全景分割pipeline搭建
全景分割pipeline搭建
- 整体方法使用语义分割和实例分割结果,融合标签得到全景分割结果;
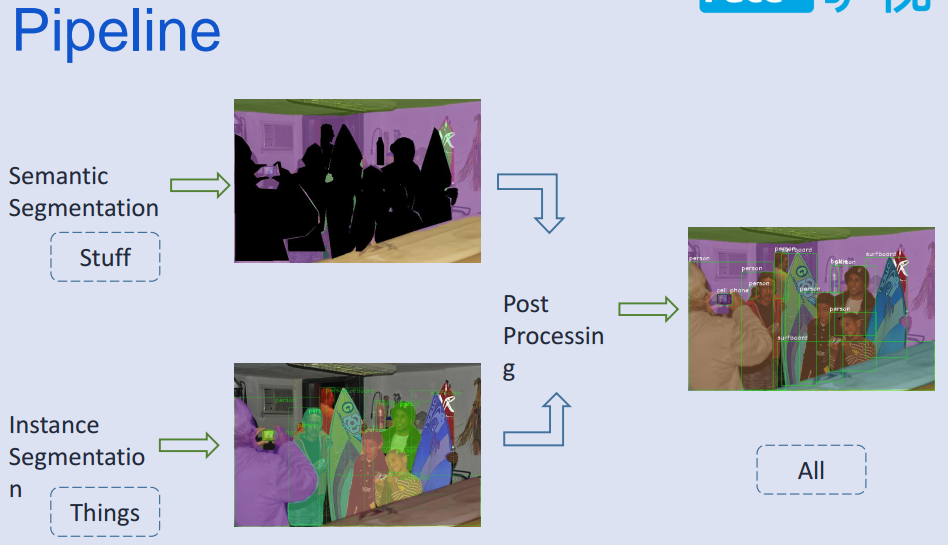
数据集使用:panoptic_annotations_trainval2017和cityscapes;
- panoptic_annotations_trainval2017标签为全景分割的整体标签,之前想打算转换成语义和实例分割标签,在分别做各自任务,由于转换发现有一些格式损坏的样本在里面,需要挑出来才能继续转换,就暂时换成cityscpaes;
- cityscapes:发现val里面,test里面也有一些坑;
实例分割使用:fb最新开源的maskrcnn_benchmark,使用coco格式的数据训练;
语义分割使用:deeplab系列,或者最近很多SOTA(state of the art)的分割paper,且很多开源代码;
了解模型从:数据标签输入格式,输出格式开始,方便直观理解问题!!!分析数据格式及使用api!!!
coco-api
- coco.py
# The following API functions are defined:
# COCO - COCO api class that loads COCO annotation file and prepare data structures.
# decodeMask - Decode binary mask M encoded via run-length encoding.
# encodeMask - Encode binary mask M using run-length encoding.
# getAnnIds - Get ann ids that satisfy given filter conditions.
# getCatIds - Get cat ids that satisfy given filter conditions.
# getImgIds - Get img ids that satisfy given filter conditions.
# loadAnns - Load anns with the specified ids.
# loadCats - Load cats with the specified ids.
# loadImgs - Load imgs with the specified ids.
# annToMask - Convert segmentation in an annotation to binary mask.
# showAnns - Display the specified annotations.
# loadRes - Load algorithm results and create API for accessing them.
# download - Download COCO images from mscoco.org server.
# Throughout the API "ann"=annotation, "cat"=category, and "img"=image.
# Help on each functions can be accessed by: "help COCO>function".
- cocoeval.py
# Interface for evaluating detection on the Microsoft COCO dataset.
#
# The usage for CocoEval is as follows:
# cocoGt=..., cocoDt=... # load dataset and results
# E = CocoEval(cocoGt,cocoDt); # initialize CocoEval object
# E.params.recThrs = ...; # set parameters as desired
# E.evaluate(); # run per image evaluation
# E.accumulate(); # accumulate per image results
# E.summarize(); # display summary metrics of results
cocostuff-api
- stuff:(image,label)分别为:jpg,png,可以直接加载;也有json标注的lable格式可以使用coco.py生成对象;
- 提供:cocoStuffEvalDemo.py; cocoSegmentationToPngDemo.py; pngToCocoResultDemo.py;
- cocoSegmentationToPngDemo: Converts COCO segmentation .json files (GT or results) to one .png file per image.
- pngToCocoResultDemo: Converts a folder of .png images with segmentation results back to the COCO result format.
- 可以研究一下:分割id--color(可视化用);png-->coco结果格式转换;
panoptic-api
- 提供全景分割;语义分割和实例分割结合方法,可视化,评估方法;
- 提供全景分割和语义,实例json文件之间的转换;
cityscapes-api
提供数据label.py
将json转为png(TrainId,InstanId)
evaluation代码很长...;貌似本身的评估代码实在id[0-33]上做的,再考虑忽略的类别;
第三方有:https://github.com/facebookresearch/Detectron/tree/master/tools ;提供cityscape转coco格式代码;
这些数据api真的很让人头昏...代码太长;不好理解...
maskrcnn_benchmark
- coco+cityscape: 需要将cityscapes转成coco格式;然后进行训练;
- cityscapes输出类别为1-8:
category_instancesonly = [
'person',
'rider',
'car',
'truck',
'bus',
'train',
'motorcycle',
'bicycle',
]
- 输出result的格式,针对每个image_id生成多个mask:
[{"category_id": 5, "image_id": 0, "segmentation": {"counts": "b]_`04go08J4L3N2N2N2O0N20001N101O01OO01003N1N1O1O2M3K4I8M2O1O2O0000000000000000000`RObN^l0^1`SOoNUl0P1iSO^Omk0a0QTOLdk05oSOaNN`1Pl0W201O10N1N2N1O1O2N1UOnSO_MJI[l0X2Y1J6K4L6G7K6[Oe0K6I<Dhbb]1", "size": [1024, 2048]}, "score": 0.9218586087226868},
{"category_id": 5, "image_id": 0, "segmentation": {"counts": "]]jf05ho06K4M2gPODjn0>UQOFfn0<YQOFdn0=[QOCdn0<_QOB`n0??2O1N2L4O1O100O101OO10001O1O1OjQOPOZO7jm0f0aROJ`m04_RONbm00^RO0cm00]ROOcm03ZRONgm03RROFOBVn0Y1;N4M5K2M3L4M4L3M3NZbmW1", "size": [1024, 2048]}, "score": 0.8764787316322327},
{"category_id": 5, "image_id": 0, "segmentation": {"counts": "T\\5Q1j0Lfj0KSUOa2dj0g1`UO^KPi0Q6H8I5K3NO10O011O000000O1O1001O00001O1O2N5K6J5K3M5K6J001O1O00O100O1QNgXOWKYg0f4nXOUKSg0j4PYOSKRg0k4QYORKPg0m4VYOmJkf0R5ZYOgJjf0X5Q2N4L2M5fJkUO_4oj0L3N2O1N2N1N2M201O0100ON2N2M3N2M3K6L3K6D<I8_Oa0G8@a0G9H7IYd`m1", "size": [1024, 2048]}, "score": 0.9860864877700806}, {"category_id": 5, "image_id": 0, "segmentation": {"counts": "l\\o:V1fn0?C7J6H?
- 即这样的格式coco reuslt格式:
- 实例分割相比cocostuff多一个score字段;检测结果将segmentation换成box即可;
annotation
[{
"image_id": int,
"category_id": int,
"segmentation": RLE,
"score": float,
}]
- 通过coco.py中loadRes()转换为数据原始(标注格式):补充一些字段
{
"info": info,
"images": [image],
"annotations": [annotation],
"licenses": [license],
}
annotation{
"id": int,
"image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}
categories[{
"id": int,
"name": str,
"supercategory": str,
}]
- cityscapes实例分割instance segmentation实验记录指标:
- Ps:训练coco,cityscapes数据时mAP和官方一直,cityscapes使用coco finetune时调参玄学,多卡lr=0.0001,结果离谱,单卡正确的;
| time | set | data_val | segAP | mAp |
|---|---|---|---|---|
| paper | fine | 0.315 | ||
| paper | fine+coco | 0.365 | ||
| 2018-12-06 | 单卡 | fine | 0.217 | 0.266 |
| 2018-12-11 | 多卡 | fine | 0.238 | 0.278 |
| 2018-12-08 | 单卡 | fine+coco | 0.285 | 0.331 |
| 2018-12-23 | 单卡 | fine | 0.33 | |
| 2018-12-26 | 单卡 | coco+fine | 0.344 | 0.397 |
DeeplabV3_Plus
- 代码风格和deeplab-pytorch类似;
- 使用gtFine_labelIds.png[0-33]当做标签读入;但是会通过下面函数转换到[-1-18],然后就可以直接评估;体会
self._key[index]操作:index为整张图mask[0-33],_key为[-1,18];每个index里面的值去对应_key位置的值; - mask = (gt_image >= 0) & (gt_image < self.num_class)把-1当做unlabel标签;
self._key = np.array([-1, -1, -1, -1, -1, -1,
-1, -1, 0, 1, -1, -1,
2, 3, 4, -1, -1, -1,
5, -1, 6, 7, 8, 9,
10, 11, 12, 13, 14, 15,
-1, -1, 16, 17, 18])
def _class_to_index(self, mask,filename=None):
# assert the values
values = np.unique(mask)
for value in values:
if value not in self._mapping :
print(filename)
assert (value in self._mapping)
index = np.digitize(mask.ravel(), self._mapping, right=True)
return self._key[index].reshape(mask.shape)
- 输出结果和label一样:id值组成,对用color进行可视化;怎么转换为coco格式?
- cityscapes语义分割semantic segmentation实验deeplabv3+记录指标:
- DeeplabV3_Plus训练也很吃劲,首先batchsize上不去,训练的结果和paper也差一截;貌似本身代码还有点问题在issue中有人提出BN参数没有初始化!
| time | set | data_val | mIoU | MPA1 | PA1 |
|---|---|---|---|---|---|
| paper | x-65-val | ~78 | |||
| 2018-12-12 | resnet101-batch-4-513-0.007-30000 | val | ~ | 0.67874 | 0.86852 |
| 2018-12-15 | resnet101-batch4-513-0.01-lossweight | val | 0.4806 | 0.68173 | 0.902740 |
| 2018-12-18 | resnet101-batch8-513-0.007-40000 | val | 0.6886 | 0.78306 | 0.955859 |
| 2018-12-19 | resnet101-batch8-513-0.01-finetune-30000 | val | 0.7006 | 0.7864 | 0.95813 |
deeplab-pytorch
- dataset: cocostuff-10k(IGNORE_LABEL: -1)/164K(IGNORE_LABEL: 255)
- The unlabeled index is 0 in 10k version while 255 in 164k full version.
- 输入在[0,cllass_num]范围的标签;
- 官方推荐Pytorch代码,值得学习:梯度累积,学习率设置,训练方法;
tensorflow-deeplab api
- dataset:cityscapes,pascal_voc_seg,ade20k;
- 官方deeplab代码复现,应该也是有坑的,issue讨论很多;
_CITYSCAPES_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 2975,
'val': 500,
},
num_classes=19,
ignore_label=255,
)
_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 1464,
'train_aug': 10582,
'trainval': 2913,
'val': 1449,
},
num_classes=21,
ignore_label=255,
)
# These number (i.e., 'train'/'test') seems to have to be hard coded
# You are required to figure it out for your training/testing example.
_ADE20K_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 20210, # num of samples in images/training
'val': 2000, # num of samples in images/validation
},
num_classes=151,
ignore_label=0,
)
- 其中cityscapes: 首先通过convert_cityscapes.sh生成[0-18]范围的trainIdImag;这样的label直接训练,评估;但是最终可视化的时候,需要将trainId转化为真实id;
- 即使用:gtFine_labelTrainIds.png进行训练;
# To evaluate Cityscapes results on the evaluation server, the labels used
# during training should be mapped to the labels for evaluation.
_CITYSCAPES_TRAIN_ID_TO_EVAL_ID = [7, 8, 11, 12, 13, 17, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 31, 32, 33]
def _convert_train_id_to_eval_id(prediction, train_id_to_eval_id):
"""Converts the predicted label for evaluation.
There are cases where the training labels are not equal to the evaluation
labels. This function is used to perform the conversion so that we could
evaluate the results on the evaluation server.
Args:
prediction: Semantic segmentation prediction.
train_id_to_eval_id: A list mapping from train id to evaluation id.
Returns:
Semantic segmentation prediction whose labels have been changed.
"""
converted_prediction = prediction.copy()
for train_id, eval_id in enumerate(train_id_to_eval_id):
converted_prediction[prediction == train_id] = eval_id
return converted_prediction
- 该函数就是将输出lable转为color map;体会
colormap[label]的映射关系;
def label_to_color_image(label, dataset=_PASCAL):
"""Adds color defined by the dataset colormap to the label.
Args:
label: A 2D array with integer type, storing the segmentation label.
dataset: The colormap used in the dataset.
Returns:
result: A 2D array with floating type. The element of the array
is the color indexed by the corresponding element in the input label
to the dataset color map.
Raises:
ValueError: If label is not of rank 2 or its value is larger than color
map maximum entry.
"""
if label.ndim != 2:
raise ValueError('Expect 2-D input label')
if np.max(label) >= _DATASET_MAX_ENTRIES[dataset]:
raise ValueError('label value too large.')
colormap = create_label_colormap(dataset)
return colormap[label]
result&&bug
- 使用多线程进行数据转换,可以参考:panoptic-api代码风格;
- maskrcnn训练coco和cityscapes能达到paper指标!使用coco初始化finetune cityscapes训练过程很奇怪,使用两张卡,试了很多中学习率,结果都差的离谱;单卡lr=0.0001/2却能得到正确mAP;
- deeplab-pytorch训练cocostuff10k可能复现github上的结果;
- tensorflow-api可以训练测试,但是测试结果很差!使用官方model也一样;发现语义分割任务对显存消耗很大;
- 目前在可以确认实例分割和语义分割最终呈现形式:json和png的结果;实际应用当然要加更好的可视化效果;
- 目前没有将实例分割和语义分割结果进行结合;
- 再看看panoptic-api使用,语义分割png转成coco格式;
总结
- 最近两个月时间的2018-11-15---2018-12-30的工作;
- 这里面代码细节还有很多没有弄懂,训练方法有有待积累;
- 话说这之前对检测分割的算法了解一些,但是代码基本没有训练过;深入研究才发现,虽说这些方向目前业界发展比较快,貌似可以落地应用;但是这里面的坑太多,paper层出不穷,还有很多细节需要慢慢体会,可能只有真正实际应用才能发现bug太多!!!
- 针对语义分割,发现最近很多paper,还有复现的困难性,网络大,跨GPU-BN等实现;
- 坑太多,暂且打住,以后有具体任务再实践!
reference
- Panoptic Segmentation
- COCO 2018 Panoptic Segmentation Task
- Joint COCO and Mapillary Recognition Challenge Workshop at ECCV 2018
- Mask R-CNN
- Path Aggregation Network for Instance Segmentation
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- 语义分割 - Semantic Segmentation Papers
全景分割pipeline搭建的更多相关文章
- VR大时代-全景智慧城市搭建是一个任重而道远的任务
全景智慧城市搭建是一个任重而道远的任务,但是也促进了实体市场的蓬勃发展与进步.VR技术改变了人们以往的娱乐方式,而全景智慧城市将会彻底改变人们的生活习惯.VR是未来的计算平台,更是人力发展历史中,技术 ...
- VR全景智慧城市搭建掀起实体市场潮流
在互联网时代的今天,用户体验至上,全景智慧城市搭建作为一个新型的科技展示技术,通过新颖的广告方式更能吸引用户眼球,足不出户,观看现场实景,达到沉浸式体验.在这样的大环境下,全景智慧城市搭建开启了VR全 ...
- COCO2018 全景分割
全景分割是18年新推出的一个任务,它要求同时分割出目标和背景,也就是既有实例分割也有语义分割,用官方的话讲是朝着真实世界视觉系统的重要一步 如图所示,里面既有对天空,草地等stuff的分割,也有对目标 ...
- 全景分割:CVPR2019论文解析
全景分割:CVPR2019论文解析 Panoptic Segmentation 论文链接: http://openaccess.thecvf.com/content_CVPR_2019/papers/ ...
- 使用Rancher pipeline搭建基于容器的CICD
CICD概述 CI-持续集成(Continuous Integration):频繁地将代码集成到主干的一种开发实践,每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽早地发现集成错 ...
- Docker学习笔记_08使用Rancher pipeline搭建基于容器的CICD
CICD概述 CI-持续集成(Continuous Integration):频繁地将代码集成到主干的一种开发实践,每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽早地发现集成错 ...
- 全景分割panopticapi使用
文件解析 参考github:https://github.com/cocodataset/panopticapi 输入图像:
- 论文速递 | 实例分割算法BlendMask,实时又state-of-the-art
BlendMask通过更合理的blender模块融合top-level和low-level的语义信息来提取更准确的实例分割特征,该模型效果达到state-of-the-art,但结构十分精简,推理速度 ...
- 自动网络搜索(NAS)在语义分割上的应用(一)
[摘要]本文简单介绍了NAS的发展现况和在语义分割中的应用,并且详细解读了两篇流行的work:DARTS和Auto-DeepLab. 自动网络搜索 多数神经网络结构都是基于一些成熟的backbone, ...
随机推荐
- hdu1255扫描线计算覆盖两次面积
总体来说也是个模板题,但是要开两个线段树来保存被覆盖一次,两次的面积 #include<iostream> #include<cstring> #include<cstd ...
- sharding-jdbc结合mybatis实现分库分表功能
最近忙于项目已经好久几天没写博客了,前2篇文章我给大家介绍了搭建基础springMvc+mybatis的maven工程,这个简单框架已经可以对付一般的小型项目.但是我们实际项目中会碰到很多复杂的场景, ...
- python 全栈开发,Day19(组合,组合实例,初识面向对象小结,初识继承)
一.组合 表示的一种什么有什么的关系 先来说一下,__init__的作用 class Dog: def __init__(self, name, kind, hp, ad): self.name = ...
- zend studio调试
XDdebug搞了我一天 先把php.ini的代码发一下 [XDebug] zend_extension = "d:/WAMP/wamp/bin/php/php5.5.12/zend_ext ...
- k短路([SDOI2010]魔法猪学院)
题解: A*来做 首先对终点向外面跑一遍最短路 然后从起点开始dfs 按照估价函数建立小根堆 每次取出最小的那个继续更新 每次更新到终点cnt++直道cft=k为止 那估价函数怎么弄呢? 其实就是终点 ...
- python学习之集合
集合(set)是一个无序的不重复元素序列. 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典. 创建格 ...
- Python字符串相加以及字符串格式化
1.在Python中字符串a占用一块内存地址,字符串b也占用一块内存地址,当字符串a+b时,又会在内存空间中开辟一块新的地址用来存放a+b. a 地址一 b 地址二 a+b 地址三 因此内存中就占了三 ...
- Docker 注意事项
一.Dockerfile名字不能是大写. 二.Docker-compares 引用自:https://www.cnblogs.com/wj5633/p/6707012.html 引用自:https:/ ...
- 关于MIS 系统所需技术和含义
操作系统的作用在于 1资源管理 2人机交互.它提供各个应用软件的运行平台,也为用户提供交互界面.所需技术:一.b/s架构B/S结构即浏览器和服务器结构,在这种结构下,用户工作界面是通过WWW浏览器来实 ...
- FZU 2150 Fire Game(双起点)【BFS】
<题目链接> 题目大意: 两个熊孩子在n*m的平地上放火玩,#表示草,两个熊孩子分别选一个#格子点火,火可以向上向下向左向右在有草的格子蔓延,点火的地方时间为0,蔓延至下一格的时间依次加一 ...