中文分词之结巴分词~~~附使用场景+demo(net)
常用技能(更新ing):http://www.cnblogs.com/dunitian/p/4822808.html#skill
技能总纲(更新ing):http://www.cnblogs.com/dunitian/p/5493793.html
在线演示:http://cppjieba-webdemo.herokuapp.com
完整demo:https://github.com/dunitian/TempCode/tree/master/2016-09-05
逆天修改版:https://github.com/dunitian/TempCode/blob/master/2016-09-05/jieba.NET.0.38.2.zip
先说下注意点,结巴分词他没有对分词进行一次去重,我们得自己干这件事;字典得自行配置或者设置成输出到bin目录
应用场景举例(搜索那块大家都知道,说点其他的)
——————————————————————————————————————————————————
言归正传:看一组民间统计数据:(非Net版,指的是官方版)
net版的IKanalyzer和盘古分词好多年没更新了,所以这次选择了结巴分词(这个名字也很符合分词的意境~~结巴说话,是不是也是一种分词的方式呢?)
下面简单演示一下:
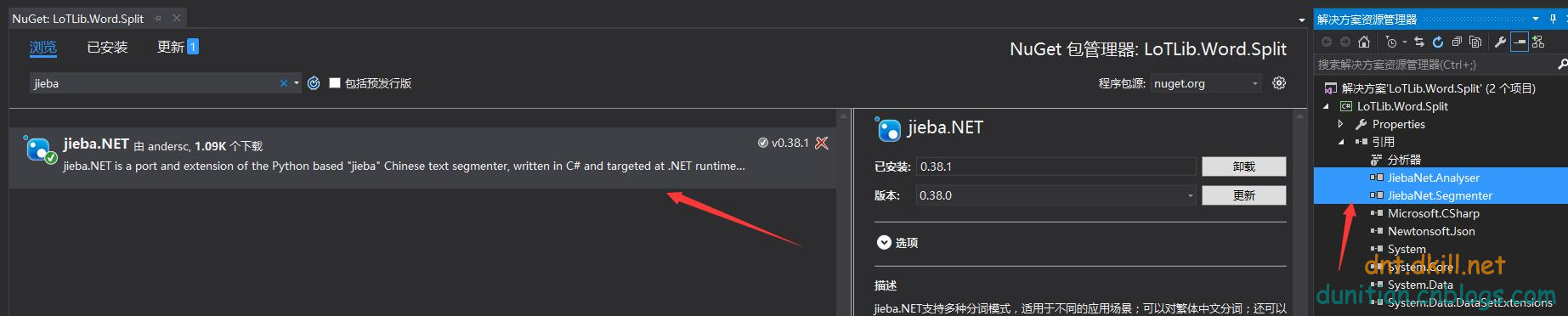
1.先引入包:
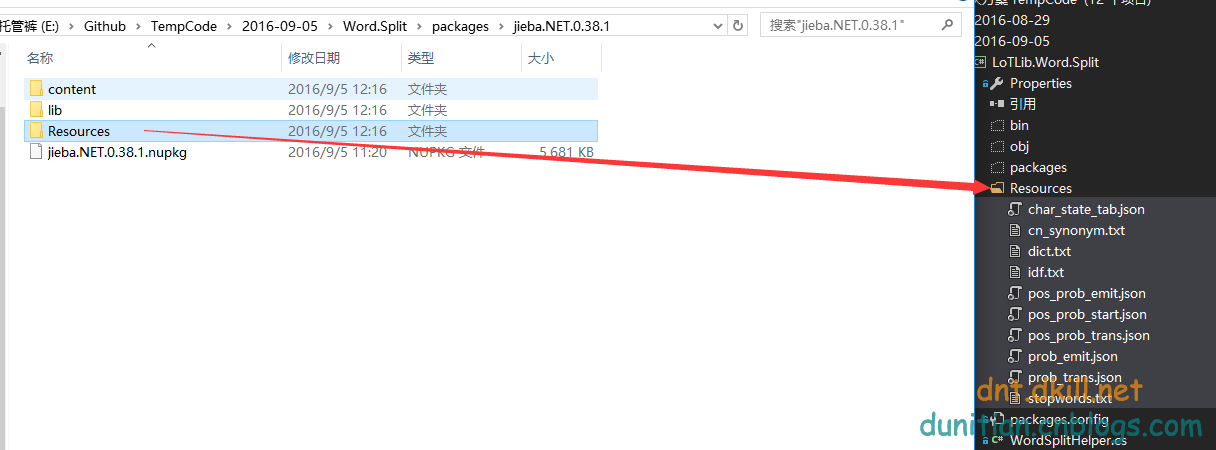
2.字典设置:
3.简单封装的帮助类:
- using System.Linq;
- using JiebaNet.Segmenter;
- using System.Collections.Generic;
- namespace LoTLib.Word.Split
- {
- #region 分词类型
- public enum JiebaTypeEnum
- {
- /// <summary>
- /// 精确模式---最基础和自然的模式,试图将句子最精确地切开,适合文本分析
- /// </summary>
- Default,
- /// <summary>
- /// 全模式---可以成词的词语都扫描出来, 速度更快,但是不能解决歧义
- /// </summary>
- CutAll,
- /// <summary>
- /// 搜索引擎模式---在精确模式的基础上对长词再次切分,提高召回率,适合用于搜索引擎分词
- /// </summary>
- CutForSearch,
- /// <summary>
- /// 精确模式-不带HMM
- /// </summary>
- Other
- }
- #endregion
- /// <summary>
- /// 结巴分词
- /// </summary>
- public static partial class WordSplitHelper
- {
- /// <summary>
- /// 获取分词之后的字符串集合
- /// </summary>
- /// <param name="objStr"></param>
- /// <param name="type"></param>
- /// <returns></returns>
- public static IEnumerable<string> GetSplitWords(string objStr, JiebaTypeEnum type = JiebaTypeEnum.Default)
- {
- var jieba = new JiebaSegmenter();
- switch (type)
- {
- case JiebaTypeEnum.Default:
- return jieba.Cut(objStr); //精确模式-带HMM
- case JiebaTypeEnum.CutAll:
- return jieba.Cut(objStr, cutAll: true); //全模式
- case JiebaTypeEnum.CutForSearch:
- return jieba.CutForSearch(objStr); //搜索引擎模式
- default:
- return jieba.Cut(objStr, false, false); //精确模式-不带HMM
- }
- }
- /// <summary>
- /// 获取分词之后的字符串
- /// </summary>
- /// <param name="objStr"></param>
- /// <param name="type"></param>
- /// <returns></returns>
- public static string GetSplitWordStr(this string objStr, JiebaTypeEnum type = JiebaTypeEnum.Default)
- {
- var words = GetSplitWords(objStr, type);
- //没结果则返回空字符串
- if (words == null || words.Count() < 1)
- {
- return string.Empty;
- }
- words = words.Distinct();//有时候词有重复的,得自己处理一下
- return string.Join(",", words);//根据个人需求返回
- }
- }
- }
调用很简单:
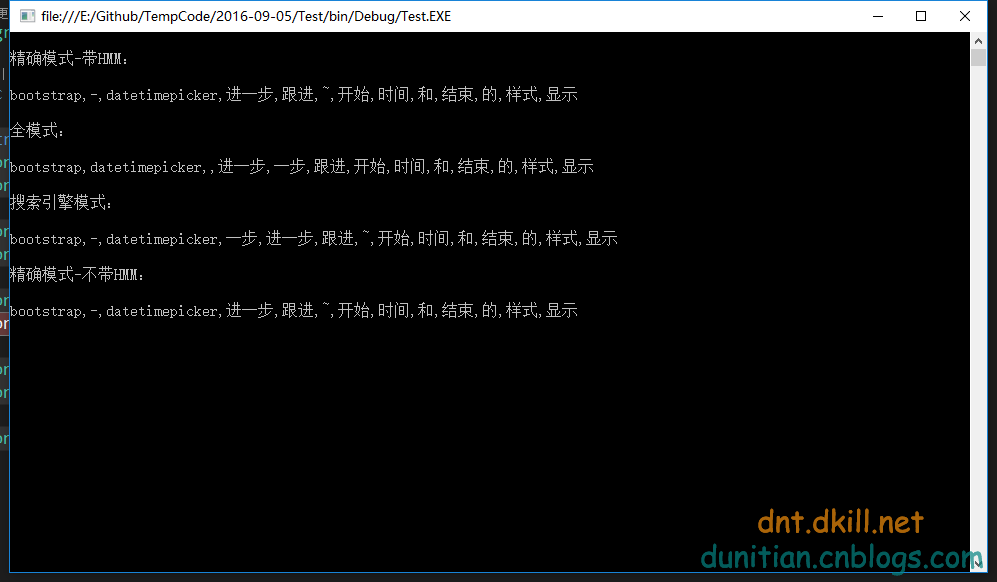
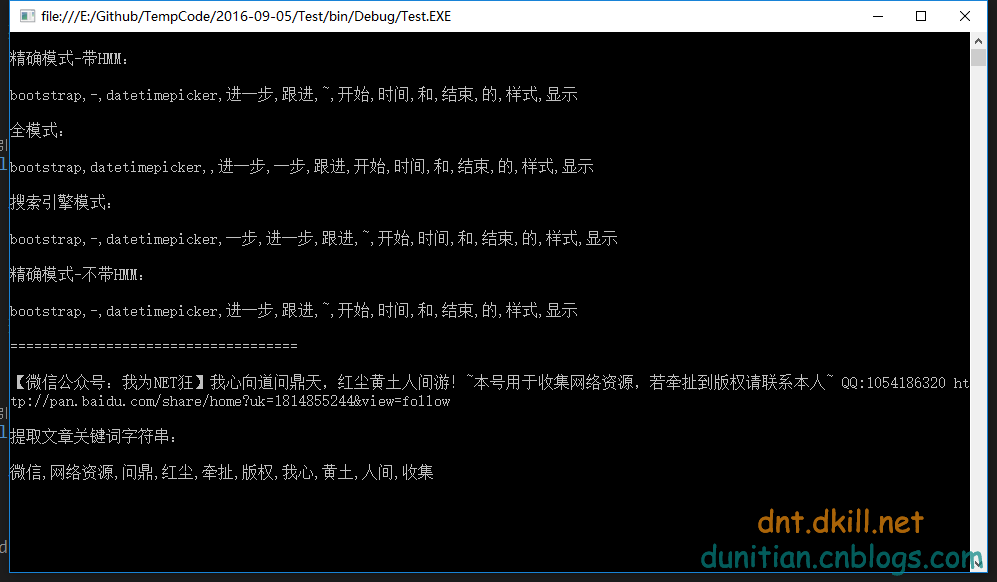
- string str = "bootstrap-datetimepicker 进一步跟进~~~开始时间和结束时间的样式显示";
- Console.WriteLine("\n精确模式-带HMM:\n");
- Console.WriteLine(str.GetSplitWordStr());
- Console.WriteLine("\n全模式:\n");
- Console.WriteLine(str.GetSplitWordStr(JiebaTypeEnum.CutAll));
- Console.WriteLine("\n搜索引擎模式:\n");
- Console.WriteLine(str.GetSplitWordStr(JiebaTypeEnum.CutForSearch));
- Console.WriteLine("\n精确模式-不带HMM:\n");
- Console.WriteLine(str.GetSplitWordStr(JiebaTypeEnum.Other));
- Console.ReadKey();
效果:
--------------------------
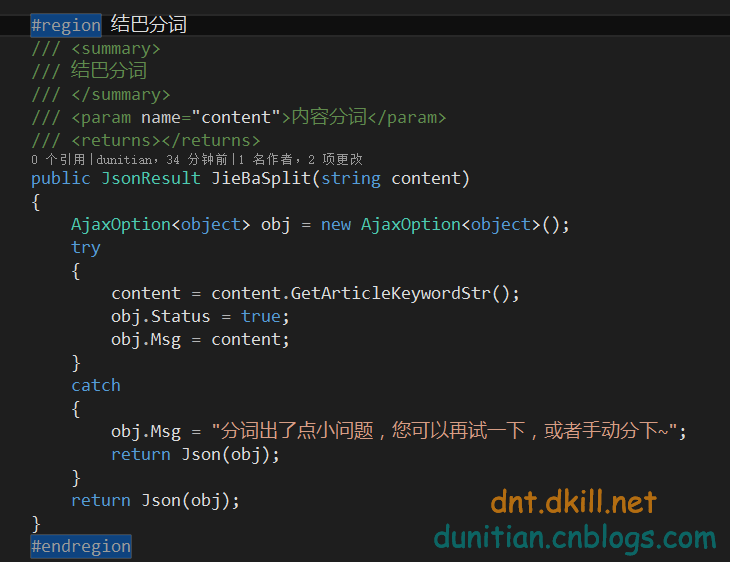
有人可能会说,那内容关键词提取呢?==》别急,看下面:
这种方式所对应的字典是它=》idf.txt
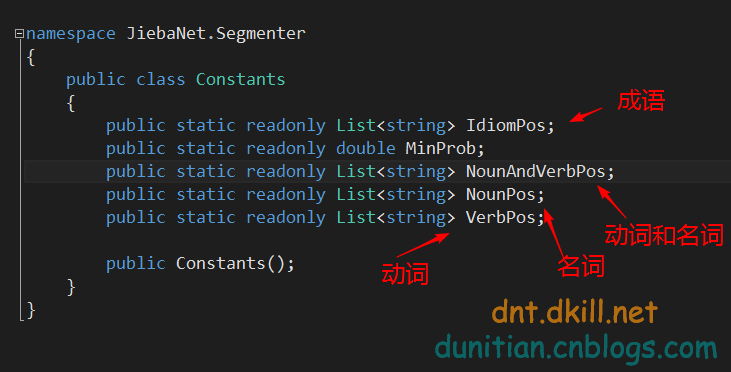
简单说下Constants==》
效果:
完整帮助类(最新看github):https://github.com/dunitian/TempCode/tree/master/2016-09-05
- using System.Linq;
- using JiebaNet.Segmenter;
- using System.Collections.Generic;
- using JiebaNet.Analyser;
- namespace LoTLib.Word.Split
- {
- #region 分词类型
- public enum JiebaTypeEnum
- {
- /// <summary>
- /// 精确模式---最基础和自然的模式,试图将句子最精确地切开,适合文本分析
- /// </summary>
- Default,
- /// <summary>
- /// 全模式---可以成词的词语都扫描出来, 速度更快,但是不能解决歧义
- /// </summary>
- CutAll,
- /// <summary>
- /// 搜索引擎模式---在精确模式的基础上对长词再次切分,提高召回率,适合用于搜索引擎分词
- /// </summary>
- CutForSearch,
- /// <summary>
- /// 精确模式-不带HMM
- /// </summary>
- Other
- }
- #endregion
- /// <summary>
- /// 结巴分词
- /// </summary>
- public static partial class WordSplitHelper
- {
- #region 公用系列
- /// <summary>
- /// 获取分词之后的字符串集合
- /// </summary>
- /// <param name="objStr"></param>
- /// <param name="type"></param>
- /// <returns></returns>
- public static IEnumerable<string> GetSplitWords(string objStr, JiebaTypeEnum type = JiebaTypeEnum.Default)
- {
- var jieba = new JiebaSegmenter();
- switch (type)
- {
- case JiebaTypeEnum.Default:
- return jieba.Cut(objStr); //精确模式-带HMM
- case JiebaTypeEnum.CutAll:
- return jieba.Cut(objStr, cutAll: true); //全模式
- case JiebaTypeEnum.CutForSearch:
- return jieba.CutForSearch(objStr); //搜索引擎模式
- default:
- return jieba.Cut(objStr, false, false); //精确模式-不带HMM
- }
- }
- /// <summary>
- /// 提取文章关键词集合
- /// </summary>
- /// <param name="objStr"></param>
- /// <returns></returns>
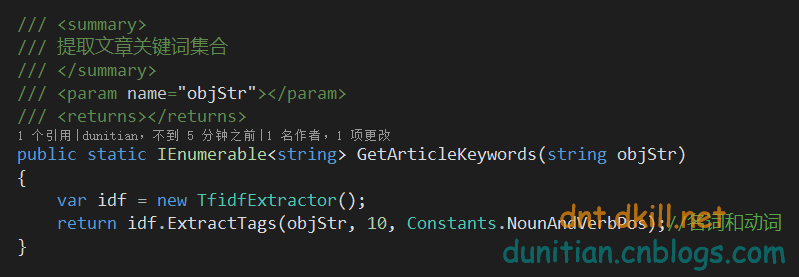
- public static IEnumerable<string> GetArticleKeywords(string objStr)
- {
- var idf = new TfidfExtractor();
- return idf.ExtractTags(objStr, 10, Constants.NounAndVerbPos);//名词和动词
- }
- /// <summary>
- /// 返回拼接后的字符串
- /// </summary>
- /// <param name="words"></param>
- /// <returns></returns>
- public static string JoinKeyWords(IEnumerable<string> words)
- {
- //没结果则返回空字符串
- if (words == null || words.Count() < 1)
- {
- return string.Empty;
- }
- words = words.Distinct();//有时候词有重复的,得自己处理一下
- return string.Join(",", words);//根据个人需求返回
- }
- #endregion
- #region 扩展相关
- /// <summary>
- /// 获取分词之后的字符串
- /// </summary>
- /// <param name="objStr"></param>
- /// <param name="type"></param>
- /// <returns></returns>
- public static string GetSplitWordStr(this string objStr, JiebaTypeEnum type = JiebaTypeEnum.Default)
- {
- var words = GetSplitWords(objStr, type);
- return JoinKeyWords(words);
- }
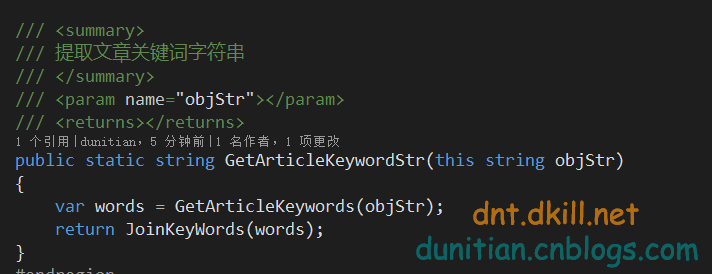
- /// <summary>
- /// 提取文章关键词字符串
- /// </summary>
- /// <param name="objStr"></param>
- /// <returns></returns>
- public static string GetArticleKeywordStr(this string objStr)
- {
- var words = GetArticleKeywords(objStr);
- return JoinKeyWords(words);
- }
- #endregion
- }
- }




还有耐心或者只看末尾的有福了~
web端的字典配置那是个烦啊,逆天把源码微调了下
使用方法和上面一样
web版演示:
结巴中文分词相关:
https://github.com/fxsjy/jieba
https://github.com/anderscui/jieba.NET
http://cppjieba-webdemo.herokuapp.com
中文分词之结巴分词~~~附使用场景+demo(net)的更多相关文章
- python中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- python 中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- python中文分词工具——结巴分词
传送门: http://www.iteye.com/news/26184-jieba
- 结巴分词 java 高性能实现,是 huaban jieba 速度的 2倍
Segment Segment 是基于结巴分词词库实现的更加灵活,高性能的 java 分词实现. 变更日志 创作目的 分词是做 NLP 相关工作,非常基础的一项功能. jieba-analysis 作 ...
- python 结巴分词简介以及操作
中文分词库:结巴分词 文档地址:https://github.com/fxsjy/jieba 代码对 Python 2/3 均兼容 全自动安装:easy_install jieba 或者 pip in ...
- ElasticSearch自定义分析器-集成结巴分词插件
关于结巴分词 ElasticSearch 插件: https://github.com/huaban/elasticsearch-analysis-jieba 该插件由huaban开发.支持Elast ...
- Simple: SQLite3 中文结巴分词插件
一年前开发 simple 分词器,实现了微信在两篇文章中描述的,基于 SQLite 支持中文和拼音的搜索方案.具体背景参见这篇文章.项目发布后受到了一些朋友的关注,后续也发布了一些改进,提升了项目易用 ...
- 北大开源全新中文分词工具包:准确率远超THULAC、结巴分词
最近,北大开源了一个中文分词工具包,它在多个分词数据集上都有非常高的分词准确率.其中广泛使用的结巴分词误差率高达 18.55% 和 20.42,而北大的 pkuseg 只有 3.25% 与 4.32% ...
- 中文分词接口api,采用结巴分词PHP版中文分词接口
中文分词,分词就是将连续的字序列按照一定的规范重新组合成词序列的过程.我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字.句和段能通过明显的分界符来简单划界,唯独词没有一个形式上 ...
随机推荐
- B树——算法导论(25)
B树 1. 简介 在之前我们学习了红黑树,今天再学习一种树--B树.它与红黑树有许多类似的地方,比如都是平衡搜索树,但它们在功能和结构上却有较大的差别. 从功能上看,B树是为磁盘或其他存储设备设计的, ...
- RecyclerView使用大全
RecylerView介绍 RecylerView是support-v7包中的新组件,是一个强大的滑动组件,与经典的ListView相比,同样拥有item回收复用的功能,这一点从它的名字recyler ...
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
- 使用CSS3实现一个3D相册
CSS3系列我已经写过两篇文章,感兴趣的同学可以先看一下CSS3初体验之奇技淫巧,CSS3 3D立方体效果-transform也不过如此 第一篇主要列出了一些常用或经典的CSS3技巧和方法:第二篇是一 ...
- category中重写方法?
问:可以在category中重写方法吗? 答:代码上可以实现 在category中重写方法,但在实际开发中,不建议这样做.如果确实需要重写原有方法也建议使用子类进行重写. category是为了更方便 ...
- 一起学微软Power BI系列-使用技巧(1)连接Oracle与Mysql数据库
说起Oracle数据库,以前没用过Oracle不知道,但是这1年用Oracle后,发现真的是想狂吐槽,特别是那个.NET驱动和链接字符串,特别奇葩.总归是和其他数据库不一样,标新立异,不知道为何.另外 ...
- [原] KVM 虚拟化原理探究(4)— 内存虚拟化
KVM 虚拟化原理探究(4)- 内存虚拟化 标签(空格分隔): KVM 内存虚拟化简介 前一章介绍了CPU虚拟化的内容,这一章介绍一下KVM的内存虚拟化原理.可以说内存是除了CPU外最重要的组件,Gu ...
- 手把手教你写一个RN小程序!
时间过得真快,眨眼已经快3年了! 1.我的第一个App 还记得我14年初写的第一个iOS小程序,当时是给别人写的一个单机的相册,也是我开发的第一个完整的app,虽然功能挺少,但是耐不住心中的激动啊,现 ...
- 嵌入式&iOS:回调函数(C)与block(OC)传 参/函数 对比
C的回调函数: callBack.h 1).声明一个doSomeThingCount函数,参数为一个(无返回值,1个int参数的)函数. void DSTCount(void(*CallBack)(i ...
- 【代码笔记】iOS-获得当前的月的天数
一,代码. #import "ViewController.h" @interface ViewController () @end @implementation ViewCon ...