sizeof学习理解
以下内容转自: http://www.cnblogs.com/ComputerG/archive/2012/02/02/2335611.html
sizeof()解析(原)
(一)基本概念
sizeof操作符以字节形式给出了其操作数的存储大小。操作数可以是一个表达式或括在括号内的类型名。操作数的存储大小由操作数的类型决定。
(二)使用方法
1、用于数据类型
sizeof使用形式:sizeof(type) ,如sizeof(int)
2、用于变量
sizeof使用形式:sizeof(var_name)或sizeof var_name
变量名可以不用括号括住。如sizeof (var_name),sizeof var_name等都是正确形式。带括号的用法更普遍,大多数程序员采用这种形式。
 注意:sizeof操作符不能用于函数类型,不完全类型或位字段。不完全类型指具有未知存储大小的数据类型,如未知存储大小的数组类型、未知内容的结构或联合类型、void类型等。
注意:sizeof操作符不能用于函数类型,不完全类型或位字段。不完全类型指具有未知存储大小的数据类型,如未知存储大小的数组类型、未知内容的结构或联合类型、void类型等。
如sizeof(max)若此时变量max定义为int max(),sizeof(char_v) 若此时char_v定义为char char_v [MAX]且MAX未知,sizeof(void)都不是正确形式。
(三)sizeof应用在结构上的情况
请看下面的结构:
struct MyStruct
{
double doub;
char ch;
int i;
};
对结构MyStruct采用sizeof会出现什么结果呢?sizeof(MyStruct)为多少呢?也许你会这样求:
sizeof(MyStruct)=sizeof(double)+sizeof(char)+sizeof(int)=13
以下是测试代码:
#include <iostream>
using namespace std;
struct MyStruct
{
double doub;
char ch;
int i;
};
int main()
{
MyStruct ms;
cout << sizeof(ms) << endl;
return 0;
}
测试结果:
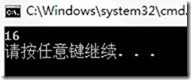
但是当在VC中测试上面结构的大小时,你会发现sizeof(ms)为16。 其实,这是VC对变量存储的一个特殊处理。为了提高CPU的存储速度,VC对一些变量的起始地址做了“对齐”处理。在默认情况下,VC规定各成员变量存放的起始地址相对于结构的起始地址的偏移量必须为该变量的类型所占用的字节数的倍数。
其实,这是VC对变量存储的一个特殊处理。为了提高CPU的存储速度,VC对一些变量的起始地址做了“对齐”处理。在默认情况下,VC规定各成员变量存放的起始地址相对于结构的起始地址的偏移量必须为该变量的类型所占用的字节数的倍数。
常用类型的对齐方式
| 类型 | 对齐方式(变量存放的起始地址相对于结构的起始地址的偏移量) |
| char | 偏移量必须为sizeof(char)即1的倍数 |
| int | 偏移量必须为sizeof(int)即4的倍数 |
| double | 偏移量必须为sizeof(double)即8的倍数 |
| short | 偏移量必须为sizeof(short)即2的倍数 |
| float | 偏移量必须为sizeof(float)即4的倍数 |
各成员变量在存放的时候根据在结构中出现的顺序依次申请空间,同时按照上面的对齐方式调整位置,空缺的字节VC会自动填充。同时VC为了确保结构的大小为结构的字节边界数(即该结构中占用最大空间的类型所占用的字节数)的倍数,所以在为最后一个成员变量申请空间后,还会根据需要自动填充空缺的字节。
struct MyStruct
{
double doub;
char ch;
int i;
};
为上面的结构分配空间的时候,VC根据成员变量出现的顺序和对齐方式,先为第一个成员doub分配空间,其起始地址跟结构的起始地址相同(刚好偏移量0刚好为sizeof(double)的倍数),该成员变量占用sizeof(double)=8个字节;接下来为第二个成员ch分配空间,这时下一个可以分配的地址对于结构的起始地址的偏移量为8,是sizeof(char)的倍数,所以把ch存放在偏移量为8的地方满足对齐方式,该成员变量占用sizeof(char)=1个字节;接下来为第三个成员i分配空间,这时下一个可以分配的地址对于结构的起始地址的偏移量为9,不是sizeof(int)=4的倍数,为了满足对齐方式对偏移量的约束问题,VC自动填充3个字节(这三个字节没有放什么东西),这时下一个可以分配的地址对于结构的起始地址的偏移量为12,刚好是sizeof(int)=4的倍数,所以把i存放在偏移量为12的地方,该成员变量占用sizeof(int)=4个字节;这时整个结构的成员变量已经都分配了空间,总的占用的空间大小为:8+1+3+4=16,刚好为结构的字节边界数(即结构中占用最大空间的类型所占用的字节数sizeof(double)=8)的倍数,所以没有空缺的字节需要填充。所以整个结构的大小为:sizeof(MyStruct)=8+1+3+4=16,其中有3个字节是VC自动填充的,没有放任何有意义的东西。
下面再举个例子,交换一下上面的MyStruct的成员变量的位置,使它变成下面的情况:
struct MyStruct
{
char ch;
double doub;
int i;
};
在VC环境下,可以得到sizeof(MyStruct)为24。结合上面提到的分配空间的一些原则,分析下VC怎么样为上面 的结构分配空间:
struct MyStruct
{
char ch; // 偏移量为0,满足对齐方式,ch占用1个字节;
double doub; //下一个可用的地址的偏移量为1,不是sizeof(double)=8
//的倍数,需要补足7个字节才能使偏移量变为8(满足对齐
//方式),因此VC自动填充7个字节,doub存放在偏移量为8
//的地址上,它占用8个字节。
int i; //下一个可用的地址的偏移量为16,是sizeof(int)=4的倍
//数,满足int的对齐方式,所以不需要VC自动填充,i存
//放在偏移量为16的地址上,它占用4个字节。
}; //所有成员变量都分配了空间,空间总的大小为1+7+8+4=20,不是结构
//的节边界数(即结构中占用最大空间的类型所占用的字节数sizeof
//(double)=8)的倍数,所以需要填充4个字节,以满足结构的大小为
//sizeof(double)=8的倍数。
所以该结构总的大小为:sizeof(MyStruct)为1+7+8+4+4=24。其中总的有7+4=11个字节是VC自动填充的,没有放任何有意义的东西。
VC对结构的存储的特殊处理确实提高CPU存储变量的速度,但是有时候也带来了一些麻烦,我们也屏蔽掉变量默认的对齐方式,自己可以设定变量的对齐方式。
 VC中提供了#pragma pack(n)来设定变量以n字节对齐方式。n字节对齐就是说变量存放的起始地址的偏移量有两种情况:第一,如果n大于等于该变量所占用的字节数,那么偏移量必须满足默认的对齐方式,第二,如果n小于该变量的类型所占用的字节数,那么偏移量为n的倍数,不用满足默认的对齐方式。结构的总大小也有个约束条件,分下面两种情况:如果n大于所有成员变量类型所占用的字节数,那么结构的总大小必须为占用空间最大的变量占用的空间数的倍数;否则必须为n的倍数。
VC中提供了#pragma pack(n)来设定变量以n字节对齐方式。n字节对齐就是说变量存放的起始地址的偏移量有两种情况:第一,如果n大于等于该变量所占用的字节数,那么偏移量必须满足默认的对齐方式,第二,如果n小于该变量的类型所占用的字节数,那么偏移量为n的倍数,不用满足默认的对齐方式。结构的总大小也有个约束条件,分下面两种情况:如果n大于所有成员变量类型所占用的字节数,那么结构的总大小必须为占用空间最大的变量占用的空间数的倍数;否则必须为n的倍数。
下面举例说明其用法:
#pragma pack(push) //保存对齐状态
#pragma pack(4) //设定为4字节对齐
struct MyStruct
{
char ch;
double doub;
int i;
};
#pragma pack(pop) //恢复对齐状态
测试结果:
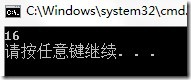
(四)sizeof用法总结
1. 参数为数据类型或者为一般变量。
例如sizeof(int),sizeof(long)等等。这种情况要注意的是不同系统系统或者不同编译器得到的结果可能是不同的。例如int类型在16位系统中占2个字节,在32位系统中占4个字节。
2. 参数为数组或指针。
下面举例说明.
int a[50]; //sizeof(a)=4*50=200; 求数组所占的空间大小
int *a = new int[50]; // sizeof(a)=4; a为一个指针,sizeof(a)是求指针的大小,在32位系统中,当然是占4个字节。
3. 参数为其他。
int func(char s[5])
{
return 1; //函数的参数在传递的时候系统处理为一个指针,所以sizeof(s)实际上为求指针的大小。
}
sizeof(func("1234")); //因为func的返回类型为int,所以相当于求sizeof(int),其值为4.
sizeof学习理解的更多相关文章
- 全面学习理解TLB(Translation Look-aside Buffer)地址变换高速缓存
全面学习理解TLB(Translation Look-aside Buffer)地址变换高速缓存 前言: 本文学习思路是:存在缘由 --> 存在好处 --> 定义性质 --> 具 ...
- MLT的学习理解
MLT的学习理解 MLT是一个开源的多媒体库,我们的音视频编辑工具,是使用它作为底层支持,某司的'快剪辑'pc版和安卓版,也是用的它. MLT简介 它的GitHub地址,这个库比较老了,现在只有一个作 ...
- 菜鸟之路——机器学习之SVM分类器学习理解以及Python实现
SVM分类器里面的东西好多呀,碾压前两个.怪不得称之为深度学习出现之前表现最好的算法. 今天学到的也应该只是冰山一角,懂了SVM的一些原理.还得继续深入学习理解呢. 一些关键词: 超平面(hyper ...
- batch normalization学习理解笔记
batch normalization学习理解笔记 最近在Andrew Ng课程中学到了Batch Normalization相关内容,通过查阅资料和原始paper,基本上弄懂了一些算法的细节部分,现 ...
- Source Xref 与 JavaDocs 学习理解
最近学习Mybatis的官方文档,看到了[项目文档]一节有很多内容没有见过,做个笔记,理解一下. 没找到java相关代码的解释,其实用下面这个php版本解释,也非常不错. What is SOURCE ...
- TLD网络资源汇总--学习理解之(四)
原文:http://blog.csdn.net/mysniper11/article/details/8726649 引文地址:http://www.cnblogs.com/lxy2017/p/392 ...
- TLD算法概述--学习理解之(一)
liuyihai@126.com http://www.cnblogs.com/liuyihai/ TLD(Tracking-Learning-Detection)是英国萨里大学的一个捷克籍博士生Zd ...
- face recognition[翻译][深度学习理解人脸]
本文译自<Deep learning for understanding faces: Machines may be just as good, or better, than humans& ...
- [深度学习]理解RNN, GRU, LSTM 网络
Recurrent Neural Networks(RNN) 人类并不是每时每刻都从一片空白的大脑开始他们的思考.在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义 ...
随机推荐
- hdu 1702 ACboy needs your help again!
题目连接 http://acm.hdu.edu.cn/showproblem.php?pid=1702 ACboy needs your help again! Description ACboy w ...
- Java求职面试准备之常见算法
最近在求职面试,整理一下常见面试算法: 对TestAlgorithms.java中方法的测试见JunitTestAlgorithms.java(引入了junit4) 1.TestAlgorithms. ...
- JavaScript高级程序设计之基本包装类型
为便于操作基本类型值,ECMAScript提供了3个特殊的引用类型:Boolean, Number 和 String // 字符串怎么会有方法呢 var str1 = "some text& ...
- python 删除list中重复元素
list = [1,1,3,4,6,3,7] 1. for s in list: if list.count(s) >1: list.remove(s) 2. list2=[] for s in ...
- Objective-C 一些概念
Automatic Reference Counting (ARC)
- [转]每天一个linux命令目录
[转]每天一个linux命令目录 http://www.cnblogs.com/peida/archive/2012/12/05/2803591.html 开始详细系统的学习linux常用命令,坚持每 ...
- Android实现SQLite数据库联系人列表
Android实现SQLite数据库联系人列表 开发工具:Andorid Studio 1.3 运行环境:Android 4.4 KitKat 工程内容 实现一个通讯录查看程序: 要求使用SQLite ...
- 随堂作业——到底有几个“1”(C++)
一.设计思路 在课堂上讨论的时候,老师提出的思路是利用之前的结果计算出比它更大的数字的“1”.但是我不是这么想的,我是把输入的正整数每位上的数都分解出来计算.如abc,就先算c,再加上b,最后再加上a ...
- zabbix语言设置
1.怎样支持中文: https://www.zabbix.org/wiki/How_to/install_locale 官方解决方法 实际操作中,进入/var/lib/locales/supporte ...
- LNMP系列网站零基础开发记录(三)
[目录] 扯淡吹逼之开发前奏 Django 开发环境搭建及配置 web 页面开发 Django app开发 Django 站点管理 Python 简易爬虫开发 Nginx&uWSGI 服务器配 ...