Flume与Kafka集成
一、Flume介绍
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
设计目标:
- 可靠性当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。
- 可扩展性Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
- 可管理性所有agent和colletor由master统一管理,这使得系统便于维护。多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。
- 功能可扩展性用户可以根据需要添加自己的agent,collector或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
一般实时系统,所选用组件如下:
数据采集 :负责从各节点上实时采集数据,选用cloudera的flume来实现
数据接入 :由于采集数据的速度和数据处理的速度不一定同步,因此添加一个消息中间件来作为缓冲,选用apache的kafka
流式计算 :对采集到的数据进行实时分析,选用apache的storm
数据输出 :对分析后的结果持久化,暂定用mysql ,另一方面是模块化之后,假如当Storm挂掉了之后,数据采集和数据接入还是继续在跑着,数据不会丢失,storm起来之后可以继续进行流式计算;
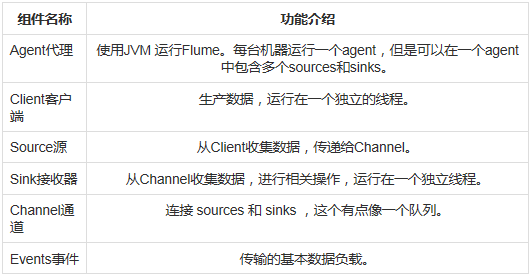
二、Flume 的 一些核心概念
其它参数配置请参见:http://itindex.net/detail/56260-flume-kafka-hdfs
http://www.jianshu.com/p/f0a08bd4f975
三、Flume的整体构成图
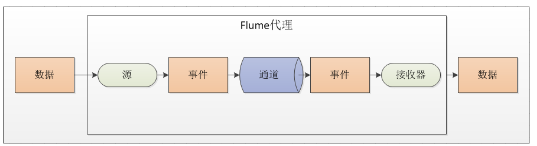
注意:(1)源将事件写到一个多或者多个通道中;(2)接收器只从一个通道接收事件;(3)代理可能会有多个源、通道与接收器。
四、常用配置模式
常用配置模式一:扫描指定文件
agent.sources.s1.type=exec
agent.sources.s1.command=tail -F /Users/it-od-m/Downloads/abc.log
agent.sources.s1.channels=c1
agent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100 #设置Kafka接收器
agent.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
agent.sinks.k1.brokerList=127.0.0.1:9092
#设置Kafka的Topic
agent.sinks.k1.topic=testKJ1
#设置序列化方式
agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder agent.sinks.k1.channel=c1
常用配置模式二
Agent名称定义为agent.
Source:可以理解为输入端,定义名称为s1
channel:传输频道,定义为c1,设置为内存模式
sinks:可以理解为输出端,定义为sk1, agent.sources = s1
agent.channels = c1
agent.sinks = sk1 #设置Source的内省为netcat 端口为5678,使用的channel为c1
agent.sources.s1.type = netcat
agent.sources.s1.bind = localhost
agent.sources.s1.port = 3456
agent.sources.s1.channels = c1 #设置Sink为logger模式,使用的channel为c1
agent.sinks.sk1.type = logger
agent.sinks.sk1.channel = c1
#设置channel信息
agent.channels.c1.type = memory #内存模式
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100 #传输参数设置。
常用配置模式三:扫描目录新增文件
agent.sources = s1
agent.channels = c1
agent.sinks = sk1 #设置spooldir
agent.sources.s1.type = spooldir
agent.sources.s1.spoolDir = /Users/it-od-m/logs
agent.sources.s1.fileHeader = true agent.sources.s1.channels = c1
agent.sinks.sk1.type = logger
agent.sinks.sk1.channel = c1 #In Memory !!!
agent.channels.c1.type = memory
agent.channels.c1.capacity = 10004
agent.channels.c1.transactionCapacity = 100
与Kafka结合时,通常采用第一种模式。
配置好参数以后,使用如下命令启动Flume:
./bin/flume-ng agent -n agent -c conf -f conf/hw.conf -Dflume.root.logger=INFO,console
最后一行显示Component type:SINK,name:k1 started表示启动成功.
说明:在启动Flume之前,Zookeeper和Kafka要先启动成功,不然启动Flume会报连不上Kafka的错误。
原文参见:http://www.jianshu.com/p/f0a08bd4f975
Flume与Kafka集成的更多相关文章
- 新闻实时分析系统-Flume+HBase+Kafka集成与开发
1.下载Flume源码并导入Idea开发工具 1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压 2)通过idea导入flume源码 打开idea开发工具,选择File ...
- 新闻网大数据实时分析可视化系统项目——9、Flume+HBase+Kafka集成与开发
1.下载Flume源码并导入Idea开发工具 1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压 2)通过idea导入flume源码 打开idea开发工具,选择File ...
- Flume+HBase+Kafka集成与开发
先把flume1.7的源码包下载 http://archive.apache.org/dist/flume/1.7.0/ 下载解压后 我们通过IDEA这个软件来打开这个工程 点击ok后我们选择打开一个 ...
- flume+kafka+hbase+ELK
一.架构方案如下图: 二.各个组件的安装方案如下: 1).zookeeper+kafka http://www.cnblogs.com/super-d2/p/4534323.html 2)hbase ...
- 数据采集组件:Flume基础用法和Kafka集成
本文源码:GitHub || GitEE 一.Flume简介 1.基础描述 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中 ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- Flume+LOG4J+Kafka
基于Flume+LOG4J+Kafka的日志采集架构方案 本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具, ...
- 使用Flume消费Kafka数据到HDFS
1.概述 对于数据的转发,Kafka是一个不错的选择.Kafka能够装载数据到消息队列,然后等待其他业务场景去消费这些数据,Kafka的应用接口API非常的丰富,支持各种存储介质,例如HDFS.HBa ...
- 纪录:Solr6.4.2+Flume1.7.0 +morphline+kafka集成
当前大多数企业版hadoop的solr版本都还停留在solr4.x,由于这个版本的solr本身的bug较多,使用起来会出很多奇怪的问题.如部分更新日期字段失败的问题. 最新的solr版本不仅修复了以前 ...
随机推荐
- android UI开源库
. ActionBarSherlock ActionBarSherlock是一个独立的Android设计库,可以让Android 2.x的系统也能使用ActionBar.此 外,ActionBarSh ...
- 检查.net代码中占用高内存函数(翻译)
哈哈,昨天没事做,在CodeProject瞎逛,偶然看到这篇文章,居然读得懂,于是就翻译了一下,当练习英语,同时增强对文章的理解,发现再次翻译对于文章的一些细节问题又有更好的理解.下面是翻译内容,虽然 ...
- InteractivePNG
在as3中很多时候需要只能选中png中可视区域,即透明区域“感觉可以穿透”.
- jsp与El,jstl知识点总结归纳
jsp与El,jstl知识点总结归纳 jsp部分 一.jsp的三大指令 page ,include,taglib 1.jsp中的page指令 <% page %>-设置jsp 例如: &l ...
- 如何自学Java 经典
JAVA自学之路 JAVA自学之路 一:学会选择 为了就业,不少同学参加各种各样的培训. 决心做软件的,大多数人选的是java,或是.net,也有一些选择了手机.嵌入式.游戏.3G.测试等. 那么究竟 ...
- web自己主动保存表单
note:当中部分源代码来源网络 所用的框架:jquery 实现的功能: 1.自己主动保存表单 2.页面刷新的时候把自己主动保存的值赋值给表单元素 思路: 1.表单值改变的时候自己主动触发函数.保存表 ...
- jquery,extjs中的extend用法小结
在jquery中,extend其实在做插件时还是用的比较多的,今天同时小结jquery和ext js中 的extend用法,先来看jquery中的. 1) extend(dest,src1,src2 ...
- influxDB学习总结
1.安装 请参考http://www.cnblogs.com/zhja/p/5996191.html, 安装完毕运行influxd,http://域名:8083为控制台界面:http://域名:808 ...
- C#将html导出到word(基于wps)
由于客户需要,我们需要实现将网页导出到word中的功能,在此过程中,尝试使用过openoffice.itext.wordapi等各种方法,都不尽如人意.openoffice导出的问题图片信息在word ...
- 简单的新浪微博OAuth认证实现
System.setProperty("weibo4j.oauth.consumerKey", Weibo.CONSUMER_KEY); System.setProperty(&q ...