netty]--最通用TCP黏包解决方案
netty]--最通用TCP黏包解决方案:LengthFieldBasedFrameDecoder和LengthFieldPrepender
前面已经说过:
TCP以流的方式进行数据传输,上层应用协议为了对消息进行区分,往往采用如下4种方式。
(1)消息长度固定:累计读取到固定长度为LENGTH之后就认为读取到了一个完整的消息。然后将计数器复位,重新开始读下一个数据报文。(2)回车换行符作为消息结束符:在文本协议中应用比较广泛。
(3)将特殊的分隔符作为消息的结束标志,回车换行符就是一种特殊的结束分隔符。
(4)通过在消息头中定义长度字段来标示消息的总长度。
netty中针对这四种场景均有对应的解码器作为解决方案,比如:
(1)通过FixedLengthFrameDecoder 定长解码器来解决定长消息的黏包问题;
(2)通过LineBasedFrameDecoder和StringDecoder来解决以回车换行符作为消息结束符的TCP黏包的问题;
(3)通过DelimiterBasedFrameDecoder 特殊分隔符解码器来解决以特殊符号作为消息结束符的TCP黏包问题;
(4)最后一种,也是本文的重点,通过LengthFieldBasedFrameDecoder 自定义长度解码器解决TCP黏包问题。
大多数的协议在协议头中都会携带长度字段,用于标识消息体或则整包消息的长度。LengthFieldBasedFrameDecoder通过指定长度来标识整包消息,这样就可以自动的处理黏包和半包消息,只要传入正确的参数,就可以轻松解决“读半包”的问题。
1. LengthFieldBasedFrameDecoder功能说明
下面我们通过实例来看如何通过配置不同的参数组合来实现不同的半包读取策略。
(1)场景一:消息的第一个字段是长度字段,后面是消息体,消息头中只包含一个长度字段,消息结构定义如下:
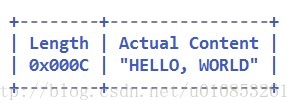
在解码前字节缓冲区占了14个字节,其中前两个字节是标识长度的字节,后面12个字节是消息体。
使用的组合参数如下:
1) lengthFieldOffset = 0;//长度字段的偏差
2) lengthFieldLength = 2;//长度字段占的字节数
3) lengthAdjustment = 0;//添加到长度字段的补偿值
4) initialBytesToStrip = 0。//从解码帧中第一次去除的字节数
解码后的字节缓冲区的内容是:
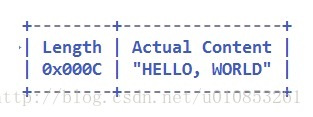
解码后还是14个字节。
(2)场景二:通过ByteBuf.readableBytes()方法我们可以获取当前消息的长度,所以解码后的字节缓冲区可以不携带长度字段,由于长度字段在起始位置并且长度为2,所以将initialBytesToStrip设置为2。参数组合修改为:
1) lengthFieldOffset = 0;
2) lengthFieldLength = 2;
3) lengthAdjustment = 0;
4) initialBytesToStrip = 2。
这时候解码后字节缓冲区的数据就是:
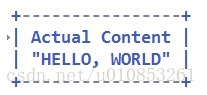
很明显跳过了长度字段后的字节缓冲区就只有12个字节了。
解码后的字节缓冲区丢弃了长度字段,仅仅包含消息体,对于大多数的协议,解码之后消息长度没有用处,因此可以丢弃。
(3)场景三:在大多数的应用场景中,长度字段仅用来标识消息体的长度,这类协议通常由消息长度字段+消息体组成,如上图所示的几个例子。但是,对于某些协议,长度字段还包含了消息头的长度。在这种应用场景中,往往需要使用lengthAdjustment进行修正。由于整个消息(包含消息头)的长度往往大于消息体的长度,所以,lengthAdjustment为负数。下图展示了通过指定lengthAdjustment字段来包含消息头的长度:
1) lengthFieldOffset = 0;
2) lengthFieldLength = 2;
3) lengthAdjustment = -2;
4) initialBytesToStrip = 0。
解码之前的码流: 
包含字段长度的码流:
解码只有的码流是:
(4)场景四:但是由于协议的种类繁多,并不是所有的协议都将长度字段放在消息头的首位,当标识消息长度的字段位于消息头的中间或者尾部时,需要使用lengthFieldOffset字段进行标识,下面的参数组合给出了如何解决消息长度字段不在首位的问题:
1) lengthFieldOffset = 2;
2) lengthFieldLength = 3;
3) lengthAdjustment = 0;
4) initialBytesToStrip = 0。
其中lengthFieldOffset表示长度字段在消息头中偏移的字节数,lengthFieldLength 表示长度字段自身的长度,解码效果如下:
解码之前:

解码之后:
由于消息头1的长度为2,所以长度字段的偏移量为2;消息长度字段Length为3,所以lengthFieldLength值为3。由于长度字段仅仅标识消息体的长度,所以lengthAdjustment和initialBytesToStrip都为0。
(5)场景五:最后一种场景是长度字段夹在两个消息头之间或者长度字段位于消息头的中间,前后都有其它消息头字段,在这种场景下如果想忽略长度字段以及其前面的其它消息头字段,则可以通过initialBytesToStrip参数来跳过要忽略的字节长度,它的组合配置示意如下:
1) lengthFieldOffset = 1;
2) lengthFieldLength = 2;
3) lengthAdjustment = 1;
4) initialBytesToStrip = 3。
解码之前16字节:

解码之后13字节:

由于HDR1的长度为1,所以长度字段的偏移量lengthFieldOffset为1;长度字段为2个字节,所以lengthFieldLength为2。由于长度字段是消息体的长度,解码后如果携带消息头中的字段,则需要使用lengthAdjustment进行调整,此处它的值为1,代表的是HDR2的长度,最后由于解码后的缓冲区要忽略长度字段和HDR1部分,所以lengthAdjustment为3。解码后的结果为13个字节,HDR1和Length字段被忽略。
事实上,通过4个参数的不同组合,可以达到不同的解码效果,用户在使用过程中可以根据业务的实际情况进行灵活调整。
粘包问题的解决策略
由于底层的TCP无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重组的,这个问题只能通过上层的应用协议栈设计来解决。业界的主流协议的解决方案,可以归纳如下:
1. 消息定长,报文大小固定长度,例如每个报文的长度固定为200字节,如果不够空位补空格;
2. 包尾添加特殊分隔符,例如每条报文结束都添加回车换行符(例如FTP协议)或者指定特殊字符作为报文分隔符,接收方通过特殊分隔符切分报文区分;
3. 将消息分为消息头和消息体,消息头中包含表示信息的总长度(或者消息体长度)的字段;
4. 更复杂的自定义应用层协议。
Netty提供了多个解码器,可以进行分包的操作,分别是:
* LineBasedFrameDecoder
* DelimiterBasedFrameDecoder(添加特殊分隔符报文来分包)
* FixedLengthFrameDecoder(使用定长的报文来分包)
* LengthFieldBasedFrameDecoder
LineBasedFrameDecoder解码器
LineBasedFrameDecoder是回车换行解码器,如果用户发送的消息以回车换行符作为消息结束的标识,则可以直接使用Netty的LineBasedFrameDecoder对消息进行解码,只需要在初始化Netty服务端或者客户端时将LineBasedFrameDecoder正确的添加到ChannelPipeline中即可,不需要自己重新实现一套换行解码器。
netty]--最通用TCP黏包解决方案的更多相关文章
- Linux tcp黏包解决方案
tcpip协议使用"流式"(套接字)进行数据的传输,就是说它保证数据的可达以及数据抵达的顺序,但并不保证数据是否在你接收的时候就到达,特别是为了提高效率,充分利用带宽,底层会使用缓 ...
- day 28 黏包及黏包解决方案
1.缓冲区 每个socket被创建以后,都会分配两个缓冲区,输入缓冲区和输出缓冲区,默认大小都是8k,可以通过getsocket()获取,暂时存放传输数据,防止程序在发送的时候卡阻,提高代码运行效率. ...
- Python网络编程基础 ❷ 基于upd的socket服务 TCP黏包现象
TCP的长连接 基于upd的socket服务 TCP黏包现象
- python 缓冲区 subprocess 黏包 黏包解决方案
一.缓冲区 二.两种黏包现象 两种黏包现象: 1 连续的小包可能会被优化算法给组合到一起进行发送 黏包现象1客户端 import socket BUFSIZE = 1024 ip_prort = (' ...
- socketserver tcp黏包
socket (套接字) tcp(黏包现象原因) 传输中由于内核区缓冲机制(等待时间,文件大小),会在 发送端 缓冲区合并连续send的数据,也会出现在 接收端 缓冲区合并recv的数据给指定port ...
- python tcp黏包和struct模块解决方法,大文件传输方法及MD5校验
一.TCP协议 粘包现象 和解决方案 黏包现象让我们基于tcp先制作一个远程执行命令的程序(命令ls -l ; lllllll ; pwd)执行远程命令的模块 需要用到模块subprocess sub ...
- tcp黏包
转载https://www.cnblogs.com/wade-luffy/p/6165671.html 无论是服务端还是客户端,当我们读取或者发送消息的时候,都需要考虑TCP底层的粘包/拆包机制. 回 ...
- python之黏包和黏包解决方案
黏包现象主要发生在TCP连接, 基于TCP的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看来,根本不知道该文件的字节流从何处开始,在何处结束. 两种黏包现象: 1 ...
- 【转】Netty之解决TCP粘包拆包(自定义协议)
1.什么是粘包/拆包 一般所谓的TCP粘包是在一次接收数据不能完全地体现一个完整的消息数据.TCP通讯为何存在粘包呢?主要原因是TCP是以流的方式来处理数据,再加上网络上MTU的往往小于在应用处理的消 ...
随机推荐
- 力扣(LeetCode)292. Nim游戏 巴什博奕
你和你的朋友,两个人一起玩 Nim游戏:桌子上有一堆石头,每次你们轮流拿掉 1 - 3 块石头. 拿掉最后一块石头的人就是获胜者.你作为先手. 你们是聪明人,每一步都是最优解. 编写一个函数,来判断你 ...
- 学习笔记15—Python 存储集
1. save using pickle with open('F:/BrainAging/result/ordered_data_final_just_TD_leaveOne.pickle ...
- Linux 中 MySQL常用命令
一. 数据库登录mysql -uroot -p二..退出数据库quit 和 exit或ctrl + d三.数据库操作1. 查看所有数据库 show databases;2. 查看当前使用的数据库sel ...
- Python Appium 开启Android测试之路
1.获取 Android app的Activity 打开终端cmd,先cd进入到刚才下载的“新浪.apk”目录下,然后使用aapt dump badging xxx.apk命令获取包内信息.注意,启动 ...
- 子序列的按位或 Bitwise ORs of Subarrays
2018-09-23 19:05:20 问题描述: 问题求解: 显然的是暴力的遍历所有的区间是不可取的,因为这样的时间复杂度为n^2级别的,对于规模在50000左右的输入会TLE. 然而,最后的解答也 ...
- using 自动释放资源示例
我们在使用SqlConnection的时候可以加入using,那么在using语句结束后就会自动关闭连接.那么这种情况是怎么是实现的呢?我们能够自己写一个类似于SqlConnection的类来让usi ...
- ubuntu 14.04 使用 xfce4 的时候,会有图标问题
有些程序的图标丢失了,结果十分影响整体用户体验. 解决方法: sudo apt-get install gnome-icon-theme-full tango-icon-theme 然后重新进入就行了 ...
- mysql连接池的使用工具类代码示例
mysql连接池代码工具示例(scala): import java.sql.{Connection,PreparedStatement,ResultSet} import org.apache.co ...
- Using the G711 standard
Using the G711 standard Marc Sweetgall, 28 Jul 2006 4.74 (27 votes) 1 2 ...
- LeetCode--409--最长回文串
问题描述: 给定一个包含大写字母和小写字母的字符串,找到通过这些字母构造成的最长的回文串. 在构造过程中,请注意区分大小写.比如 "Aa" 不能当做一个回文字符串. 注意: 假设字 ...