day_10 py
整理代码!!2018-7-24 20:53:49
直接复制了东西:
一些的demo 重点看蓝字部分! 就是一些简单的方法 基础的而已!
2018-4-22 15:50:26
继续py 还是py好玩感觉
字串符输出
'''
# name = 'xiaoming'
# position = '讲师'
# address = '北京市昌平区建材城西路金燕龙办公楼1层'
#
# print('--------------------------------------------------')
# print("姓名:%s" % name)
# print("职位:%s" % position)
# print("公司地址:%s" % address)
# print('--------------------------------------------------')
# 整合字符串方法
# print("姓名加职位%s"%(name+position))
'''
字符串的的输入
'''
# userName = input('请输入用户名:')
# print("用户名为:%s" % userName)
#
# password = input('请输入密码:')
# print("密码为:%s" % password)
'''
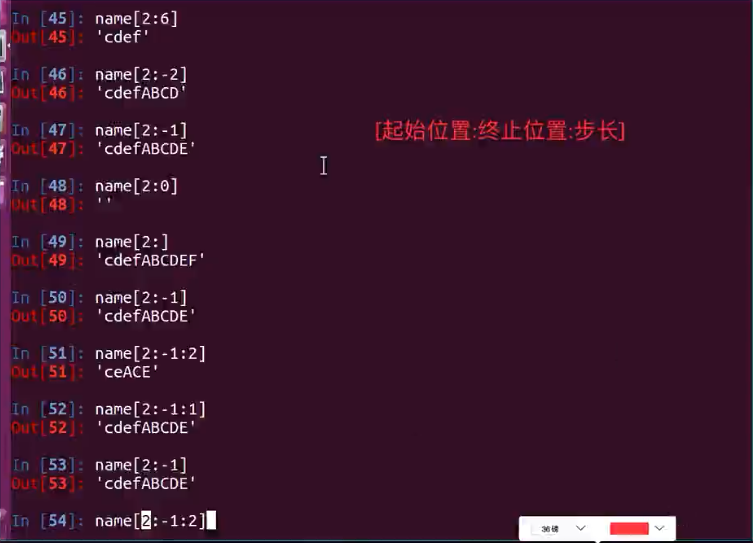
下标和切片 默认的步长是1
name[2:-1:1] 就去一个数
如果步长为-1 则反向(逆向取值)
逆序 倒叙
'''
# name = "abcdef"
# print(name[2])
# print(name[1]) # name = "abcdefABCDEF"
# print(name[2:-1])
# print(name[2:])
# print(name[2:-1:2])
# # 正方向取值 从左到右
# print(name[::1])
# # 反方向取值 从右到做
# print(name[::-1]) '''
常见字串符操作
'''
# mystr = 'hello world itcast and itcastcpp'
#
# # find mystr.find(str, start=0, end=len(mystr)) 如果没有则返回-1
# print(mystr.find("world"))
#
# # index mystr.index(str, start=0, end=len(mystr)) 和find()方法一样
# # 只不过如果str不在mystr会报一个异常
# print(mystr.index("world"))
#
# # count 返回 str在start和end之间 在 mystr里面出现的次数
# print(mystr.count("world"))
#
# # replace 把 mystr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
# # mystr.replace(str1, str2, mystr.count(str1))
# print(mystr.replace("itcast","xx",1))
#
# # 切割 split 以 str 为分隔符切片 mystr,如果 maxsplit有指定值,则仅分隔 maxsplit 个子字符串
# # mystr.split(str=" ", 2)
# print(mystr.split(" ")) '''
列表 添加新的元素
append()------->添加到末尾
insert()------->按照位置添加
a.extend(b)------->将b列表合并到a列表中 删除元素
pop()------------->删除最后一个
remove()---------->根据内容删除
del xxx[下标]------>根据下标来删除 修改
xxxx[下标] = new值 查询
in
not in
'''
# 列表中存放的数据是可以进行修改的,比如"增"、"删"、"改""
#
# <1>添加元素("增"append, extend, insert)
# append
#
# 通过append可以向列表添加元素
#
# demo:
#
# #定义变量A,默认有3个元素
# A = ['xiaoWang','xiaoZhang','xiaoHua']
#
# print("-----添加之前,列表A的数据-----")
# for tempName in A:
# print(tempName)
#
# #提示、并添加元素
# temp = input('请输入要添加的学生姓名:')
# A.append(temp)
#
# print("-----添加之后,列表A的数据-----")
# for tempName in A:
# print(tempName)
# 结果:
#
# 结果
#
# extend
#
# 通过extend可以将另一个集合中的元素逐一添加到列表中
#
# >>> a = [1, 2]
# >>> b = [3, 4]
# >>> a.append(b)
# >>> a
# [1, 2, [3, 4]]
# >>> a.extend(b)
# >>> a
# [1, 2, [3, 4], 3, 4]
# insert
#
# insert(index, object) 在指定位置index前插入元素object
#
# >>> a = [0, 1, 2]
# >>> a.insert(1, 3)
# >>> a
# [0, 3, 1, 2]
# <2>修改元素("改")
# 修改元素的时候,要通过下标来确定要修改的是哪个元素,然后才能进行修改
#
# demo:
#
# #定义变量A,默认有3个元素
# A = ['xiaoWang','xiaoZhang','xiaoHua']
#
# print("-----修改之前,列表A的数据-----")
# for tempName in A:
# print(tempName)
#
# #修改元素
# A[1] = 'xiaoLu'
#
# print("-----修改之后,列表A的数据-----")
# for tempName in A:
# print(tempName)
# 结果:
#
# -----修改之前,列表A的数据-----
# xiaoWang
# xiaoZhang
# xiaoHua
# -----修改之后,列表A的数据-----
# xiaoWang
# xiaoLu
# xiaoHua
# <3>查找元素("查"in, not in, index, count)
# 所谓的查找,就是看看指定的元素是否存在
#
# in, not in
#
# python中查找的常用方法为:
#
# in(存在),如果存在那么结果为true,否则为false
# not in(不存在),如果不存在那么结果为true,否则false
# demo
#
# #待查找的列表
# nameList = ['xiaoWang','xiaoZhang','xiaoHua']
#
# #获取用户要查找的名字
# findName = input('请输入要查找的姓名:')
#
# #查找是否存在
# if findName in nameList:
# print('在字典中找到了相同的名字')
# else:
# print('没有找到')
# 结果1:(找到)
#
# 结果
#
# 结果2:(没有找到)
#
# 结果
#
# 说明:
#
# in的方法只要会用了,那么not in也是同样的用法,只不过not in判断的是不存在
#
# index, count
#
# index和count与字符串中的用法相同
#
# >>> a = ['a', 'b', 'c', 'a', 'b']
# >>> a.index('a', 1, 3) # 注意是左闭右开区间
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# ValueError: 'a' is not in list
# >>> a.index('a', 1, 4)
# 3
# >>> a.count('b')
# 2
# >>> a.count('d')
# 0
# <4>删除元素("删"del, pop, remove)
# 类比现实生活中,如果某位同学调班了,那么就应该把这个条走后的学生的姓名删除掉;在开发中经常会用到删除这种功能。
#
# 列表元素的常用删除方法有:
#
# del:根据下标进行删除
# pop:删除最后一个元素
# remove:根据元素的值进行删除
# demo:(del)
#
# movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
#
# print('------删除之前------')
# for tempName in movieName:
# print(tempName)
#
# del movieName[2]
#
# print('------删除之后------')
# for tempName in movieName:
# print(tempName)
# 结果:
#
# ------删除之前------
# 加勒比海盗
# 骇客帝国
# 第一滴血
# 指环王
# 霍比特人
# 速度与激情
# ------删除之后------
# 加勒比海盗
# 骇客帝国
# 指环王
# 霍比特人
# 速度与激情
# demo:(pop)
#
# movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
#
# print('------删除之前------')
# for tempName in movieName:
# print(tempName)
#
# movieName.pop()
#
# print('------删除之后------')
# for tempName in movieName:
# print(tempName)
# 结果:
#
# ------删除之前------
# 加勒比海盗
# 骇客帝国
# 第一滴血
# 指环王
# 霍比特人
# 速度与激情
# ------删除之后------
# 加勒比海盗
# 骇客帝国
# 第一滴血
# 指环王
# 霍比特人
# demo:(remove)
#
# movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
#
# print('------删除之前------')
# for tempName in movieName:
# print(tempName)
#
# movieName.remove('指环王')
#
# print('------删除之后------')
# for tempName in movieName:
# print(tempName)
# 结果:
#
# ------删除之前------
# 加勒比海盗
# 骇客帝国
# 第一滴血
# 指环王
# 霍比特人
# 速度与激情
# ------删除之后------
# 加勒比海盗
# 骇客帝国
# 第一滴血
# 霍比特人
# 速度与激情
# <5>排序(sort, reverse)
# sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。
#
# reverse方法是将list逆置。
#
# >>> a = [1, 4, 2, 3]
# >>> a
# [1, 4, 2, 3]
# >>> a.reverse()
# >>> a
# [3, 2, 4, 1]
# >>> a.sort()
# >>> a
# [1, 2, 3, 4]
# >>> a.sort(reverse=True)
# >>> a
# [4, 3, 2, 1]
1.切片与步长
day_10 py的更多相关文章
- day_10 py 字典
#!/usr/bin/env/python#-*-coding:utf-8-*-'''字典: (就是增加个索引名字,然后归类了一下) infor = {键:值,键:值} 列表存储相同的信息随着列表里面 ...
- python调用py中rar的路径问题。
1.python调用py,在py中的os.getcwd()获取的不是py的路径,可以通过os.path.split(os.path.realpath(__file__))[0]来获取py的路径. 2. ...
- Python导入其他文件中的.py文件 即模块
import sys sys.path.append("路径") import .py文件
- import renumber.py in pymol
cp renumber.py /usr/local/lib/python2.7/dist-packages/pymol import renumber or run /path/to/renumber ...
- python gettitle.py
#!/usr/bin/env python # coding=utf-8 import threading import requests import Queue import sys import ...
- 解决 odoo.py: error: option --addons-path: The addons-path 'local-addons/' does not seem to a be a valid Addons Directory!
情况说明 odoo源文件路径-/odoo-dev/odoo/: 我的模块插件路径 ~/odoo-dev/local-addons/my-module 在my-module中创建了__init__.py ...
- caffe机器学习自带图片分类器classify.py实现输出预测结果的概率及caffe的web_demo例子运行实例
caffe机器学习环境搭建及python接口编译参见我的上一篇博客:机器学习caffe环境搭建--redhat7.1和caffe的python接口编译 1.运行caffe图片分类器python接口 还 ...
- 【转】Windows下使用libsvm中的grid.py和easy.py进行参数调优
libsvm中有进行参数调优的工具grid.py和easy.py可以使用,这些工具可以帮助我们选择更好的参数,减少自己参数选优带来的烦扰. 所需工具:libsvm.gnuplot 本机环境:Windo ...
- MySqlNDB使用自带的ndb_setup.py安装集群
在用Mysql做集群时,使用Mysql的NDB版本更易于集群的扩展,稳定和数据的实时性. 我们可以使用Mysql自带的工具进行集群安装与管理:ndb_setup.py.位于Mysql的安装目录bin下 ...
随机推荐
- python实战--csdn博客专栏下载器
打算利用业余时间好好研究Python的web框架--web.py,深入剖析其实现原理,体会web.py精巧之美.但在研究源码的基础上至少得会用web.py.思前想后,没有好的Idea,于是打算开发一个 ...
- phpstorm10使用服务激活
现在官网已经更新到WebStorm 11.PhpStorm 10,找到一个很便捷的方法,不需要注册码了.安装完成,打开软件看到输入注册码界面的时候,切换到第二个选项,输入:http://idea.la ...
- zeromq学习笔记2——简单的客户端和服务端测试程序
1.前言 zeromq提供了guide,http://zguide.zeromq.org/,可以帮助新手快速上手,提供了C\C++\PHP等多种语言. 2.测试程序 使用zeromq给的hwserve ...
- 坚果云无法同步SVN文件夹
把svn的库放在云盘上,同步到本地,以前在金山快盘.360网盘都用得好好的,换坚果云后,想着肯定没问题,结果发现,不行! 新机子上的版本库可以建起来,但检出时报错: Could not open th ...
- springMVC返回json数据时date类型数据被转成long类型
在项目的过程中肯定会遇到ajax请求,但是再用的过程中会发现,在数据库中好好的时间类型数据:2017-05-04 17:52:24 在转json的时候,得到的就不是时间格式了 而是145245121这 ...
- [JS]两个常用的取随机整数的函数
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/ ...
- 《Unix&Linux大学教程》学习笔记七:进程与作业控制
1:进程:一个内存中的程序+程序所需数据+管理程序的各种状态信息. 2:进程由内核进行管理,内核使用调度器,给予进程一个时间片来运行,然后切换到下一个进程. 3:进程分叉 fork :创建一个子进程 ...
- 【tp5】ThinkCMF5框架,配置使其支持不同终端PC/WAP/Wechat能加载不同配置和视图
1.版本 5.0.18 2.在data/conf/ 新增config.php文件,内容如下: <?php //ThinkCMF5区别不同客户端加载不同配置文件和模块.视图 $default_mo ...
- 20151028整理罗列某种开发所包括对技术(技术栈),“较为全面”地表述各种技术大系的图表:系统开发技术栈图、Web前端技术栈图、数据库技术栈图、.NET技术栈图
———————————— 我的软件开发生涯 (10年开发经验总结和爆栈人生) 爆栈人生 现在流行说全栈.每种开发都有其相关的技术.您是否觉得难以罗列某种开发所包括对技术(技术栈)呢? 您是否想过: ...
- Socket网络编程--网络爬虫(4)
上一小节我们已经实现了获取博客园最近博客的200页里面的用户名,并保存在一个map中.一开始是想通过这个用户名然后构造一个博客地址.然后在这个地址中查找心得用户名,但是后来发现这个的效率不是很高,虽然 ...