访问WEB-INF目录中的JSP文件
本文主要记录一些关于Flink与storm,spark的区别, 优势, 劣势, 以及为什么这么多公司都转向Flink.
What Is Flink
一个通俗易懂的概念: Apache Flink 是近年来越来越流行的一款开源大数据计算引擎,它同时支持了批处理和流处理.
这是对Flink最简单的认识, 也最容易引起疑惑, 它和storm和spark的区别在哪里? storm是基于流计算的, 但是也可以模拟批处理, spark streaming也可以进行微批处理, 虽说在性能延迟上处于亚秒级别, 但也不足以说明Flink崛起如此迅速(毕竟从spark迁移到Flink是要成本的).
最显而易见的原因
网上最热的两个原因:
- Flink灵活的窗口
- Exactly once语义保证
这两个原因可以大大的解放程序员, 加快编程效率, 把本来需要程序员花大力气手动完成的工作交给框架, 下面简单介绍一下这两个特征.
1.什么是 Window
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
窗口可以是时间驱动的(Time Window, 例如: 每30秒钟), 也可以是数据驱动的(Count Window, 例如: 每一百个元素). 一种经典的窗口分类可以分成: 翻滚窗口(Tumbling Window, 无重叠), 滚动窗口(Sliding Window, 有重叠), 和会话窗口(Session Window,活动间隙).
我们举个具体的场景来形象地理解不同窗口的概念. 假设, 淘宝网会记录每个用户每次购买的商品个数, 我们要做的是统计不同窗口中用户购买商品的总数. 下图给出了几种经典的窗口切分概述图:
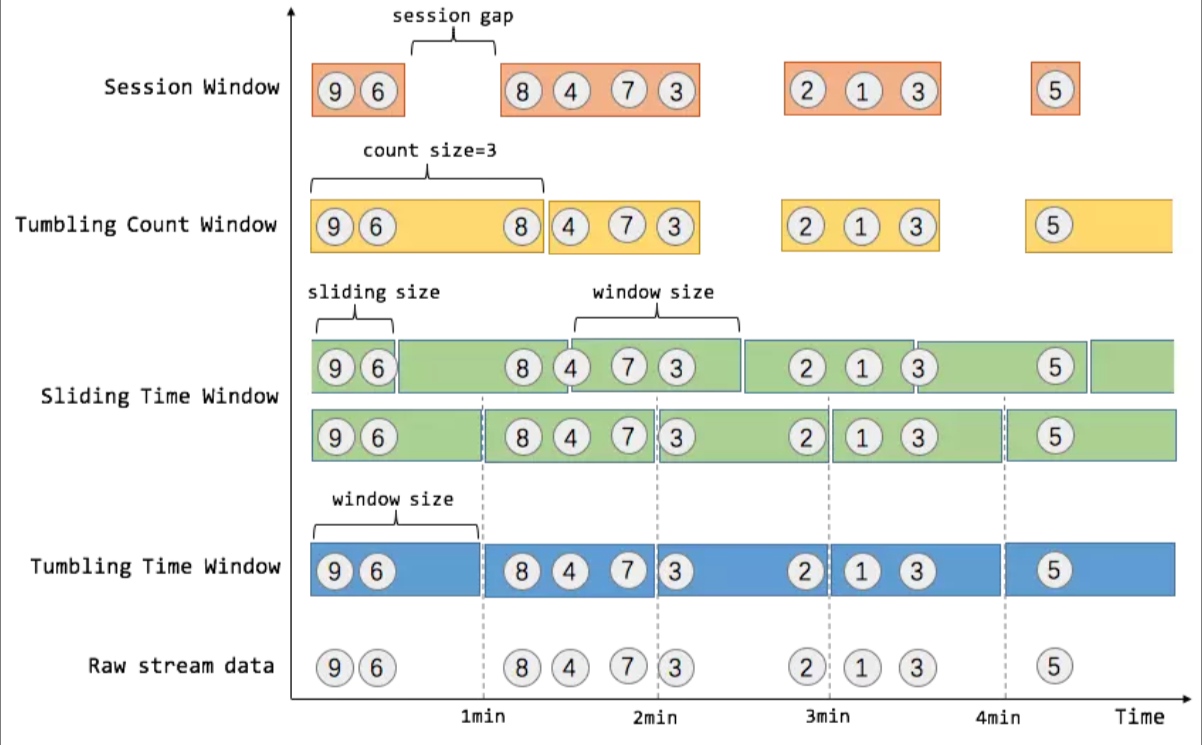
上图中, raw data stream 代表用户的购买行为流, 圈中的数字代表该用户本次购买的商品个数, 事件是按时间分布的, 所以可以看出事件之间是有time gap的. Flink 提供了上图中所有的窗口类型. 关于Flink窗口的更多细节可以参考Flink 原理与实现:Window 机制.
Exactly-once语义保证
Exactly-once语义是Flink的特性之一, 这到底是什么意思呢? 是否以为这每一份到达Flink的数据, 只会被处理一次?
官网的表述, 引用日期: 2019-01-31:

Exactly-once state consistency: Flink’s checkpointing and recovery algorithms guarantee the consistency of application state in case of a failure. Hence, failures are transparently handled and do not affect the correctness of an application.
可以看出, Exactly-once 是为有状态的计算准备的!!!
换句话说, 没有状态的算子操作(operator), Flink无法也无需保证其只被处理Exactly-once! 为什么呢? 因为即使失败的情况下, 无状态的operator(map, filter等)只需要数据重新计算一遍即可. 例如:
dataStream.filter(_.isInNYC)
当机器(节点)等失败时, 只需从最近的一份快照开始, 利用可重发的数据源重发一次数据即可, 当数据经过filter算子时, 全部重新算一次即可,根本不需要区分哪个数据被计算过,哪个数据没有被计算过,因为没有状态的算子只有输入和输出,没有状态可以保存.
此外, Flink的Exactly-once需要从最近的一份快照开始重放数据, 因此这也和数据源的能力有关, 不是所有的数据源都可以提供Exactly-once语义的. 以下是apache官网列出的数据源和Exactly-once语义保障能力列表.
| Source | Guarantees | Notes |
|---|---|---|
| Apache Kafka | exactly once | Use the appropriate Kafka connector for your version |
| AWS Kinesis Streams | exactly once | |
| RabbitMQ | at most once (v 0.10) / exactly once (v 1.0) | |
| Twitter Streaming API | at most once | |
| Collections | exactly once | |
| Files | exactly once | |
| Sockets | at most once |
有没有更深入的原因
api只是表层,有没有更深入的原因呢?例如, 基于窗口的统计, 统计最近5分钟内用户点击过的商品种类, spark streaming(或storm trident)这样的mini-batch模式也可以实现, 并且它们也提供了Exactly-once语义, 那Flink与这二者相比有什么区别呢, 又或者说有什么优势呢? 找到了两个方面的原因:
- 流处理与mini-batch的区别
- Exactly-once语义实现原理
1.流处理与mini-batch的区别
mini-batch模式的处理过程:
1.在数据流中收集记录,
2.收集若干记录后, 调度一个批处理作业进行数据处理,
3.在批处理运行的同时, 收集下一批次的记录.
也就是说spark为了处理一个mini-batch, 需要调度一个批处理作业, 相比于flink延迟较大, spark的处理延迟在秒级.
而flink只需启动一个流计算拓扑, 处理持续不断的数据, Flink的处理延迟在毫秒级别. 如果计算中涉及到多个网络shuffle, spark streaming和Flink之间的延迟差距会进一步拉大.
2.Exactly-once语义实现原理
Flink实现Exactly-once语义的原理与spark streaming是不一样的, 下文简要介绍一下流式架构的演变来了解这种区别.
流式架构的演变
在实践中, 流处理时既要保证高性能同时又要保证容错是非常困难的. 在批处理中, 当作业失败时, 可以容易地重新运行作业的失败部分来重新计算丢失的结果. 这在批处理中是可行的, 因为文件可以从头到尾重放. 但是在流处理中却不能这样处理. 数据流是无穷无尽的, 没有开始点和结束点. 带有缓冲的数据流可以进行重放一小段数据, 但从最开始重放数据流是不切实际的(流处理作业可能已经运行了数月). 此外, 如果当前的流计算是有状态的, 那就意味着除了输出之外, 系统还需要备份和恢复中间算子状态. 由于这个问题比较复杂, 因此在开源生态系统中有许多方案尝试去解决容错与性能兼容的问题.
下面介绍一些流处理架构的几种容错方法, 从记录确认到微批处理, 事务更新和分布式快照. 从以下几个维度讨论不同方法的优缺点:
- Exactly-once语义保证: 这个上文已经介绍
- 低延迟: 延迟越低越好, 许多应用程序需要亚秒级延迟(例如欺诈拦截这样的需求)
- 高吞吐量: 随着数据速率的增长, 通过管道推送大量数据至关重要.
- 强大的计算模型: 框架应该提供一种编程模型, 该模型不会对用户进行限制并保证应用程序在没有故障的情况下容错机制的低开销.
- 流量控制: 处理速度慢的算子产生的背压应该由系统和数据源自然吸收, 以避免因消费缓慢而导致崩溃或性能降低.
- 失败后的快速恢复: 这一点主流的大数据框架基本都能做到.
1.记录确认机制(Apache Storm)
开源中第一个广泛使用的大规模流处理框架可能是Apache Storm. Storm使用上游备份和记录确认机制来保证在失败后重新处理消息. Storm本身不保证状态一致性, 任何可变状态的处理都需要委托给用户处理(Storm的Trident API可以确保状态一致性, 但更加类似于spark streaming的mini-batch方式).
storm的无状态模块设计和纯记录确认体系结构, 不适合进行有状态的流计算, 也无法提供Exactly-once语义保证.
2.微批处理(Apache Storm Trident, Apache Spark Streaming)
容错流式架构的下一个发展阶段是微批处理或离散化流. 这个想法非常简单:为了解决连续计算模型(处理和缓冲记录)所带来的记录级别同步的复杂性和开销, 连续计算分解为一系列小的原子性的批处理作业(称为微批次). 每个微批次可能会成功或失败, 如果发生故障, 重新计算最近的微批次即可.
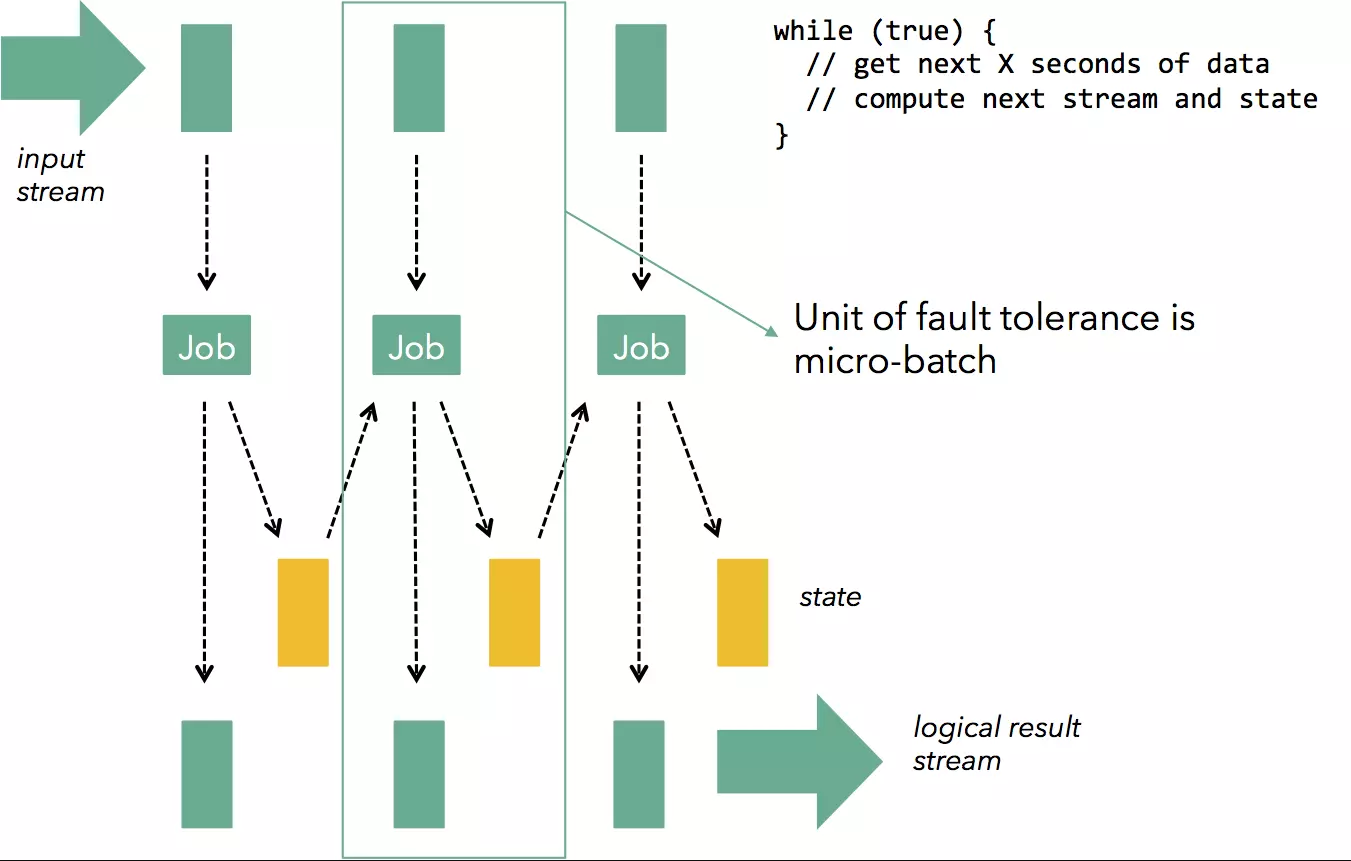
微批处理可以应用到现有引擎(有能力进行数据流计算)之上. 例如, 可以在批处理引擎Spark之上应用微批处理以提供流功能(这是Spark Streaming背后的基本机制), 也可以应用于流引擎Storm之上提供 Exactly-once 语义保证和状态恢复(这是Storm Trident背后的基本机制). 在 Spark Streaming 中, 每个微批次计算都是一个 Spark 作业, 而在Storm Trident 中, 每个微批次中的所有记录都会被合并为一个大型记录.
基于微批处理的系统可以实现上面列出的多个的要求(Exactly-once语义保证, 高吞吐量), 但也有不足之处:
- 编程模型: 例如, Spark Streaming 为了实现上述目标将编程模型从流式更改为微批处理. 这意味着用户不能再以任意时间而只能在检查点间隔的倍数上窗口化数据, 并且模型不支持许多应用程序所需的基于计数或会话的窗口. 这些都是应用程序开发人员关注的问题. 具有可以改变状态的持续计算的纯流模型为用户提供了更大的灵活性.
- 流量控制: 使用基于时间划分批次的微批次架构仍然具有背压的问题. 如果微批处理在下游操作中(例如, 由于计算密集型算子处理不过来或向外部存储数据比较缓慢)比在划分批次的算子(通常是源)中花费更长时间, 则微批次将花费比配置更长的时间. 这导致越来越多的批次排队, 或者导致微批量增加.
- 延迟: 微批处理显然将作业的延迟限制为微批处理的延迟. 虽然亚秒级的批处理延迟对于简单应用程序是可以接受的, 但是具有多个网络Shuffle的应用程序很容易将延迟时间延长到数秒.
为了说明上述问题, 假设一个程序(下面示例是Flink代码)每5秒聚合一次记录:
dataStream
.map(transformRecords)
.groupBy("sessionId")
.window(Time.of(5, TimeUnit.SECONDS))
.sum("price")
这些应用非常适合微批处理模型. 系统累积5秒的数据, 对它们求和, 并在流上进行一些转换后进行聚合计算. 下游应用程序可以直接消费上述5秒聚合后的结果, 例如在仪表板上显示. 但是, 现在假设背压开始起作用(transformRecords需要消耗超过5秒钟的时间), 开发人员决定将窗口间隔改为7秒, 增加吞吐量, 然后, 微批次大小变的不可控制. 这意味着下游应用程序(例如, 包含最近5秒统计的 Web 仪表板)读取的聚合结果是错误的, 下游应用程序需要自己处理此问题, 这显然是不合理的.
3.事务更新(Google Cloud Dataflow)
在保留连续算子模型(低延迟, 背压容错, 可变状态等)的优势的同时又保证Exactly-Once处理语义的一种强大而又优雅的方法是原子性地记录需要处理的数据并更新到状态中. 失败后, 可以从日志中重新恢复状态以及需要处理的记录.
在Google Cloud Dataflow中实现了此概念。系统将计算抽象为一次部署并长期运行的连续算子的DAG. 这为低延迟提供了一种自然的流量控制机制, 因为中间过程的缓冲可以缓解背压, 直到反压到数据源(基于Pull模式的数据源, 例如Kafka消费者可以处理这个问题). 该模型还提供了一个优雅的流编程模型, 可以提供更丰富的窗口而不是简单的基于时间的窗口以及可以更新到长期可变的状态中. 值得注意的是, 流编程模型包含微批处理模型.
例如, 下面Google Cloud Dataflow程序会创建一个会话窗口, 如果某个key的事件没有在10分钟内到达, 则会触发该会话窗口. 在10分钟后到达的数据将会启动一个新窗口.
PCollection<String> items = ...;
PCollection<String> session_windowed_items = items.apply(
Window.<String>into(Sessions.withGapDuration(Duration.standardMinutes(10))))
例如事件在7分钟的时候到达了, 就会触发一个窗口, 这在流处理模型中很容易实现, 但在微批处理模型中却很难实现, 因为窗口与微批量并不对应.
这种架构的容错工作原理如下: 通过算子的每个中间记录与更新的状态以及后续产生的记录一起创建一个提交记录, 该记录以原子性的方式追加到事务日志或插入到数据库中. 在失败的情况下, 重放部分数据库日志来恢复计算状态, 以及重放丢失的记录.
事务更新体系结构具有许多优点. 事实上, 它实现了我们在本文开头提出的所有需求. 该体系结构的基础是能够频繁地写入具有高吞吐量的分布式容错存储系统中.
4.分布式快照(Apache Flink)
分布式快照与事务更新相比, 是将拓扑的状态作为一个整体进行快照,从而减少了对分布式存储的写入量和频率. 提供 Exactly-Once 语义保证的问题实际上可以归结为确定当前流式计算所处的状态(包括正在处理中记录以及算子状态), 然后生成该状态的一致性快照, 并将快照存储在持久存储中. 如果可以经常执行上述操作, 那么从故障中恢复意味着仅从持久存储中恢复最新快照, 并将流数据源(例如, Apache Kafka)回退到生成快照的时间点再次'重放'. Flink的分布式快照算法可以参阅此处. 在下文中只做简单介绍.
Flink的分布式快照算法基于Chandy和Lamport在1985年设计的一种算法, 用于生成分布式系统当前状态的一致性快照(详细介绍请参阅此处), 不会丢失信息且不会记录重复项. Flink使用的是Chandy Lamport算法的一个变种, 定期生成正在运行的流拓扑的状态快照, 并将这些快照存储到持久存储中(例如, 存储到HDFS或内存中文件系统). 检查点的存储频率是可配置的.
这有点类似于微批处理方法, 两个检查点之间的所有计算都作为一个原子整体, 要么全部成功, 要么全部失败. 然而, 只有这一点的相似之处. Chandy Lamport算法的一个重要特点是我们不必在流处理中按下'暂停'按钮(等待检查点完成之后)来调度下一个微批次. 相反, 常规数据处理一直运行, 数据到达就会处理, 而检查点发生在后台.
因此, 这种架构融合了连续算子模型(低延迟, 流量控制和真正的流编程模型), 高吞吐量, Chandy-Lamport算法提供的Exactly-Once语义保证等优点. 除了备份有状态计算的状态(其他容错机制也需要这样做)之外, 这种容错机制几乎没有其他开销. 对于小状态(例如, 计数或其他统计), 备份开销通常可以忽略不计, 而对于大状态, 检查点间隔会在吞吐量和恢复时间之间进行权衡.
最重要的是, 该架构将应用程序开发与流量控制和吞吐量控制分开. 更改快照间隔对流作业的结果完全没有影响, 因此下游应用程序可以放心地依赖于接收到的正确结果. (不同于spark streaming, 应用程序统计的窗口与mini-batch
的大小紧紧绑定, 进而影响到性能与吞吐量).
Flink的检查点机制基于流经算子和渠道的'barrier'(认为是Chandy Lamport算法中的一种'标记')来实现.
'Barrier' 在 Source 节点中被注入到普通流数据中(例如, 如果使用Apache Kafka作为源, 'barrier'与偏移量对齐), 并且作为数据流的一部分与数据流一起流过DAG. 'barrier' 将记录分为两组: 当前快照的一部分('barrier' 表示检查点的开始), 以及属于下一个快照的那些组.
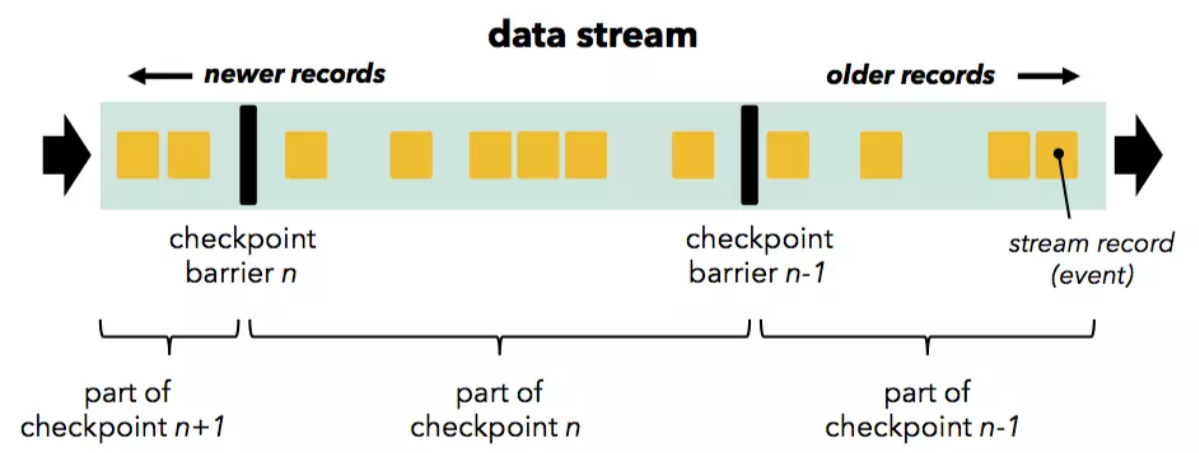
'Barrier' 流向下游并在通过算子时触发状态快照. 算子首先将所有流入的流分区的 'barrier' 对齐(如果算子具有多个输入), 并会缓存较快的分区数据(上游来源较快的流分区将被缓冲数据以等待来源较慢的流分区). 当算子从每个输入流中都收到 'barrier' 时, 会检查其状态(如果有)并写到持久存储中. 一旦完成状态写检查, 算子就将 'barrier' 向下游转发. 请注意, 在此机制中, 如果算子支持, 则状态写检查既可以是异步(在写入状态时继续处理), 也可以是增量(仅写入更改).
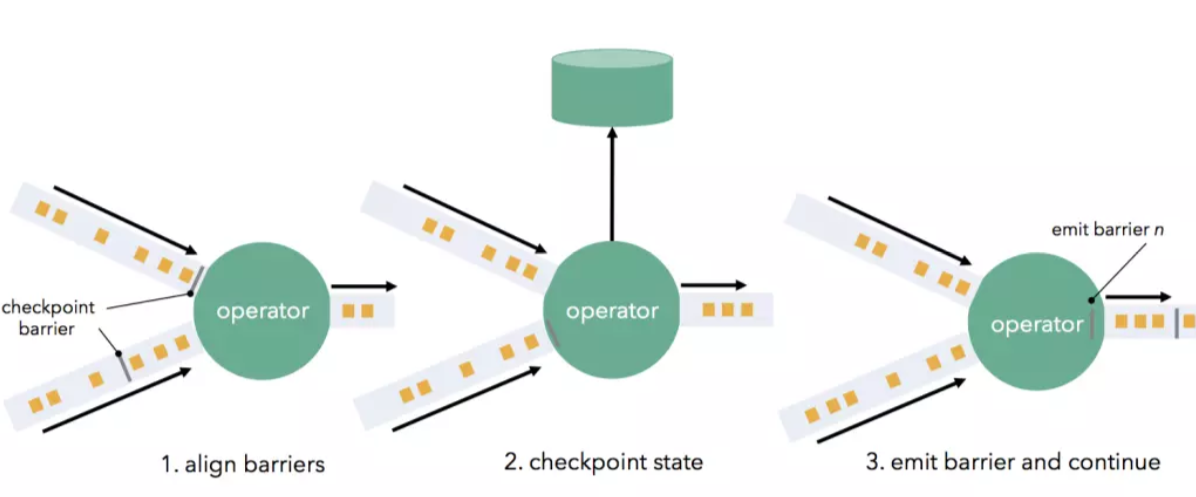
一旦所有数据接收器(Sink)都收到 'barrier', 当前检查点就完成了. 故障恢复意味着只需恢复最新的检查点状态, 并从最新记录的 'barrier' 对应的偏移量重放数据源. 分布式快照在我们在本文开头所要达到的所有需求中得分很高. 它们实现了高吞吐量的Exactly-Once语义保证, 同时还保留了连续算子模型以及低延迟和自然流量控制.
总结
了解流式架构的演变后, 再看 Flink, storm, spark三者的区别是什么, 有一句话概括的比较好:
Flink looks like a true successor to Storm like Spark succeeded hadoop in batch.
大数据起源自批处理, spark最初的定位就是改进hadoop, 更快速的进行批处理. storm擅长的则是进行无状态的流计算(在无状态的流计算领域, 它的延迟是最小的), 而Flink则是storm的下一代解决方案(当然Flink的设计之初并不是改进storm), 能够进行高吞吐,低延迟(毫秒级)的有状态流计算.下图是此处的一张storm和Flink的吞吐量和延迟对比图, 可以看到storm在延迟这一项上还是优于Flink的(当然只是参考, 具体情况还要具体分析).
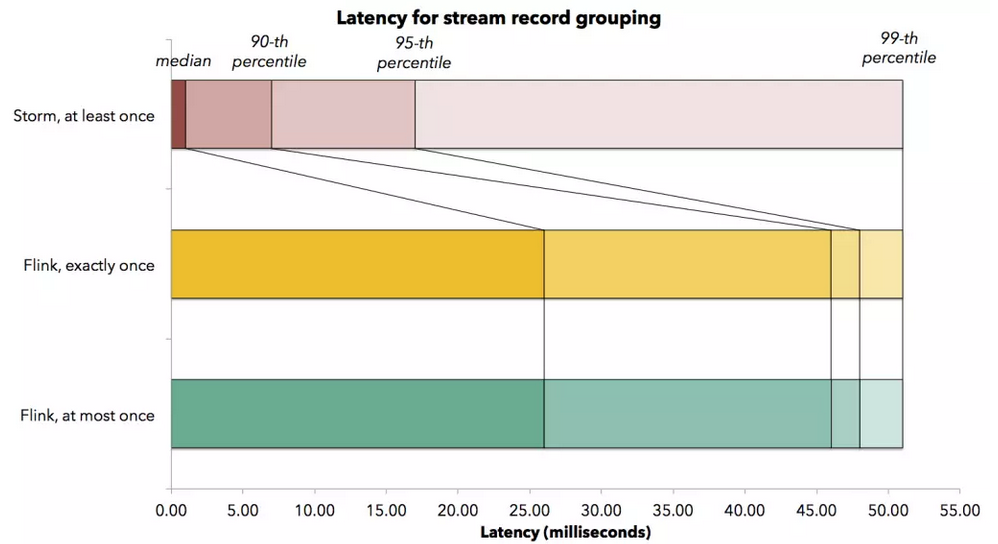
参考文档:
High-throughput, low-latency, and exactly-once stream processing with Apache Flink
Flink流计算编程--状态与检查点
Flink 原理与实现:Window 机制
转自:https://www.jianshu.com/p/442521ddc28f
访问WEB-INF目录中的JSP文件的更多相关文章
- 【转载】访问WEB-INF目录中的JSP文件
转自:http://blog.csdn.net/eidolon8/article/details/7050114 方法1:本来WEB-INF中的jsp就是无法通过地址栏访问的.所以安全.如果说你要访问 ...
- 如何访问WEB-INFO目录中的jsp文件
说明:应用服务器把WEB-INF指为禁访目录,即直接在浏览器里是不能访问的. 如何访问如下: 1.在项目的web.xml文件中去配置servlet <servlet> <servle ...
- Android开发---如何操作资源目录中的资源文件4 ---访问xml的配置资源文件的内容
Android开发---如何操作资源目录中的资源文件4 XML,位于res/xml/,这些静态的XML文件用于保存程序的数据和结构. XmlPullParser可以用于解释xml文件 效果图: 描述: ...
- 设置tomcat配置文件,在Myeclipse中修改jsp文件之后不用重启tomcat
在Myeclipse中创建的Web程序在修改类或者jsp页面后需要重动ttomcat的,要重新加载一次的,即重新启动tomcat一次.重启时比较慢,及浪费资源及时间, 设置tomcat配置文件,在My ...
- spring mvc: 可参数化的视图控制器(在配置中指定jsp文件)MultiActionController/SimpleUrlHandlerMapping/ParameterizableViewController
spring mvc: 可参数化的视图控制器(在配置中指定jsp文件)MultiActionController/SimpleUrlHandlerMapping/ParameterizableView ...
- 在/proc文件系统中增加一个目录hello,并在这个目录中增加一个文件world,文件的内容为hello world
一.题目 编写一个内核模块,在/proc文件系统中增加一个目录hello,并在这个目录中增加一个文件world,文件的内容为hello world.内核版本要求2.6.18 二.实验环境 物理主机:w ...
- 创建一个目录info,并在目录中创建一个文件test.txt,把该文件的信息读取出来,并显示出来
/*4.创建一个目录info,并在目录中创建一个文件test.txt,把该文件的信息读取出来,并显示出来*/ #import <Foundation/Foundation.h>#defin ...
- Android开发---如何操作资源目录中的资源文件3--圆角边框、背景颜色渐变效果、边框颜色
Android开发---如何操作资源目录中的资源文件3 效果图 1.圆角边框 2.背景颜色渐变效果 1.activity_main.xml 描述: 定义了一个shape资源管理按钮 <?xml ...
- Android开发 ---如何操作资源目录中的资源文件2
Android开发 ---如何操作资源目录中的资源文件2 一.颜色资源管理 效果图: 描述: 1.改变字体的背景颜色 2.改变字体颜色 3.改变按钮颜色 4.图像颜色切换 操作描述: 点击(1)中的颜 ...
随机推荐
- UUID为36位
package util; import java.util.UUID; public class UUIDUtil { public static UUID getId(){ return UUID ...
- MVC EF异常-“序列化类型为 XX 的对象时检测到循环引用”
原因:在EF实体中,两个互为主外键关系的实体类的导航属性相互引用. 解决方法一:删除一个不需要的类的导航属性 方法二:使用DTO模型 方法三:直接返回需要的属性(不能包括相互引用的属性)
- VC 最爱问的问题:你这个创业项目,如果腾讯跟进了,而且几乎是产品上完全复制,你会怎么办?
VC 最爱问的问题:你这个创业项目,如果腾讯跟进了,而且几乎是产品上完全复制,你会怎么办? http://www.zhihu.com/question/19607233 朱继玉,独立精神,自由思想. ...
- hdu 3032 Nim or not Nim? 博弈论
这题是Lasker’s Nim. Clearly the Sprague-Grundy function for the one-pile game satisfies g(0) = 0 and g( ...
- 5.查找最小的k个元素(数组)
题目: 输入n个整数,输出其中最小的k个,例如输入1,2,3,4,5,6,7,8这8个数,则最小的4个是1,2,3,4(输出不要求有序) 解: 利用快速排序的partition,算导上求第k大数的思想 ...
- AppStore 沙箱环境的测试流程
1:请确保你打得版本是 沙箱环境的版本 2:请确保的手机序列号已经加入沙箱环境3:请确保你的手机Apple ID 账户已经退出 ------ 如果这些都准备好了,再进行测试吧,不然一堆的未知问题等着你 ...
- CURL与PHP-CLI的应用【CLI篇】
CLI的普通应用 什么是PHP-CLI php-cli是php Command Line Interface的简称,即PHP命令行接口,在windows和linux下都是支持PHP-CLI模式的; 为 ...
- ANDROID_MARS学习笔记_S01_003layout初步
一.layout介绍 二.测试linear_layout1.activity_main.xml <?xml version="1.0" encoding="utf- ...
- Dreamweaver CS6破解教程[序列号+破解补丁]
Dreamweaver CS6破解教程[序列号+破解补丁] Adobe Dreamweaver CS6中文简体版下载地址:Dreamweaver CS6中文简体版下载[带破解] 破解之前的准备 1 ...
- ogg实现oracle到sql server 2005的同步
一.源端(oracle)配置1.创建同步测试表create table gg_user.t01(name varchar(20) primary key);create table gg_user.t ...