hadoop2.7【单节点】单机、伪分布、分布式安装指导
问题导读
1.从本文部署实际部署,总结本地模式、伪分布、分布式的区别是什么?
2.单机是否是伪分布?
3.本地模式是否可以运行mapreduce?

来源:about云
![]()
http://www.aboutyun.com/thread-12798-1-1.html
hadoop2.7发布,这一版不太适合用于生产环境,但是并不影响学习:由于hadoop安装方式有三种,并且三种安装方式都可以在前面的基础上继续配置,分别是:
- 本地模式
- 伪分布
- 分布式
###############################################
1.准备
安装jdk1.7参考
linux(ubuntu)安装Java jdk环境变量设置及小程序测试
测试:
Java -version
安装ssh
sudo apt-get install ssh
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ export HADOOP\_PREFIX=/usr/local/hadoop
最后达到无密码登录
ssh localhost
安装rsync
sudo apt-get install rsync
修改网卡:
注释掉127.0.1.1 ubuntu
添加新的映射
10.0.0.81 ubuntu
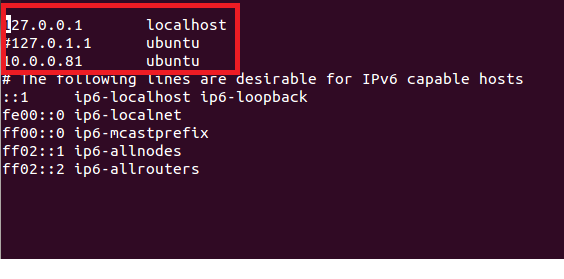
这里必须修改,否则后面会遇到连接拒绝等问题
2.安装
进入配置文件目录
我这里是
~/hadoop-2.7.0/etc/hadoop
修改配置文件:
etc/hadoop/hadoop-env.sh
添加JAVA_HOME、HADOOP_COMMON_HOME
export JAVA_HOME=/usr/jdk
export HADOOP_COMMON_HOME=~/hadoop-2.7.0
配置环境变量
sudo nano /etc/environment
增加hadoop配置
将下面添加到变量PATH中
/home/aboutyun/hadoop-2.7.0/bin:/home/aboutyun/hadoop-2.7.0/sbin:
########################################################
3.本地模式验证[可忽略]
所谓的本地模式:在运行程序的时候,比如wordcount是在本地磁盘运行的
上面已经配置完毕,我们对其测试,分别执行面命令:
注意: bin/hadoop的执行条件是在hadoop_home中,我这里是
$ mkdir input
$ cp etc/hadoop/*.xml input
$bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
$ cat output/*
##################################################################
上面本地模式,我们知道就可以,我们下面继续配置伪分布模式
4.伪分布模式
我这里的全路径:/home/aboutyun/hadoop-2.7.0/etc/hadoop
修改文件etc/hadoop/core-site.xml
添加如下内容:
含义:接收Client连接的RPC端口,用于获取文件系统metadata信息。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改etc/hadoop/hdfs-site.xml:
添加如下内容:
含义:备份只有一份
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
5.伪分布模式
1.格式化namenode
hdfs namenode -format
有的地方使用
bin/hdfs namenode -format
如果配置的环境变量直接使用hdfs namenode -format即可
2.启动集群
start-dfs.sh
这时候单节点伪分布就已经安装成功了
验证
输入下面
http://localhost:50070/
如果是在虚拟机中安装,但是在宿主主机中访问,需要输入虚拟机ip地址
这里虚拟机ip地址是10.0.0.81
所以,我这里是
http://10.0.0.81:50070/
配置到这里也是可以的,我们同样可以运行wordcount,也就是我们的mapreduce不运行在yarn上。如果想让程序运行在yarn上,继续下面配置
#####################################################
6.配置Yarn
1.修改配置文件
修改配置文件mapred-site.xml
编辑文件etc/hadoop/mapred-site.xml,添加下面内容由于etc/hadoop中没有mapred-site.xml,所以对mapred-queues.xml.template复制一份
cp mapred-site.xml.template mapred-site.xml
然后编辑文件mapred-site.xml
添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
最后形式:
修改配置文件yarn-site.xml
添加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2.启动yarn
start-yarn.sh
(由于我这里已经配置了环境变来那个,所以在哪个地方都可以运行start-yarn.sh)
如果你没有配置环境变量,则需要进入hadoop_home,执行下面命令
sbin/start-yarn.sh
3.验证
启动yarn之后,输入
http://localhost:8088/
即可看到下面界面
遇到问题
问题1:
Error: Could not find or load main class
org.apache.hadoop.hdfs.server.namenode.NameNode
解决办法:
在~/hadoop-2.7.0/etc/hadoop/hadoop-env.sh中添加
export HADOOP_COMMON_HOME=~/hadoop-2.7.0
重启生效
问题2:
格式化Java_home not found
bin/hdfs namenode -format
在/etc/environment 中添加
export JAVA_HOME=/usr/jdk
生效
source /etc/environment
重启[如还不行,重启]
sudo init 6
hadoop2.7【单节点】单机、伪分布、分布式安装指导的更多相关文章
- Hadoop2.6.0安装—单机/伪分布
目录 环境准备 创建hadoop用户 更新apt 配置SSH免密登陆 安装配置Java环境 安装Hadoop Hadoop单机/伪分布配置 单机Hadoop 伪分布Hadoop 启动Hadoop 停止 ...
- Hadoop 2.2.0单节点的伪分布集成环境搭建
Hadoop版本发展历史 第一代Hadoop被称为Hadoop 1.0 1)0.20.x 2)0.21.x 3)0.22.x 第二代Hadoop被称为Hadoop 2.0(HDFS Federatio ...
- (一)Hadoop1.2.1安装——单节点方式和单机伪分布方式
Hadoop1.2.1安装——单节点方式和单机伪分布方式 一. 需求部分 在Linux上安装Hadoop之前,需要先安装两个程序: 1)JDK 1.6(或更高版本).Hadoop是用Java编写的 ...
- Greenplum/Deepgreen(单机/伪分布)安装文档
Greenplum/Deepgreen数据库安装(单机/伪分布) 首先去官网下载centos7:https://www.centos.org/download/,选择其中一个镜像下载即可,网上随意下载 ...
- Dubbo入门到精通学习笔记(八):ActiveMQ的安装与使用(单节点)、Redis的安装与使用(单节点)、FastDFS分布式文件系统的安装与使用(单节点)
文章目录 ActiveMQ的安装与使用(单节点) 安装(单节点) 使用 目录结构 edu-common-parent edu-demo-mqproducer edu-demo-mqconsumer 测 ...
- hbase 单机+伪分布环境搭建学习-1
1.单机模式: (1)编辑hbase-env.sh user@EBJ1023.local:/usr/local/flume_kafka_stom/hbase_1.1.2> vim conf/hb ...
- hadoop集群搭建——单节点(伪分布式)
1. 准备工作: 前提:需要电脑安装VM,且VM上安装一个Linux系统 注意:本人是在学习完尚学堂视频后,结合自己的理解,在这里做的总结.学习的视频是:大数据. 为了区分是在哪一台机器做的操作,eg ...
- hadoop-2.3.0-cdh5.1.0伪分布安装(基于centos)
一.环境 操作系统:CentOS 6.5 64位操作系统 注:Hadoop2.0以上采用的是jdk环境是1.7,Linux自带的jdk卸载掉,重新安装 下载地址:http://www.oracle. ...
- hadoop2.7单节点
$ sudo apt-get install ssh$ sudo apt-get install rsync 修改文件 etc/hadoop/hadoop-env.sh # set to the ro ...
- Giraph之SSSP(shortest path)单机伪分布运行成功
所遇问题:Exception 1: Exception in thread "main" java.lang.IllegalArgumentException: "che ...
随机推荐
- 65. Valid Number
题目: Validate if a given string is numeric. Some examples:"0" => true" 0.1 " = ...
- 34. Search for a Range
题目: Given a sorted array of integers, find the starting and ending position of a given target value. ...
- 1、创建一个JPA project(解决“at least one user library must be selected”问题)
(注:本系列笔记是在学习尚硅谷JPA课程的时候写下的,结合课程内容和自我理解,方便自己以后进行复习) 一.在创建JPA之前看看什么是JPA 1.Java Persistence API:用于对象持久化 ...
- 基于条件随机场(CRF)的命名实体识别
很久前做过一个命名实体识别的模块,现在有时间,记录一下. 一.要识别的对象 人名.地名.机构名 二.主要方法 1.使用CRF模型进行识别(识别对象都是最基础的序列,所以使用了好评率较高的序列识别算法C ...
- 04-语言入门-04-Fibonacci数
地址: http://acm.nyist.net/JudgeOnline/problem.php?pid=13 描述 无穷数列1,1,2,3,5,8,13,21,34,55...称为Fibona ...
- Pig简单入门
pig是hadoop客户端,使用类似于SQL的面向数据流的语言pig latin,这个语言可以完成排序,过滤,求和,关联等操作,可以支持自定义函数.Pig自动把pig latin 映射为Map-Red ...
- chrome下float元素下input选中内容bug
今天在写一个小demo的时候,发现chrome下一个很奇怪的bug. 我的代码如下: <!DOCTYPE html> <html lang="en"> &l ...
- 函数fil_node_create
/*******************************************************************//** Appends a new file to the c ...
- 【笨嘴拙舌WINDOWS】编码历史
在介绍历史之前,有必要将一个经常使用的词语"标准"解释一下: " 标准是"为了在一定的范围内获得最佳秩序,经协商一致制定并由公认机构批准,共同使用的和重复使用的 ...
- iOS开发:Swift多线程NSThread的使用
一:创建线程,NSThread创建线程常用的三种方式: //1:手动创建启动 let thread:NSThread = NSThread(target: self, selector:"d ...