从零搭建ES搜索服务(一)基本概念及环境搭建
一、前言
本系列文章最终目标是为了快速搭建一个简易可用的搜索服务。方案并不一定是最优,但实现难度较低。
二、背景
近期公司在重构老系统,需求是要求知识库支持全文检索。
我们知道普通的数据库 like 方式效果及性能都不好,所以另寻出路,确定通过 Elasticsearch (下文简称「 ES 」)搜索引擎实现。
三、技术选型
因公司之前购买了阿里云的ES服务且版本为 5.5.3 ,下文选用的技术框架均基于此版本。
① Elasticsearch 5.5.3
一个基于Lucene的搜索服务器,提供了分布式的全文搜索引擎
② Logstash 5.5.3
开源的服务器端数据处理管道
③ Kibana 5.5.3
开源的分析和可视化平台
④ Spring Boot 2.0.4
四、系统环境
- Linux Centos 7.3
- JDK 1.8
五、基本概念
5.1 集群( cluster )
集群是由一个或者多个拥有相同 cluster.name 配置的节点组成,共同承担数据和负载压力,当节点数量发生变化时集群将会重新平均分布所有数据。
5.2 节点( node )
一个运行中的 ES 实例称为一个节点
- 主节点负责管理集群范围内的所有变更,例如增加/删除索引,或者增加/删除节点等,且不需要涉及到文档级别的变更和搜索等操作
- 任何节点都能成为主节点
- 当集群只有一个主节点,即使流量增加也不会成为瓶颈
5.3 索引( index )
名词;类似于传统关系数据库中的一个数据库动词;索引一个文档就是存储一个文档到一个索引(名词)中以便它可以被检索和查询到。类似于 SQL 语句中的 INSERT 关键词倒排索引;类似于传统关系型数据库中的索引概念,可以提升数据检索速度
5.4 类型( type )
一个索引包含一个或多个 type ,相当于传统关系型数据库中的表
5.5 文档( document )
相当于传统关系型数据库中的数据行
5.6 分片( shards )
- 是一个底层的
「工作单元」,仅保存了全部数据的一部分 - 是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里
- 当集群规模扩大或者缩小时, ES 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里
- 分为
「主分片」和「副本分片」 - 在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改;默认情况下会被分配「 5 」个主分片和「 1 」份副本(每个主分片拥有一个副本分片)
- 相同主分片的副本分片不会放在同一个节点
① 主分片 ( Primary shard )
索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量
② 副本分片( Replica shard )
只是一个主分片的拷贝,作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务
六、环境搭建
6.1 Elasticsearch
6.1.1 安装步骤
① 下载安装包:
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.3.tar.gz
② 解压并移动到 local 目录下
$ tar -zxvf elasticsearch-5.5.3.tar.gz
$ mv elasticsearch-5.5.3 /usr/local/elasticsearch
③ 修改 config 目录下的 elasticsearch.yml 文件
$ vim elasticsearch.yml
// 去掉行开头的 # 并重命名集群名,这里命名为 compass
cluster.name: compass
// 去掉行开头的 # 并重命名节点名,这里命名为 node-1
node.name: node-1
④ 进入 bin 目录启动 ES 并在后台运行
$ ./elasticsearch -d
⑤ 启动之后测试是否正常运行
$ curl 127.0.0.1:9200
返回结果:
{
"name" : "node-1",
"cluster_name" : "compass",
"cluster_uuid" : "Zuj5FBMUTjuHQXlAHreGvA",
"version" : {
"number" : "5.5.3",
"build_hash" : "9305a5e",
"build_date" : "2017-09-07T15:56:59.599Z",
"build_snapshot" : false,
"lucene_version" : "6.6.0"
},
"tagline" : "You Know, for Search"
}
6.1.2 如果提示「-bash: wget: command not found」则需要先安装 wget
$ yum -y install wget
6.1.3 ES 版本> = 5.0.0 时,是不能用超级管理员运行的,此时需要切换到普通账号或者新建 ES 账号
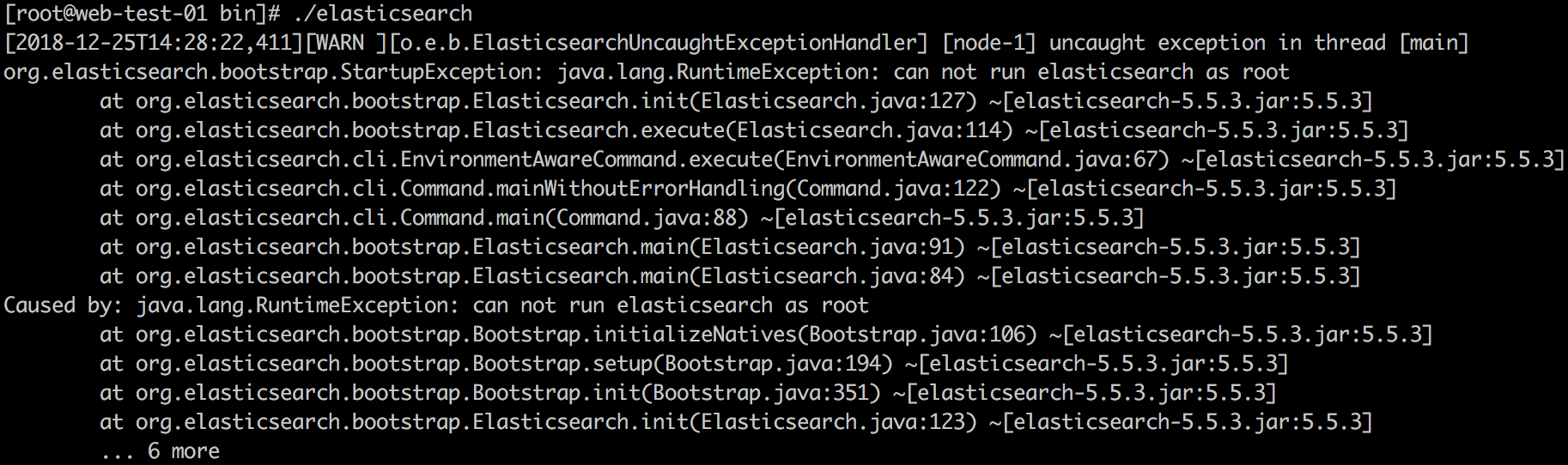
解决办法:
① 新建用户组 elasticsearch
$ groupadd elasticsearch
② 新建用户并指定用户组
$ useradd -g elasticsearch elasticsearch
③ 修改 ES 目录所属者
$ chown -R elasticsearch:elasticsearch elasticsearch
④ 切换用户后再次启动
$ su elasticsearch
6.1.4 只能使用127.0.01或者localhost访问,使用ip地址无法访问?
解决办法:
① 修改 elasticsearch.yml 中的「network.host」
network.host: 0.0.0.0
② 重启 ES 出现如果如下报错,请依次按下面的步骤解决
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max number of threads [3818] for user [elasticsearch] is too low, increase to at least [4096]
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
每个进程最大同时打开文件数太小
修改 /etc/security/limits.conf 文件,增加如下配置,用户退出后重新登录生效
* soft nofile 65536
* hard nofile 65536
[2]: max number of threads [3818] for user [es] is too low, increase to at least [4096]
最大线程个数太低
同上修改 /etc/security/limits.conf 文件,增加如下配置,用户退出后重新登录生效
* soft nproc 4096
* hard nproc 4096
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
一个进程能拥有的最多的内存区域
修改 /etc/sysctl.conf 文件,增加如下配置,执行命令「 sysctl -p 」生效
vm.max_map_count=262144
③ 切换到 elasticsearch 用户并重启, curl 测试成功
[root@db-develop-01 ~]$ curl 192.168.1.192:9200
{
"name" : "node-1",
"cluster_name" : "compass",
"cluster_uuid" : "mFL_a6WDTUaWbB4jKA8cWg",
"version" : {
"number" : "5.5.3",
"build_hash" : "9305a5e",
"build_date" : "2017-09-07T15:56:59.599Z",
"build_snapshot" : false,
"lucene_version" : "6.6.0"
},
"tagline" : "You Know, for Search"
}
6.2 Logstash
① 下载安装包:
$ wget https://artifacts.elastic.co/downloads/logstash/logstash-5.5.3.tar.gz
② 解压并移动到 local 目录下
$ tar -zxvf logstash-5.5.3.tar.gz
$ mv logstash-5.5.3 /usr/local/logstash
6.3 Kibana
① 下载安装包:
$ wget https://artifacts.elastic.co/downloads/kibana/kibana-5.5.3-linux-x86_64.tar.gz
② 解压并移动到 local 目录下
$ tar -zxvf kibana-5.5.3-linux-x86_64.tar.gz
$ mv kibana-5.5.3-linux-x86_64 /usr/local/kibana
③ 修改 config 目录下的 kibana.yml 文件
// 去掉当前行开头的 #
server.port: 5601
// 去掉当前行开头的#并将localhost修改为具体IP
server.host: "192.168.1.191"
// 去掉当前行开头的#并将localhost修改为具体IP
elasticsearch.url: "http://192.168.1.191:9200"
④ 启动 Kibana ,浏览器访问 http://192.168.1.191:5601
$ ./kibana
6.4 elasticsearch-head 插件(浏览器版)
① 「 Chrome 浏览器网上应用商店」或者「 Firefox 附加组件」搜索 elasticsearch head
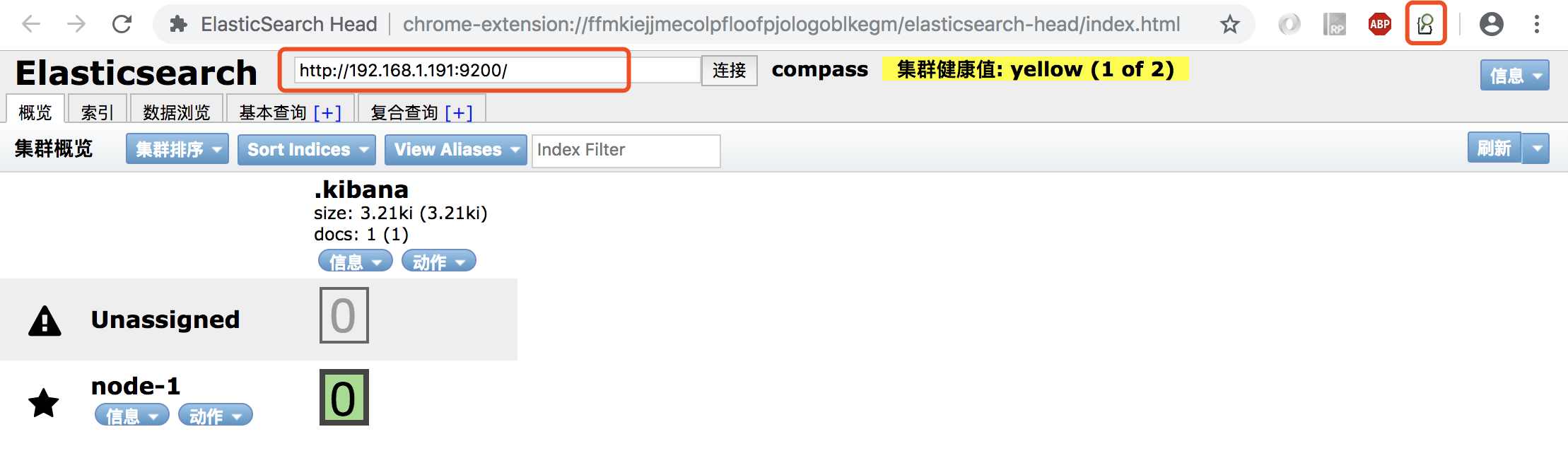
② 安装插件后点击浏览器地址栏右侧「放大镜图标」,顶部输入框中的 localhost 修改为服务器地址即可查看 ES 服务状态
七、结语
至此 ELK 环境搭建完毕,下一篇具体介绍如何实现基础搜索服务。
从零搭建ES搜索服务(一)基本概念及环境搭建的更多相关文章
- 从零搭建 ES 搜索服务(二)基础搜索
一.前言 上篇介绍了 ES 的基本概念及环境搭建,本篇将结合实际需求介绍整个实现过程及核心代码. 二.安装 ES ik 分析器插件 2.1 ik 分析器简介 GitHub 地址:https://git ...
- 从零搭建 ES 搜索服务(五)搜索结果高亮
一.前言 在实际使用中搜索结果中的关键词前端通常会以特殊形式展示,比如标记为红色使人一目了然.我们可以通过 ES 提供的高亮功能实现此效果. 二.代码实现 前文查询是通过一个继承 Elasticsea ...
- 从零搭建 ES 搜索服务(六)相关性排序优化
一.前言 上篇介绍了搜索结果高亮的实现方法,本篇主要介绍搜索结果相关性排序优化. 二.相关概念 2.1 排序 默认情况下,返回结果是按照「相关性」进行排序的--最相关的文档排在最前. 2.1.1 相关 ...
- 从零搭建 ES 搜索服务(三)同义词搜索
一.前言 上篇介绍了 ES 的基础搜索,能满足我们基本的需求,然而在实际使用中还可能希望搜索「番茄」能将包含「西红柿」的结果也罗列出来,本篇将介绍如何实现同义词之间的搜索. 二.安装 ES 同义词插件 ...
- 从零搭建 ES 搜索服务(四)拼音搜索
一.前言 上篇介绍了 ES 的同义词搜索,使我们的搜索更强大了,然而这还远远不够,在实际使用中还可能希望搜索「fanqie」能将包含「番茄」的结果也罗列出来,这就涉及到拼音搜索了,本篇将介绍如何具体实 ...
- 若依微服务版本 Windows下开发环境搭建
看了若依官网的教程,搭建环境还是踩了坑,简单整理一下 1.下载地址:https://gitee.com/y_project/RuoYi-Cloud 2.本地环境(仅供参考) JDK1.8 Mysql ...
- Go语言学习之1 基本概念、环境搭建、第一个Go程序
一.环境搭建 见我的这篇博客 https://www.cnblogs.com/xuejiale/p/10258244.html 二.golang语言特性1. 垃圾回收 1) 内存自动回收,再也不 ...
- Elasticsearch技术解析与实战(一)基础概念及环境搭建
序言 ES数据架构的主要概念(与关系数据库Mysql对比) 集群(cluster) 集群,一个ES集群由一个或多个节点(Node)组成,每个集群都有一个cluster name作为标识.一下是我们的4 ...
- eclipse开发cocos2dx 3.2环境搭建之中的一个: Android C\C++环境搭建(ndk r9d)
这几天有时间,琢磨一下cocos2dx.cocos2d家族事实上挺庞大的.也有cocos2d-android这样的能够直接用Java语言来开发的,可是cocos2d-android资料相对少一些.并且 ...
随机推荐
- Java的三种代理模式:静态代理/JDK动态代理/Cglib动态代理
1.静态代理:需要定义接口或者父类,目标对象与代理对象均实现同一接口或继承同一父类. 2.JDK动态代理:需要目标对象实现一个接口,通过动态反射的机制,生成代理对象,实现同一个接口 3.Cglib动态 ...
- Android的网络通信机制
1. Socket接口 不常用 2.HttpURLConnection接口 3. HttpClient接口 http://blog.csdn.net/ccc20134/article/details/ ...
- SpringMVC与Struts不同(五)
springmvc与struts2不同 1.springmvc的入口是一个servlet即前端控制器,而struts2入口是一个filter过滤器. 2.springmvc是基于方法开发(一个url对 ...
- cmake 使用
1.cmake 显示编译命令: 在顶层CMakeLists.txt里设置 set(CMAKE_VERBOSE_MAKEFILE ON) 或者 cmake . 再 m ...
- Python3学习笔记09-字典
字典是另一种可变容器模型,且可存储任意类型对象. 字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 键必须是唯一的,但值则不必 ...
- SQLServer语言之DDL,DML,DCL,TCL
数据库语言分类 SQLServer SQL主要分成四部分: (1)数据定义.(SQL DDL)用于定义SQL模式.基本表.视图和索引的创建和撤消操作. (2)数据操纵.(SQL DML)数据操纵分 ...
- Win10 + VS2017 15.5.6 环境下解决 Python 3.6 环境无法刷新DB的问题
作为宇宙第一IDE,VS2017对Python的支持还算可以,虽然和PyCharm等Python专用IDE相比还有些差距,但是经过后续的更新升级,我相信VS2017将越来越完善.由于本人一直都是使用V ...
- 026_关于shell中的特殊变量$0 $n $* $@ $! $?
一. $n:获取当前执行的shell脚本的第N个参数,n=1..9,当n为0时表示脚本的文件名,如果n大于9,用大括号括起来like${10}. $*:获取当前shell的所有参数,将所有的命令行参数 ...
- 005_nginx414_nginx 414 Request-URI Too Large
一.开发请求一个非常长的请求参数 https://jiaju.jyall.me/backend/dish/getSales/?dishId=167271&dishId=166975&d ...
- LVS负载均衡器DR模型的实现
概述: 在大规模互联网应用中,负载均衡设备是必不可少的一个节点,源于互联网应用的高并发和大流量的冲击压力,我们通常会在服务端部署多个无状态的应用服务器和若干有状态的存储服务器(数据库.缓存等等) 一. ...