CUDA 标准编程模式
前言
本文将介绍 CUDA 编程的基本模式,所有 CUDA 程序都基于此模式编写,即使是调用库,库的底层也是这个模式实现的。
模式描述
1. 定义需要在 device 端执行的核函数。( 函数声明前加 _golbal_ 关键字 )
2. 在显存中为待运算的数据以及需要存放结果的变量开辟显存空间。( cudaMalloc 函数实现 )
3. 将待运算的数据传输进显存。( cudaMemcpy,cublasSetVector 等函数实现 )
4. 调用 device 端函数,同时要将需要为 device 端函数创建的块数线程数等参数传递进 <<<>>>。( 注: <<<>>>下方编译器可能显示语法错误,不用管 )
5. 从显存中获取结果变量。( cudaMemcpy,cublasGetVector 等函数实现 )
6. 释放申请的显存空间。( cudaFree 实现 )
PS:每个 device 端函数在被调用时都能获取到调用它的具体块号,线程号,从而实现并行( 获取方法请参考下面的编程规范说明以及代码示例 )。
编程规范说明
在 CUDA 标准编程模式中,增加了一些编程规范,在这里简要说明:
函数声明关键字:
1. __device__
表明此函数只能在 GPU 中被调用,在 GPU 中执行。这类函数只能被 __global__ 类型函数或 __device__ 类型函数调用。
2. __global__
表明此函数在 CPU 上调用,在 GPU 中执行。这也是以后会常提到的 "内核函数",有时为了便于理解也称 "device" 端函数。
3. __host__
表明此函数在 CPU 上调用和执行,这也是默认情况。
内核函数配置运算符 <<<>>> - 这个运算符在调用内核函数的时候使用,一般情况下传递进三个参数:
1. 块数
2. 线程数
3. 共享内存大小 (此参数默认为0 )
内核函数中的几个系统变量 - 这几个变量可以在内核函数中使用,从而控制块与线程的工作:
1. gridDim:块数
2. blockDim:块中线程数
3. blockIdx:块编号 (0 - gridDim-1)
4. threadIdx:线程编号 (0 - blockDim-1)
知道这些已经足够编写 CUDA 程序了,更多的编程说明将在以后的文章中介绍。
代码示例
该程序采用 CUDA 并行化思想来对数组进行求和 (代码下方如果出现红色波浪线无视之):
- // 相关 CUDA 库
- #include "cuda_runtime.h"
- #include "cuda.h"
- #include "device_launch_parameters.h"
- #include <iostream>
- #include <cstdlib>
- using namespace std;
- const int N = ;
- // 块数
- const int BLOCK_data = ;
- // 各块中的线程数
- const int THREAD_data = ;
- // CUDA初始化函数
- bool InitCUDA()
- {
- int deviceCount;
- // 获取显示设备数
- cudaGetDeviceCount (&deviceCount);
- if (deviceCount == )
- {
- cout << "找不到设备" << endl;
- return EXIT_FAILURE;
- }
- int i;
- for (i=; i<deviceCount; i++)
- {
- cudaDeviceProp prop;
- if (cudaGetDeviceProperties(&prop,i)==cudaSuccess) // 获取设备属性
- {
- if (prop.major>=) //cuda计算能力
- {
- break;
- }
- }
- }
- if (i==deviceCount)
- {
- cout << "找不到支持 CUDA 计算的设备" << endl;
- return EXIT_FAILURE;
- }
- cudaSetDevice(i); // 选定使用的显示设备
- return EXIT_SUCCESS;
- }
- // 此函数在主机端调用,设备端执行。
- __global__
- static void Sum (int *data,int *result)
- {
- // 取得线程号
- const int tid = threadIdx.x;
- // 获得块号
- const int bid = blockIdx.x;
- int sum = ;
- // 有点像网格计算的思路
- for (int i=bid*THREAD_data+tid; i<N; i+=BLOCK_data*THREAD_data)
- {
- sum += data[i];
- }
- // result 数组存放各个线程的计算结果
- result[bid*THREAD_data+tid] = sum;
- }
- int main ()
- {
- // 初始化 CUDA 编译环境
- if (InitCUDA()) {
- return EXIT_FAILURE;
- }
- cout << "成功建立 CUDA 计算环境" << endl << endl;
- // 建立,初始化,打印测试数组
- int *data = new int [N];
- cout << "测试矩阵: " << endl;
- for (int i=; i<N; i++)
- {
- data[i] = rand()%;
- cout << data[i] << " ";
- if ((i+)% == ) cout << endl;
- }
- cout << endl;
- int *gpudata, *result;
- // 在显存中为计算对象开辟空间
- cudaMalloc ((void**)&gpudata, sizeof(int)*N);
- // 在显存中为结果对象开辟空间
- cudaMalloc ((void**)&result, sizeof(int)*BLOCK_data*THREAD_data);
- // 将数组数据传输进显存
- cudaMemcpy (gpudata, data, sizeof(int)*N, cudaMemcpyHostToDevice);
- // 调用 kernel 函数 - 此函数可以根据显存地址以及自身的块号,线程号处理数据。
- Sum<<<BLOCK_data,THREAD_data,>>> (gpudata,result);
- // 在内存中为计算对象开辟空间
- int *sumArray = new int[THREAD_data*BLOCK_data];
- // 从显存获取处理的结果
- cudaMemcpy (sumArray, result, sizeof(int)*THREAD_data*BLOCK_data, cudaMemcpyDeviceToHost);
- // 释放显存
- cudaFree (gpudata);
- cudaFree (result);
- // 计算 GPU 每个线程计算出来和的总和
- int final_sum=;
- for (int i=; i<THREAD_data*BLOCK_data; i++)
- {
- final_sum += sumArray[i];
- }
- cout << "GPU 求和结果为: " << final_sum << endl;
- // 使用 CPU 对矩阵进行求和并将结果对照
- final_sum = ;
- for (int i=; i<N; i++)
- {
- final_sum += data[i];
- }
- cout << "CPU 求和结果为: " << final_sum << endl;
- getchar();
- return ;
- }
运行测试
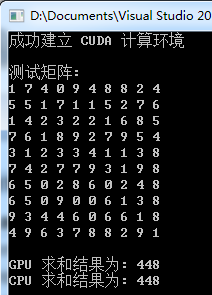
PS:矩阵元素是随机生成的
小结
1. 掌握本节知识的关键除了要掌握各个API,还要深刻理解内核函数中的块及线程变量的控制,或者说施展 :)
2. 一定要明确传递进 API 的是参数本身,还是参数的地址,这很关键。
CUDA 标准编程模式的更多相关文章
- 第三篇:CUDA 标准编程模式
前言 本文将介绍 CUDA 编程的基本模式,所有 CUDA 程序都基于此模式编写,即使是调用库,库的底层也是这个模式实现的. 模式描述 1. 定义需要在 device 端执行的核函数.( 函数声明前加 ...
- CUDA 并行编程简介
前言 并行就是让计算中相同或不同阶段的各个处理同时进行.目前有很多种实现并行的手段,如多核处理器,分布式系统等.本专题的文章将主要介绍使用 GPU 实现并行的方法.参考本专题文章前请务必搭建好 CUD ...
- 第二篇:CUDA 并行编程简介
前言 并行就是让计算中相同或不同阶段的各个处理同时进行. 目前有很多种实现并行的手段,如多核处理器,分布式系统等,而本专题的文章将主要介绍使用 GPU 实现并行的方法. 参考本专题文章前请务必搭建好 ...
- C#编程模式之扩展命令
C#编程模式之扩展命令 前言 根据上一篇的命令模式和在工作中遇到的一些实际情况,有了本篇文章,时时都是学习的一个过程,会在这个过程中发现许多好的模式或者是一种开发方式,今天写出来的就是我工作中常用到的 ...
- Scalaz(43)- 总结 :FP就是实用的编程模式
完成了对Free Monad这部分内容的学习了解后,心头豁然开朗,存在心里对FP的疑虑也一扫而光.之前也抱着跟大多数人一样的主观概念,认为FP只适合学术性探讨.缺乏实际应用.运行效率低,很难发展成现实 ...
- Scalaz(10)- Monad:就是一种函数式编程模式-a design pattern
Monad typeclass不是一种类型,而是一种程序设计模式(design pattern),是泛函编程中最重要的编程概念,因而很多行内人把FP又称为Monadic Programming.这其中 ...
- 泛函编程(27)-泛函编程模式-Monad Transformer
经过了一段时间的学习,我们了解了一系列泛函数据类型.我们知道,在所有编程语言中,数据类型是支持软件编程的基础.同样,泛函数据类型Foldable,Monoid,Functor,Applicative, ...
- MXNet设计笔记之:深度学习的编程模式比较
市面上流行着各式各样的深度学习库,它们风格各异.那么这些函数库的风格在系统优化和用户体验方面又有哪些优势和缺陷呢?本文旨在于比较它们在编程模式方面的差异,讨论这些模式的基本优劣势,以及我们从中可以学到 ...
- C#的内存管理原理解析+标准Dispose模式的实现
本文内容是本人参考多本经典C#书籍和一些前辈的博文做的总结 尽管.NET运行库负责处理大部分内存管理工作,但C#程序员仍然必须理解内存管理的工作原理,了解如何高效地处理非托管的资源,才能在非常注重性能 ...
随机推荐
- MyEclipse8.6 破解以及注册码
建立JAVA工程文件.将以下Java代码拷贝至类中并执行即可. 注册码: register name: bobo9360013 Serial:oLR8ZC-855550-6065705698041 ...
- oracle查询语句大全
1.查处oracle数据库的字符编码格式 select * from v$nls_parameters t where t.PARAMETER='NLS_CHARACTERSET'; 如果查出的是ZH ...
- 可伸缩的textview。
在一些应用中,比如腾讯的应用市场APP应用宝,关于某款应用的介绍文字,如果介绍文字过长,那么不是全部展现出来,而是显示三四行的开始部分(摘要),预知全部的内容,用户点击展开按钮即可查阅全部内容. 这样 ...
- .NET C#使用微信公众号登录网站
适用于:本文适用于有一定微信开发基础的用户 引言:花了300大洋申请了微信公众平台后,发现不能使用微信公众号登录网站(非微信打开)获得微信帐号.仔细研究后才发现还要再花300大洋申请微信开放平台才能接 ...
- 一天完成把PC网站改为自适应!原来这么简单!
http://www.webkaka.com/blog/archives/how-to-modify-a-web-page-to-be-responsive.html 一天完成把PC网站改为自适应!原 ...
- CSS3卷角
众所周知,border-radius 属性可以用来设置圆角,但很少人知道它还可以做很多不规则的犄角.卷角(rounded corners) 工作原理: 一.独立属性:border-bottom-lef ...
- a标签的css样式四个状态的设计
表示所有状态下的连接 如 a{color:red} ① a:link:未访问链接 ,如 a:link {color:blue} ② a:visited:已访问链接 ,如 a:visited{color ...
- Javascript——Math对象
Math 对象是一个固有的对象,无需创建它,直接把 Math 作为对象使用就可以调用其所有属性和方法.这是它与Date,String对象的区别 Math 对象属性 Math 对象方法
- tic/toc/cputime测试时间
cputime测试代码运行时间可能不及tic/toc准确是众所周知的事情.本文并非旧话重提,而是期望起到抛砖引玉的效果,从而找到cputime与tic/toc内在的区别.望不吝赐教! 用tic/toc ...
- ASP.NET 分页控件
using System; using System.ComponentModel; using System.Web; using System.Web.UI; using System.Web.U ...