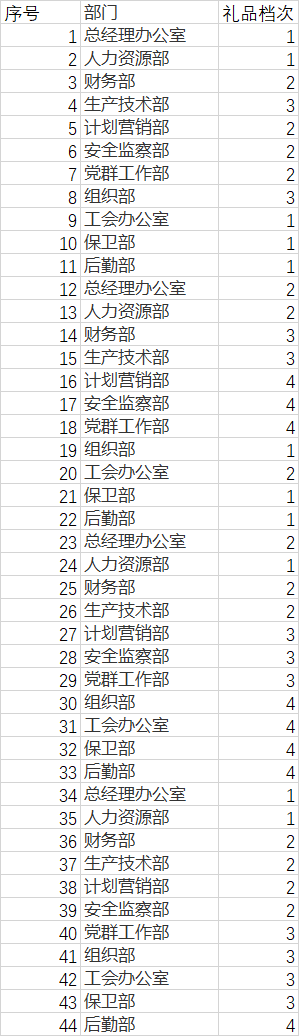

大意是,每个部门的员工发福利,有礼品档次(见表一),每个档次礼品对应不同礼品(见表二)
假设表一在test.xlsx的sheet1中,表二在test.xlsx的sheet2中,运算结果为同级目录下的result.xlsx,用python pandas改写代码如下:
import pandas as pd
df1 = pd.read_excel('test.xlsx', sheet_name=0, index_col='序号') # 读取表1
df2 = pd.read_excel('test.xlsx', sheet_name=1).fillna(method='pad') # 读取表2
df_result = pd.DataFrame(index=set(df1['部门']), columns=set(df2['产品'])).fillna(0) # 运算结果
for each_dept in set(df1['部门']): # 遍历每个部门
df_each_dept = df1[df1['部门'] == each_dept] # 在表1中取出每个部门的礼品情况
for each_dept_welfare in df_each_dept['礼品档次']: # 遍历每个部门的”礼品档次“:
for each_welfare in df2[df2['标准'] == each_dept_welfare]['产品']:
df_result.loc[each_dept, each_welfare] += 1 # 该部门对应的礼品数值+1
writer = pd.ExcelWriter('result.xlsx') # 保存结果
df_result.to_excel(writer, 'result')
writer.save()
改写后,不仅减少代码数量,而且无需事先建立礼品列表。
运算result.xlsx结果如下:
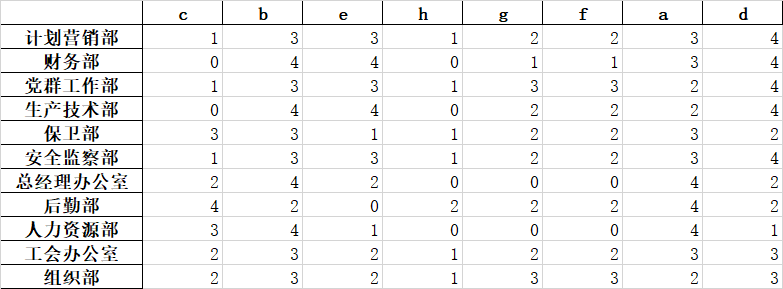
备注:遍历每个部门时,可以用groupby(),这样还可以少写一句代码,
import pandas as pd
df1 = pd.read_excel('test.xlsx', sheet_name=0, index_col='序号')
df2 = pd.read_excel('test.xlsx', sheet_name=1).fillna(method='pad')
df_result = pd.DataFrame(index=set(df1['部门']), columns=set(df2['产品'])).fillna(0)
for dept, df_dept in df1.groupby('部门'):
for dept_welfare in df_dept['礼品档次']:
for welfare in df2[df2['标准'] == dept_welfare]['产品']:
df_result.loc[dept, welfare] += 1
writer = pd.ExcelWriter('result.xlsx')
df_result.to_excel(writer, 'result')
writer.save()
看到篇博文,用python pandas改写了下的更多相关文章
- 我的第一篇博文,Python+scrapy框架安装。
自己用Python脚本写爬虫有一段时日了,也抓了不少网页,有的网页信息两多,一个脚本用exe跑了两个多月,数据还在进行中.但是总觉得这样抓效率有点低,问题也是多多的,很早就知道了这个框架好用,今天终于 ...
- 第一篇博文,整理一下关于Mac下安装本地LNMP环境的一些坑
安装的主要步骤是按照以下这篇文章进行的http://blog.csdn.net/w670328683/article/details/50628629,但是依然遇到了一些大大小小的坑(一个环境搞了一天 ...
- Python pandas & numpy 笔记
记性不好,多记录些常用的东西,真·持续更新中::先列出一些常用的网址: 参考了的 莫烦python pandas DOC numpy DOC matplotlib 常用 习惯上我们如此导入: impo ...
- python学习之【第十五篇】:Python中的常用模块之time模块
1.前言 在Python中,对时间的表示或操作通常要使用到time模块.本篇博文就来记录一下time模块中常用的几种时间表示转换方法. 2. 三种时间表示形式 2.1 时间戳 从1970年1月1日零点 ...
- 第一篇博客 Python开发环境配置
本文主要介绍Windows7环境下安装并配置Anaconda+VSCode作为Python开发环境. 目录 Anaconda与包管理配 Anaconda安装 添加环境变量 Anaconda安装错误及解 ...
- Python之路【第九篇】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用 ...
- python & pandas链接mysql数据库
Python&pandas与mysql连接 1.python 与mysql 连接及操作,直接上代码,简单直接高效: import MySQLdb try: conn = MySQLdb.con ...
- Pyhton开发【第五篇】:Python基础之杂货铺
Python开发[第五篇]:Python基础之杂货铺 字符串格式化 Python的字符串格式化有两种方式: 百分号方式.format方式 百分号的方式相对来说比较老,而format方式则是比较先进 ...
- webIDE 第二篇博文
这是我做webIDE过程中的第二篇博文,之所以隔了这么长时间没更,因为确实是没有啥进度啊,没什么可写的,现在虽然依然没啥进度,但中途遇到很多坑,这些坑还是有记录下来的必要的. 因个人水平问题,可能有的 ...
随机推荐
- selenium css定位方式
- 用uniGUI做B/S下业务系统的产品原型体验
从10月份到重庆工作后,一直忙于工作,感兴趣的几个方面的技术都处于暂停. 一个多月来,按照公司要求在做B/S集中式基卫产品的原型,主要是画原型图,开始是用Axure,弄来弄去感觉功能还是弱了些,尤其是 ...
- BZOJ 3707 圈地
闲扯 BZOJ权限题,没有权限,哭了 然后DBZ不知道怎么回事,\(O(n^3)\)直接压过去了... 备忘 叉积的计算公式\(x_1y_2\) 思路 n^3 暴力枚举显然 n^2 正解的思路有点神, ...
- ISE14.7兼容性问题集锦https://www.cnblogs.com/ninghechuan/p/7241371.html
ISE14.7兼容性问题集锦 对于电子工程师来说,很多电路设计仿真软件都是特别大的,安装下来一般都是上G,甚至几十G,而且win7的兼容性也是最好的,不愿意升级win10是因为麻烦,而且没有必要,对于 ...
- C#题目及答案(1)
1. 简述 private. protected. public. internal 修饰符的访问权限. 答 . private : 私有成员, 在类的内部才可以访问. protected : 保护成 ...
- HDU 5988 Coding Contest(浮点数费用流)
http://acm.split.hdu.edu.cn/showproblem.php?pid=5988 题意:在acm比赛的时候有多个桌子,桌子与桌子之间都有线路相连,每个桌子上会有一些人和一些食物 ...
- JMeter中关于动态切换不同CSV文件解决方案
最近写case,需要当前播放节目的数据作为输入数据,所以每个时刻所用的数据只能是当前时刻附件的数据,尝试用CSV Data Set Config动态加载不同的文件,没有成功,好像CSV Data Se ...
- python连接MongoDB(无密码无认证)
无密码无认证下连接 from pymongo import MongoClient host = '127.0.0.1' # 你的ip地址 client = MongoClient(host, ) # ...
- 小程序scss页面布局
html <view class="main"> <form bindsubmit="feedback"> <textarea c ...
- ORACLE SYNONYM详解
以下内容整理自Oracle 官方文档 一 概念 A synonym is an alias for any table, view,materialized view, sequence, proce ...