Java线程池深入理解
之前面试baba系时遇到一个相对简单的多线程编程题,即"3个线程循环输出ADC",自己答的并不是很好,深感内疚,决定更加仔细的学习《并发编程的艺术》一书,到达掌握的强度。(之前两月休息时间都花在了lol和吃鸡上,算是劳逸结合了,推荐大家代码写累了可以玩下吃鸡,是个不错的调剂)
流程分析
Java的线程池是最常用的并发框架,合理的使用线程池可以降低系统消耗、提高响应速度、提高线程的可管理性。线程池的基础处理流程如下图所示。

上图中标红的4处正好是构建线程池的核心,核心线程池大小,队列,线程池大小,拒绝策略4个部分。通常来说,会根据当前系统的CPU数量来设置线程大小,并且一个应用中共用一个线程池,便于管理,过多的线程因为调度切换的原因,反而不能提高系统资源的利用率,如下是个人常用线程池管理类,不过现在对于AtomicReference的用法不是特别理解。
/**
* 单个应用共用一个线程池,便于管理
*/
public class ApplicationExecutorFactory {
private static AtomicReference<ExecutorService> serviceRef = new AtomicReference<>(
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() * 2));
public static ExecutorService getExecutor() {
return serviceRef.get();
}
public static void shutdown() {
if (serviceRef.get() == null)
return;
synchronized (ApplicationExecutorFactory.class) {
if (serviceRef.get() == null)
return;
serviceRef.get().shutdown();
serviceRef.set(null);
}
}
}
接下来来看看最常用的固定大小线程newFixedThreadPool()的构造方法,可以看到下面代码中,核心线程池大小和线程池最大大小是一致的,队列使用的链表形式的阻塞队列(默认大小为Int最大值),线程工厂DefaultThreadFactory和拒绝处理器AbortPolicy也是使用的默认的。
//按照层次剖析,涉及类Executors, ThreadPoolExecutor, LinkedBlockingQueue
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public static ThreadFactory defaultThreadFactory() {
return new DefaultThreadFactory();
}
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
Tip:
这个引入几个问题来加强学习。
a.阻塞队列(也叫任务队列)的类型有哪些?队列大小为Integer.MAX_VALUE合适么?什么是有界队列,什么是无界队列?无界队列是不是会造成maximuxPoolSize失效?
ArrayBlockingQueue: 基于数组结构的有界阻塞队列,遵循FIFO
LinkedBlockingQueue:基于链表的阻塞队列,吞吐量一般高于ArrayBlockingQueue,固定大小的线程池就是使用的该队列。
SynchronousQueue: 一个不存储元素的阻塞队列(有意思),每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直阻塞。吐吞量Ibanez高于LinkedBlockingQueue,CachedThreadPool使用了该队列,目前 还没有很好的理解?
PriorityBlockingQueue: 一个具有优先级的无限阻塞队列。
b.如果希望给线程池中线程取名怎么办?
使用guava的ThreadFactoryBuilder可以快速的给线程池里线程设置有意义名字。
c.线程池除了固定大小的,还有哪些类型,根据场景如何取舍?(该问题将在Executor一节回答)
d.拒绝策略(也叫饱和策略)有哪些?
AbortPolicy: 直接抛出异常
CallerRunsPolicy: 只用调用者所在线程来运行任务,如何理解?
DiscardOldestPolicy:丢弃队列最老任务,并执行当前任务
DiscardPolicy:直接抛弃不处理
此外,还可以根据场景需要自己来实现RejectedExecutionHandler接口,来记录日志或持久化存储不能处理的任务。
e.keepAliveTime, TimeUnit参数有什么用?该参数决定工作线程空闲后存活的时间,对于任务很多但单个任务执行时间短的场景,可以调大时间提高利用率,看到这可以发现很多中间件都可以做出来。
运行机制
接下来通过下图更进一步了解线程池的运行机制。
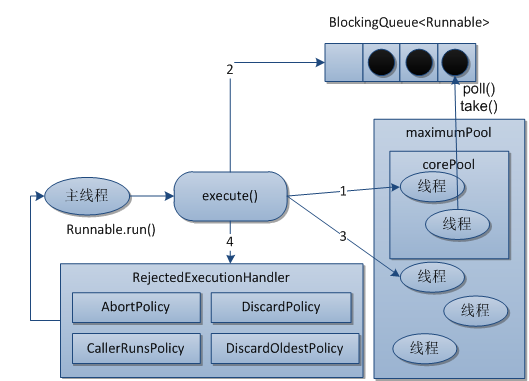
1.如果当前运行的线程少于corePoolSize直接创建新线程来执行任务,需要获取全局锁。
2.如果运行的线程等于或多余corePoolSize则将任务加入BlockingQueue。
3.如果由于队列已满,无法将任务加到BlockingQueue,则创建新的线程来处任务,需要获取全局锁。
4.如果创建新线程将操作maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
ThreadPoolExecutor采用上述步骤,保证了执行execute()时,尽可能的避免了获取全局锁,大部分的可能都会执行步骤2,而无需获取全局锁。上图就是通过下面的源代码形象化出来的。
//老版本JDK,便于理解
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//由于是或条件运算符,所以先计算前半部分的值,如果线程池中当前线程数不小于核心池大小
//,那么就会直接进入下面的if语句块了。
//如果线程池中当前线程数小于核心池大小,则接着执行后半部分,也就是执行
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
//如果当前线程池处于RUNNING状态,则将任务放入任务缓存队列;
if (runState == RUNNING && workQueue.offer(command)) {
//这句判断是为了防止在将此任务添加进任务缓存队列的同时其他线程突然调用shutdown
//或者shutdownNow方法关闭了线程池的一种应急措施
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
//如果当前线程池不处于RUNNING状态或者任务放入缓存队列失败,则执行
else if (!addIfUnderMaximumPoolSize(command))
reject(command); // is shutdown or saturated
}
}
private boolean addIfUnderCorePoolSize(Runnable firstTask) {
Thread t = null;
//首先获取到锁,因为这地方涉及到线程池状态的变化,先通过if语句判断当前线程池中的线程数目是否小于核心池大小,
//有朋友也许会有疑问:前面在execute()方法中不是已经判断过了吗,只有线程池当前线程数目小于核心池大小才会执行addIfUnderCorePoolSize方法的,为何这地方还要继续判断?
//原因很简单,前面的判断过程中并没有加锁,因此可能在execute方法判断的时候poolSize小于corePoolSize,而判断完之后,
//在其他线程中又向线程池提交了任务,就可能导致poolSize不小于corePoolSize了,所以需要在这个地方继续判断。
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (poolSize < corePoolSize && runState == RUNNING)
t = addThread(firstTask); //创建线程去执行firstTask任务
} finally {
mainLock.unlock();
}
if (t == null)
return false;
t.start();
return true;
}
//在addThread方法中,首先用提交的任务创建了一个Worker对象,然后调用线程工厂threadFactory创建了一个新的线程t,
//然后将线程t的引用赋值给了Worker对象的成员变量thread,接着通过workers.add(w)将Worker对象添加到工作集当中。
private Thread addThread(Runnable firstTask) {
Worker w = new Worker(firstTask);
Thread t = threadFactory.newThread(w); //创建一个线程,执行任务
if (t != null) {
w.thread = t; //将创建的线程的引用赋值为w的成员变量
workers.add(w);
int nt = ++poolSize; //当前线程数加1
if (nt > largestPoolSize)
largestPoolSize = nt;
}
return t;
}
private final class Worker implements Runnable {
private final ReentrantLock runLock = new ReentrantLock();
private Runnable firstTask;
volatile long completedTasks;
Thread thread;
Worker(Runnable firstTask) {
this.firstTask = firstTask;
}
boolean isActive() {
return runLock.isLocked();
}
void interruptIfIdle() {
final ReentrantLock runLock = this.runLock;
if (runLock.tryLock()) {
try {
if (thread != Thread.currentThread())
thread.interrupt();
} finally {
runLock.unlock();
}
}
}
void interruptNow() {
thread.interrupt();
}
private void runTask(Runnable task) {
final ReentrantLock runLock = this.runLock;
runLock.lock();
try {
if (runState < STOP &&
Thread.interrupted() &&
runState >= STOP)
boolean ran = false;
beforeExecute(thread, task); //beforeExecute方法是ThreadPoolExecutor类的一个方法,没有具体实现,用户可以根据
//自己需要重载这个方法和后面的afterExecute方法来进行一些统计信息,比如某个任务的执行时间等
try {
task.run();
ran = true;
afterExecute(task, null);
++completedTasks;
} catch (RuntimeException ex) {
if (!ran)
afterExecute(task, ex);
throw ex;
}
} finally {
runLock.unlock();
}
}
public void run() {
try {
Runnable task = firstTask;
// 从run方法的实现可以看出,它首先执行的是通过构造器传进来的任务firstTask,在调用runTask()执行完firstTask之后,
//在while循环里面不断通过getTask()去取新的任务来执行,那么去哪里取呢?自然是从任务缓存队列里面去取,
//getTask是ThreadPoolExecutor类中的方法,并不是Worker类中的方法,下面是getTask方法的实现:
firstTask = null;
while (task != null || (task = getTask()) != null) {
runTask(task);
task = null;
}
} finally {
workerDone(this); //当任务队列中没有任务时,进行清理工作
}
}
}
Runnable getTask() {
for (;;) {
try {
int state = runState;
if (state > SHUTDOWN)
return null;
Runnable r;
if (state == SHUTDOWN) // Help drain queue
r = workQueue.poll();
else if (poolSize > corePoolSize || allowCoreThreadTimeOut) //如果线程数大于核心池大小或者允许为核心池线程设置空闲时间,
//则通过poll取任务,若等待一定的时间取不到任务,则返回null
r = workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS);
else
r = workQueue.take();
if (r != null)
return r;
if (workerCanExit()) { //如果没取到任务,即r为null,则判断当前的worker是否可以退出
if (runState >= SHUTDOWN) // Wake up others
interruptIdleWorkers(); //中断处于空闲状态的worker
return null;
}
// Else retry
} catch (InterruptedException ie) {
// On interruption, re-check runState
}
}
}
//JDK1.8
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
Tip:
这个引入几个问题来加强学习。
a.这儿的全局锁如何理解?
b.线程池有哪些状态
在ThreadPoolExecutor中定义了一个volatile变量,另外定义了几个static final变量表示线程池的各个状态(JDK1.5,1.8做的更加复杂不适合表述)。
volatile int runState;
static final int RUNNING = 0;
static final int SHUTDOWN = 1;
static final int STOP = 2;
static final int TERMINATED = 3;
runState表示当前线程池的状态,它是一个volatile变量用来保证线程之间的可见性,下面的几个static final变量表示runState可能的几个取值。
当创建线程池后,初始时,线程池处于RUNNING状态;
如果调用了shutdown()方法,则线程池处于SHUTDOWN状态,此时线程池不能够接受新的任务,它会等待所有任务执行完毕;
如果调用了shutdownNow()方法,则线程池处于STOP状态,此时线程池不能接受新的任务,并且会去尝试终止正在执行的任务;
当线程池处于SHUTDOWN或STOP状态,并且所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为TERMINATED状态。
补充知识与自制线程池
提交任务:execute(), submit()提交有返回值的任务
关闭线程池:shutdown, shutdownNow它们均是遍历线程池中的工作线程,逐个调用interrupt方法来中断线程,所有无法响应中断的任务永远无法停止。前者将线程池状态设置为SHUTDOWN,然后中断没有执行任务的线程,而后者会将状态设置为STOP,然后尝试停止所有正在执行或者暂停执行的线程,并返回等待执行任务的列表。当所有任务都关闭后,才表示线程关闭成功,这是isTerminated返回成功。
线程池的选择:通常来说,性质不同的任务可用不同规模的线程池分开处理,CPU密集型的任务应配置尽可能小的线程,而IO密集型可以配置尽可能多的,混合型的任务最好将任务拆分后再做权衡。
对于数据库请求和服务请求这类IO密集型的操作,可以将线程池设置的相对较大,具体根据线上的情况做权衡(平均耗时)。
队列的选择:建议使用有界队列,避免线程池耗尽整个系统的资源,当然这时就需要很好的提供饱和策略了。
接下来,分享一个个人通过对线程池核心原理的分析,自制的简化线程池。
public class CustomThreadPool implements ExecutorService {
/**
* 线程池状态部分
*/
volatile int runState;
static final int RUNNING = 0;
static final int SHUTDOWN = 1;
static final int STOP = 2;
static final int TERMINATED = 3;
/**
* 线程池基础参数部分
*/
int coreMaxSize;// 最大线程池大小和最大核心线程大小一样,简化
final BlockingQueue<Runnable> queue;
RejectedExecutionHandler handler;
// 线程池不是简单的使用一个List<Thread>管理,而是借助一个Worker的概念,Worker需要线程和Task两个因素才能工作
// 想想生产线的工人Worker,task比如是生产一个手套,线程比如就是一个机械臂,可以选择一个空闲的机械臂进行生产
final HashSet<CustomWorker> workers = new HashSet<CustomWorker>();
final ReentrantLock mainLock = new ReentrantLock();// 线程池的主要状态锁,对线程池状态(大小,runstate)
private volatile ThreadFactory threadFactory; // 线程工厂,用来创建线程
public CustomThreadPool() {
runState = RUNNING;
coreMaxSize = 4;
queue = new CustomBlockingQueue(100);
handler = new CustomRejectedExecutionHandler();
threadFactory = new ThreadFactoryBuilder().setNameFormat("").build();
}
@Override
public void execute(Runnable command) {
// 1.判断线程池是否已满
if (getCurSize() <= coreMaxSize && runState == RUNNING) {
createWorker(command);
return;
}
// 2.判断队列是否满了
if (getCurSize() <= coreMaxSize && runState == RUNNING) {
enqueue(command);
return;
}
// 3.判断线程池子是否满了,省略
// 4.按照饱和策略做处理
rejectHandle(command);
}
private void createWorker(Runnable command) {
CustomWorker worker = new CustomWorker();
Thread thd = threadFactory.newThread(command);
worker.setThread(thd);
mainLock.lock();
try {
workers.add(worker);
} finally {
mainLock.unlock();
}
worker.run();
}
private void rejectHandle(Runnable command) {
// handler.rejectedExecution(command, this);
}
private boolean enqueue(Runnable command) {
return queue.add(command);
}
private int getCurSize() {
mainLock.lock();
try {
return workers.size();
} finally {
mainLock.unlock();
}
}
@Override
public void shutdown() {
for (CustomWorker worker : workers) {
worker.interrupt();
}
}
}
面试题
1."3个线程循环输出ADC"?
a.通过Object对象实现
public class ABCDemo {
public static void test() {
Object lockA = new Object();
Object lockB = new Object();
Object lockC = new Object();
Thread thA = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
System.out.println("A线程获取C锁");
synchronized (lockC) {
System.out.println("A线程开始等待C锁信号");
lockC.wait();
System.out.println("A线程结束等待C锁信号");
}
System.out.println("A线程释放C锁");
System.out.println("A");
System.out.println("A线程获取A锁");
synchronized (lockA) {
System.out.println("A线程开始发送A锁信号");
lockA.notify();
System.out.println("A线程结束发送A锁信号");
}
System.out.println("A线程释放A锁");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
Thread thB = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
System.out.println("B线程获取A锁");
synchronized (lockA) {
System.out.println("B线程开始等待A锁信号");
lockA.wait();
System.out.println("B线程结束等待A锁信号");
}
System.out.println("B线程释放A锁");
System.out.println("B");
System.out.println("B线程获取B锁");
synchronized (lockB) {
System.out.println("B线程开始发送B锁信号");
lockB.notify();
System.out.println("B线程结束发送B锁信号");
}
System.out.println("B线程释放B锁");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
Thread thC = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
System.out.println("C线程获取B锁");
synchronized (lockB) {
System.out.println("C线程开始等待B锁信号");
lockB.wait();
System.out.println("C线程结束等待B锁信号");
}
System.out.println("C线程释放B锁");
System.out.println("C");
System.out.println("C线程获取C锁");
synchronized (lockC) {
System.out.println("C线程开始发送C锁信号");
lockC.notify();
System.out.println("C线程结束发送C锁信号");
}
System.out.println("C线程释放C锁");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
System.out.println("主线程开启A线程");
thA.start();
System.out.println("主线程开启B线程");
thB.start();
System.out.println("主线程开启C线程");
thC.start();
System.out.println("主线程获取C锁");
synchronized (lockC) {
System.out.println("主线程开始发送C锁信号");
lockC.notify();
System.out.println("主线程结束发送C锁信号");
}
System.out.println("主线程释放C锁");
}
}
b.通过ReentrantLock实现(在ReentrantLock一章实现)
参考资料
- 方腾飞. Java并发编程的艺术[M]. 上海:机械工业出版社, 2017.
- 推荐博文--Java并发编程:线程池的使用
Java线程池深入理解的更多相关文章
- Java并发编程与技术内幕:线程池深入理解
摘要: 本文主要讲了Java当中的线程池的使用方法.注意事项及其实现源码实现原理,并辅以实例加以说明,对加深Java线程池的理解有很大的帮助. 首先,讲讲什么是线程池?照笔者的简单理解,其实就是一组线 ...
- 转:Java并发编程与技术内幕:线程池深入理解
版权声明:本文为博主林炳文Evankaka原创文章,转载请注明出处http://blog.csdn.net/evankaka 目录(?)[+] ); } catch (InterruptedExcep ...
- 死磕 java线程系列之线程池深入解析——普通任务执行流程
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 注:线程池源码部分如无特殊说明均指ThreadPoolExecutor类. 简介 前面我们一起学习了Java中 ...
- 死磕 java线程系列之线程池深入解析——未来任务执行流程
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 注:线程池源码部分如无特殊说明均指ThreadPoolExecutor类. 简介 前面我们一起学习了线程池中普 ...
- 干货,阿里P8浅谈对java线程池的理解(面试必备)
线程池的概念 线程池由任务队列和工作线程组成,它可以重用线程来避免线程创建的开销,在任务过多时通过排队避免创建过多线程来减少系统资源消耗和竞争,确保任务有序完成:ThreadPoolExecutor ...
- 死磕 java线程系列之线程池深入解析——体系结构
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 简介 Java的线程池是块硬骨头,对线程池的源码做深入研究不仅能提高对Java整个并发编程的理解,也能提高自己 ...
- 死磕 java线程系列之线程池深入解析——生命周期
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 注:线程池源码部分如无特殊说明均指ThreadPoolExecutor类. 简介 上一章我们一起重温了下线程的 ...
- 死磕 java线程系列之线程池深入解析——定时任务执行流程
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 注:本文基于ScheduledThreadPoolExecutor定时线程池类. 简介 前面我们一起学习了普通 ...
- 死磕 java线程系列之线程池深入解析——构造方法
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 简介 ThreadPoolExecutor的构造方法是创建线程池的入口,虽然比较简单,但是信息量很大,由此也能 ...
随机推荐
- Navicat Premium连接各种数据库
版本信息 Navicat Premium 是一套数据库开发工具,让你从单一应用程序中同时连接 MySQL.MariaDB.SQL Server.Oracle.PostgreSQL 和 SQLite 数 ...
- SpringBoot2.x过滤器Filter和使用Servlet3.0配置自定义Filter实战
补充:SpringBoot启动日志 1.深入SpringBoot2.x过滤器Filter和使用Servlet3.0配置自定义Filter实战(核心知识) 简介:讲解SpringBoot里面Filter ...
- pl/sql Devloper 快捷键__新建sql窗口
首先,打开PLSQL,菜单栏--->首选项----->键配置 其次,点击你要增加快捷键的选项,直接键盘上输入快捷键: 比如你要修改为CTRL+N,直接在键盘上按出CTRL+N即可. ESC ...
- Faster rcnn代码理解(3)
紧接着之前的博客,我们继续来看faster rcnn中的AnchorTargetLayer层: 该层定义在lib>rpn>中,见该层定义: 首先说一下这一层的目的是输出在特征图上所有点的a ...
- Kernel 3.0.8 内存管理函数【转】
转自:http://blog.csdn.net/myarrow/article/details/7208777 1. 内存分配函数 相关代码如下: #define alloc_pages(gfp_ma ...
- 驱动开发--【字符设备、块设备简介】【sky原创】
驱动开发 字符设备,块设备,网络设备 字符设备 以字节流的方式访问, 不能随机访问 有例外,显卡.EEPROM可以随机访问 EEPROM可以擦写1亿次,是一种字符设备,可以随机访问 读写是 ...
- 调用链系列二、Zipkin 和 Brave 实现(springmvc、RestTemplate)服务调用跟踪
Brave介绍 1.Brave简介 Brave 是用来装备 Java 程序的类库,提供了面向标准Servlet.Spring MVC.Http Client.JAX RS.Jersey.Resteas ...
- ubuntu数据库迁移
环境:ubuntu16.04 简介:本教程演示如何从旧数据库服务器服转移到另一个新服务器. 场景:假设你有自己的云服务器安装了WordPress站点,你为了更多的内存和处理能力想升级到新的服务器. 操 ...
- root权限使用vim不能修改权限
1.背景: 有时候我们会发现使用root权限不能修改某个文件,大部分原因是曾经使用chattr将文件锁定了 2.chattr命令介绍: 用来改变文件属性,能防止root用户误删文件等作用 3.使用方法 ...
- lvs基本概念、调度方法、ipvsadm命令及nat模型示例
LVS类型: NAT:-->(DNAT) DR TUN FULLNAT LVS的常见名词解释 CIP<-->VIP--DIP<-->RIP Direct Routing: ...