Kafka入门学习随记(二)
====Kafka消费者模型
参考博客:http://www.tuicool.com/articles/fI7J3m
--分区消费模型
分区消费架构图
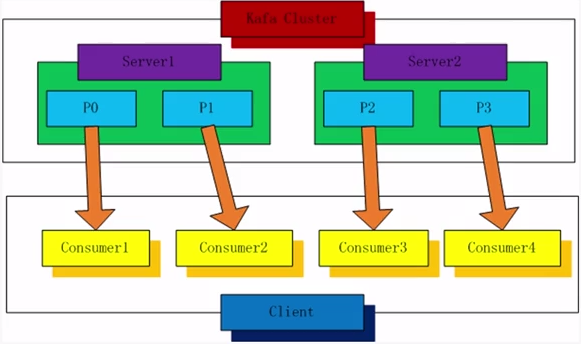
图中kafka集群有两台服务器(Server),每台服务器有2个分区(Patition),共4个分区。
由四个消费者实例(Consumer)来消费4个分区。
当然,Consumer1不一定对应Patition1,但是必须建立1对1的对应关系。
分区消费伪代码描述

--组(Group)消费模型
组消费架构图
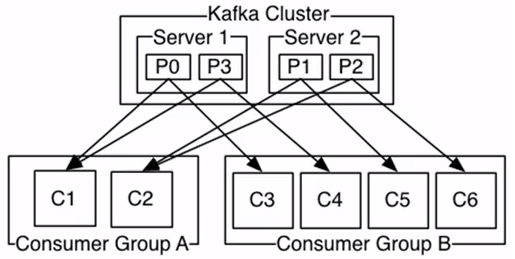
途中有两个服务器Server1和Server2,每个服务器上有2个Patiton分区。
有两个组(Consumer Group)。其中,
Consumer Group A中用2个Consumer实例来消费集群当前主题(Topic)中的4个Patition。
Consumer Group B中用4个Consumer实例来消费集群当前主题(Topic)中的4个Patition。
两个Group都可以拿到当前主题(Topic)的全量数据(这点很重要)。
--按组(Group)消费伪代码描述

*流数N:即每个Consumer Group组里面有多少个Consumer实例。
Consumer分配方法

--Java客户端参数调优
(1)FetchSize:从服务器获取单包大小
(2)bufferSize:kafka客户端缓冲区大小
(3)group.id:分区组消费时分组名
--两种消费模型对比
分区消费模型更加灵活,但是:
(1)需要自己处理各种异常情况
(2)需要自己管理offset(以实现消息传递的其他语义)
组消费模型更加简单,但是不灵活
(1)不需要自己处理异常情况,不需要自己管理offset
(2)只能实现kafka默认的最少一次消息传递语义
*消息传递语义有三种:至少一次、最多一次、有且只有一次
====kafka生产者模型
--同步生产模型
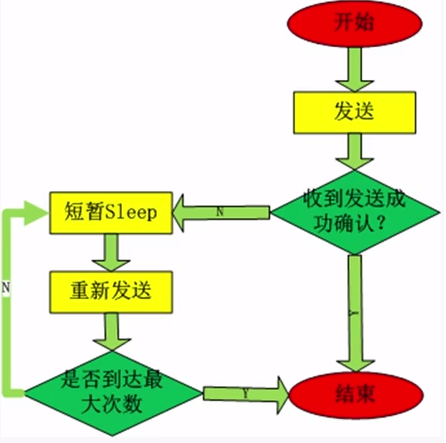
使用同步生产模型时,提供“至少一次”的语义。
--异步生产模型
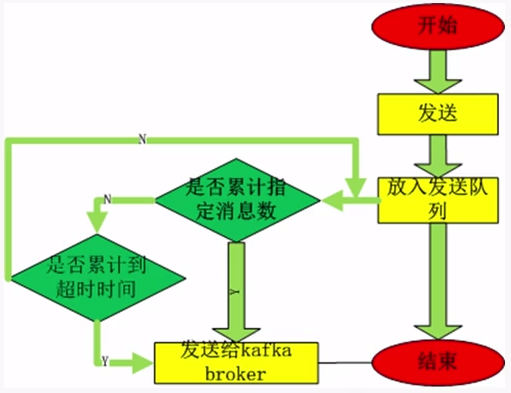
--两种生产模型的伪代码描述

*kafka默认负载均衡算法有:哈希、轮训、随机
*根据设置生产者参数来决定是同步/异步生产模型。
--Java客户端参数调优
(1)message.sen.max.retries:发送失败重试次数;
(2)retry.backoff.ms:未接到确认,认为发送失败的时间;
(3)producer.type:同步发送或者异步发送;
(4)batch.num.messages:异步发送时,累计最大消息数;
(5)queue.buffering.max.ms:异步发送时,累计最大时间;
--两种生产模型对比
同步生产模型:
(1)低消息丢失率
(2)高消息重复率(由于网络原因,回复确认未收到)
(3)高延迟、低吞吐量
异步生产模型:
(1)低延迟
(2)高发送性能
(3)高消息丢失率(无确认机制,发送端队列满)
====kafka中关键参数配置
参考博客:http://debugo.com/kafka-params/
(1)Broker(集群总的节点)配置
•broker.id:唯一确定的一个int 类型数字
•log.dirs:存储kafka数据,默认路径为/tmp/kafka-logs
•port:comsumer连接的端口号
•zookeeper.conect:zookeeper的链接字符串,定义的格式如下hostname1:port1,hostname2:port2,hostname3
•num.partitions:一个topic可以被分成多个paritions管道,每个partiions中的message有序,但是多个paritions中的顺序不能保证
(2)Consumer 配置
•group.id:string类型,决定该Consumer归属的唯一组ID。
•zookeeper.connect:对于zookeeper集群的指定,必须和broker使用同样的zk配置。host1:port1,host2:port2。
•zookeeper.session.timeout.ms:zookeeper的心跳超时时间,查过这个时间就认为是无效的消费者
•zookeeper.sync.time.ms:zookeeper的等待连接时间
•auto.commit.interval.ms:自动提交的时间间隔
(3)Producer配置
•metadata.book.list:消费者获取消息元信息,格式为host1:port1,host2:port2
•serializer.class:message的序列化类。默认编码器处理类型都是byte[]类型
•partitioner.class:分区的策略,默认是取模
•producer.type:确定messages是否同步提交
•request.required.acks:消息的确认模式。
#0:不保证消息的到达确认,只管发送,低延迟但是会出现消息的丢失,在某个server失败的情况下,有点像TCP
#1:发送消息,并会等待leader 收到确认后,一定的可靠性
#-1:发送消息,等待leader收到确认,并进行复制操作后,才返回,最高的可靠性
====kafka客户端API
--Kafka Producer APIs
Procuder API有两种:
•kafka.producer.SyncProducer
•kafka.producer.async.AsyncProducer
它们都实现了同一个接口:
class Producer {
/* 将消息发送到指定分区 */
publicvoid send(kafka.javaapi.producer.ProducerData<K,V> producerData);
/* 批量发送一批消息 */
publicvoid send(java.util.List<kafka.javaapi.producer.ProducerData<K,V>> producerData);
/* 关闭producer */
publicvoid close();
}
Producer API提供了以下功能:
(1)可以将多个消息缓存到本地队列里,然后异步的批量发送到broker,可以通过参数producer.type=async做到,
缓存的大小可以通过一些参数指定:queue.time和batch.size。
一个后台线程(kafka.producer.async.ProducerSendThread)从队列中取出数据,并让kafka.producer.EventHandler将消息发送到broker,
也可以通过参数event.handler定制handler,在producer端处理数据的不同的阶段注册处理器,比如可以对这一过程进行日志追踪,或进行一些监控。
只需实现kafka.producer.async.CallbackHandler接口,并在callback.handler中配置。
(2)自己编写Encoder来序列化消息,只需实现下面这个接口。默认的Encoder是kafka.serializer.DefaultEncoder。
interface Encoder<T> {
public Message toMessage(T data);
}
(3)提供了基于Zookeeper的broker自动感知能力,可以通过参数zk.connect实现。
如果不使用Zookeeper,也可以使用broker.list参数指定一个静态的brokers列表,
这样消息将被随机的发送到一个broker上,一旦选中的broker失败了,消息发送也就失败了。
(4)通过分区函数kafka.producer.Partitioner类对消息分区。
interface Partitioner<T> {
int partition(T key, int numPartitions);
}
分区函数有两个参数:key和可用的分区数量,从分区列表中选择一个分区并返回id。
默认的分区策略是hash(key)%numPartitions.如果key是null,就随机的选择一个。
可以通过参数partitioner.class定制分区函数。
--KafKa Consumer APIs
Consumer API有两个级别。
低级别的和一个指定的broker保持连接,并在接收完消息后关闭连接,这个级别是无状态的,每次读取消息都带着offset。
高级别的API隐藏了和brokers连接的细节,在不必关心服务端架构的情况下和服务端通信。还可以自己维护消费状态,并可以通过一些条件指定订阅特定的topic,比如白名单黑名单或者正则表达式。
(1)低级别的API
低级别的API是高级别API实现的基础,也是为了一些对维持消费状态有特殊需求的场景,比如Hadoop consumer这样的离线consumer。
-----------------
class SimpleConsumer {
/* 向一个broker发送读取请求并得到消息集 */
public ByteBufferMessageSet fetch(FetchRequest request);
/* 向一个broker发送读取请求并得到一个相应集 */
public MultiFetchResponse multifetch(List<FetchRequest> fetches);
/**
* 得到指定时间之前的offsets
* 返回值是offsets列表,以倒序排序
* @param time: 时间,毫秒,
* 如果指定为OffsetRequest$.MODULE$.LATIEST_TIME(), 得到最新的offset.
* 如果指定为OffsetRequest$.MODULE$.EARLIEST_TIME(),得到最老的offset.
*/
publiclong[] getOffsetsBefore(String topic, int partition, long time, int maxNumOffsets);
}
-----------------
(2)高级别的API
这个API围绕着由KafkaStream实现的迭代器展开,每个流代表一系列从一个或多个分区多和broker上汇聚来的消息,
每个流由一个线程处理,所以客户端可以在创建的时候通过参数指定想要几个流。
一个流是多个分区多个broker的合并,但是每个分区的消息只会流向一个流。
每调用一次createMessageStreams都会将consumer注册到topic上,这样consumer和brokers之间的负载均衡就会进行调整。
API鼓励每次调用创建更多的topic流以减少这种调整。
createMessageStreamsByFilter方法注册监听可以感知新的符合filter的topic。
-----------------
/* 创建连接 */
ConsumerConnector connector = Consumer.create(consumerConfig);
interface ConsumerConnector {
/**
* 这个方法可以得到一个流的列表,每个流都是MessageAndMetadata的迭代,通过MessageAndMetadata可以拿到消息和其他的元数据(目前之后topic)
* Input: a map of <topic, #streams>
* Output: a map of <topic, list of message streams>
*/
public Map<String,List<KafkaStream>> createMessageStreams(Map<String,Int> topicCountMap);
/**
* 你也可以得到一个流的列表,它包含了符合TopicFiler的消息的迭代,
* 一个TopicFilter是一个封装了白名单或黑名单的正则表达式。
*/
public List<KafkaStream> createMessageStreamsByFilter(TopicFilter topicFilter, int numStreams);
/* 提交目前消费到的offset */
public commitOffsets()
/* 关闭连接 */
public shutdown()
}
-----------------
====kafka消息组织原理
--磁盘重认识
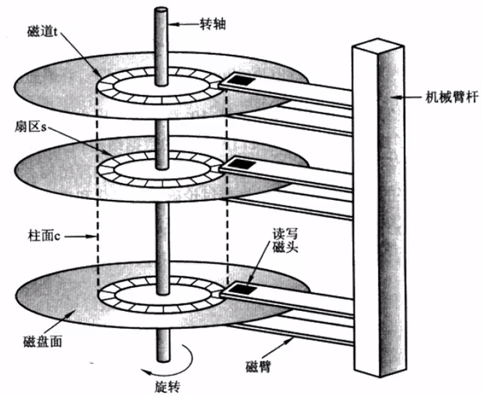
当需要从磁盘读取数据时,要确定读的数据在哪个磁道,哪个扇区:
(1)首先必须找到柱面,即磁头需要移动对准相应磁道,这个过程叫寻道,所需时间叫寻道时间。
(2)然后目标扇区旋转到次投下,这个过程消费的时间叫旋转时间
一次访问请求(读/写)完成过程由三个动作组成
(1)寻道(时间):磁头移动定位到指定磁道
(2)旋转延迟(时间):等待指定扇区从磁头下旋转经过
(3)数据传输(时间):数据在磁盘、内存与网络之间的实际传输
由于存储介质的特性,磁盘本身存取就比主存慢,再加上机械运动耗费,磁盘存取速度往往是主存的几百分之一甚至几千分之一。
--怎样才能提高磁盘的读写效率呢?
根据数据的局部性原理,有以下两种方法
(1)预读或者提前读
(2)合并写--将多个逻辑上的写操作合并成一个大的物理写操作中。
即采用磁盘顺序读写(不需要寻道时间,只需要很少的旋转时间)。
实验结果:在一个67200rpm SATA RAID-5的磁盘真累上线性写的速度大概是300M/秒,
但是随机写的速度只有50K/秒,两者相差奖金10000倍。
--kafka消息的写入原理
一般的将数据从文件传到套接字的路径:
(1)操作系统将数据从磁盘读到内核空间的页缓存区
(2)应用将数据从内核空间读到用户空间的缓存中
(3)应用将数据写会内存空间的套接字缓存中
(4)操作系统将数据从套接字缓存写到网卡缓存中,以便将数据经网络发出
这样做明显是抵消的,这里有四次拷贝,两次系统调用。
如果使用sendfile(Java为:FileChannel.transferTo api),两次拷贝可以被避免:
允许操作系统将数据直接从页缓存发送到网络上。优化后,只有最后一步将数据拷贝到网卡缓存中。
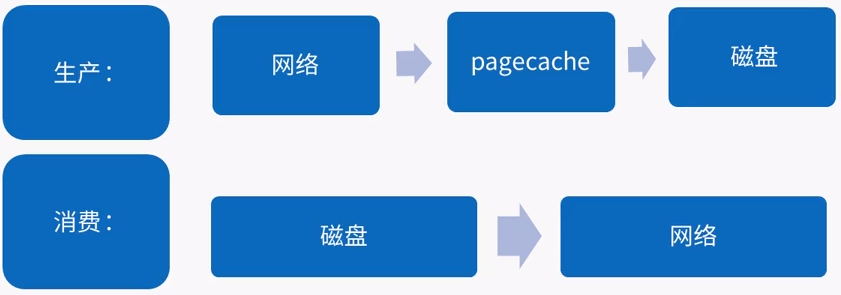
kafka的内部设计有两个重要的知识点:
(1)基于磁盘的顺序写
(2)基于数据的0字节拷贝(Byte Zero Copy)
====生产者消费者代码例子
https://github.com/quchunhui/kafkaSample
Kafka入门学习随记(二)的更多相关文章
- SCARA——OpenGL入门学习一、二
参考博客:http://www.cppblog.com/doing5552/archive/2009/01/08/71532.html 简介 最近开始一个机械手臂的安装调试,平面关节型机器人又称SCA ...
- redis入门学习记录(二)
继第一节 redis入门学习记录(一)之后,我们来学习redis的基本使用. 接下来我们看看/usr/local/redis/bin目录下的几个文件作用是什么? redis-benchmark:red ...
- Java超简明入门学习笔记(二)
Java编程思想第4版学习笔记(二) 第三章 操作符 & 第四章 控制执行流程(流程控制语句) 第三章和第四章的内容主要是讲操作符和流程控制语句,Java的大多数操作符和流程控 ...
- Ext入门学习系列(二)弹出窗体
第二章 弹出窗体 上节学习了Ext的环境搭建和最基本的一个操作——弹出对话框,作为一个引子,本节讲述如何弹出一个新窗体,从实例讲解Ext的基本运行原理. 一.Ext的窗体长什么样? 先来看看几个效果, ...
- Python入门 学习笔记 (二)
今天学习了一些简单的语法规则,话不多说,开始了: 二.数据类型 常用数据类型中的整形和浮点型就不多说了. 1.字符串 ...
- Kafka -入门学习
kafka 1. 介绍 官网 http://kafka.apache.org/ 介绍 http://kafka.apache.org/intro 2. 快速开始 1. 安装 路径: http://ka ...
- PyQt4入门学习笔记(二)
之前第一篇介绍了pyqt4的大小,移动位置,消息提示.这次我们介绍菜单和工具栏 QtGui.QmainWindow这个类可以给我们提供一个创建带有状态栏.工具栏和菜单栏的标准的应用. 状态栏 状态栏是 ...
- 【转】MYSQL入门学习之十二:存储过程的基本操作
转载地址:http://www.2cto.com/database/201212/177380.html 存储过程简单来说,就是为以后的使用而保存的一条或多条MySQL语句的集合.可将其视为批文件,虽 ...
- Kafka入门学习(一)
====常用开源分布式消息系统 *集群:多台机器组成的系统叫集群. *ActiveMQ还是支持JMS的一种消息中间件. *阿里巴巴metaq,rocketmq都有kafka的影子. *kafka的动态 ...
随机推荐
- Kendo UI - Observable
在 Kendo 中,基类 Class 第一个重要的派生类就是 Observable, 顾名思义,就是一个可观察的对象,也就是观察者模式的基础. 对于观察者模式来说,应该有主题和观察者,这里我们讨论的其 ...
- Android系统下检测Wifi连接互联网是否正常的代码
/** * * 判断网络状态是否可用 * * @return true: 网络可用 ; false: 网络不可用 */ public boolean isConnectInternet ...
- python连mysql时避免出现乱码
使用python连mysql时候,常常出现乱码,采取以下措施可以避免 1 Python文件设置编码 utf-8 (文件前面加上 #encoding=utf-8)2 MySQL数据库charset=ut ...
- C++历史(The History of C++)
C++历史 早期C++ •1979: 首次实现引入类的C(C with Classes first implemented) 1.新特性:类.成员函数.继承类.独立编译.公共和私有访问控制.友元.函数 ...
- mistral 工作流组件之二 思维导图
Mistral 思维导图
- 学习练习 Oracle数据库小题
Course(课程表) Score(成绩表) Teacher(教师表)
- 华为OJ平台——统计字符串中的大写字母
题目描述: 统计字符串中的大写字母的个数 输入: 一行字符串 输出: 字符串中大写字母的个数(当空串时输出0) 思路: 这一题很简单,直接判断字符串中的每一个字符即可,唯一要注意的一点是输入的字符串可 ...
- js种的循环语句
//js种的循环语句 //while与do while的区别是while是满足条件后才执行 //do while是不管满不满足条件都会执行一次 //for 循环与while,do while相比循环结 ...
- jquery ajax 保存讲解
jquery ajax 参数传递与数据保存实例是一款适合于初学者用的,首先我们是讲一下关于如何利用ajax +php进行数据操作,然后再详细的介绍关于jquery ajax的帮助说明. jquery ...
- (笔记)安装npm需要更改代理kneesocks 1081 1080