python正则表达式(四)
re模块的高级用法
search
需求:匹配出文章阅读的次数
#coding=utf-8
import re ret = re.search(r"\d+", "阅读次数为 9999")
ret.group()

findall
需求:统计出python、c、c++相应文章阅读的次数
#coding=utf-8
import re ret = re.findall(r"\d+", "python = 9999, c = 7890, c++ = 12345")
print ret

sub 将匹配到的数据进行替换
需求:将匹配到的阅读次数加1
方法1:
#coding=utf-8
import re ret = re.sub(r"\d+", '', "python = 997")
print ret

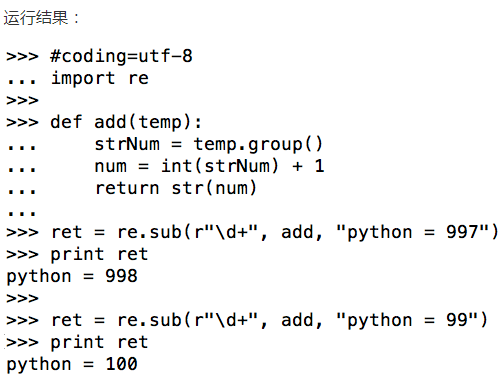
方法2:
#coding=utf-8
import re def add(temp):
strNum = temp.group()
num = int(strNum) + 1
return str(num) ret = re.sub(r"\d+", add, "python = 997")
print ret ret = re.sub(r"\d+", add, "python = 99")
print ret
python贪婪和非贪婪
Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;
非贪婪则相反,总是尝试匹配尽可能少的字符。
在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
>>> s="This is a number 234-235-22-423"
>>> r=re.match(".+(\d+-\d+-\d+-\d+)",s)
>>> r.group(1)
'4-235-22-423'
>>> r=re.match(".+?(\d+-\d+-\d+-\d+)",s)
>>> r.group(1)
'234-235-22-423'
>>>
正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串,在我们上面的例子里面,“.+”会从字符串的启始处抓取满足模式的最长字符,其中包括我们想得到的第一个整型字段的中的大部分,“\d+”只需一位字符就可以匹配,所以它匹配了数字“4”,而“.+”则匹配了从字符串起始到这个第一位数字4之前的所有字符。
解决方式:非贪婪操作符“?”,这个操作符可以用在"*","+","?"的后面,要求正则匹配的越少越好。
>>> re.match(r"aa(\d+)","aa2343ddd").group(1)
''
>>> re.match(r"aa(\d+?)","aa2343ddd").group(1)
''
>>> re.match(r"aa(\d+)ddd","aa2343ddd").group(1)
''
>>> re.match(r"aa(\d+?)ddd","aa2343ddd").group(1)
''
>>>
python正则表达式(四)的更多相关文章
- Python 第四篇:生成器、迭代器、装饰器、递归函数与正则表达式
一:生成器:Generator,可以理解为是一种一个函数产生一个迭代器,而迭代器里面的数据是可以通过for循环获取的,那么这个函数就是一个生成器,即生成器是有函数生成的,创建生成器使用()表示,比如g ...
- Python正则表达式初识(四)
今天继续给大家分享Python正则表达式基础知识,主要给大家介绍一下特殊字符“{}”的用法,具体的教程如下. 特殊字符“{}”实质上也是一个限定词的用法,其限定前面字符所出现的次数,其常用的模式有三种 ...
- Python正则表达式详解
我用双手成就你的梦想 python正则表达式 ^ 匹配开始 $ 匹配行尾 . 匹配出换行符以外的任何单个字符,使用-m选项允许其匹配换行符也是如此 [...] 匹配括号内任何当个字符(也有或的意思) ...
- 比较详细Python正则表达式操作指南(re使用)
比较详细Python正则表达式操作指南(re使用) Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式.Python 1.5之前版本则是通过 regex 模块提供 E ...
- python正则表达式 小例几则
会用到的语法 正则字符 释义 举例 + 前面元素至少出现一次 ab+:ab.abbbb 等 * 前面元素出现0次或多次 ab*:a.ab.abb 等 ? 匹配前面的一次或0次 Ab?: A.Ab 等 ...
- Python天天美味(15) - Python正则表达式操作指南(re使用)(转)
http://www.cnblogs.com/coderzh/archive/2008/05/06/1185755.html 简介 Python 自1.5版本起增加了re 模块,它提供 Perl 风格 ...
- Python正则表达式Regular Expression基本用法
资料来源:http://blog.csdn.net/whycadi/article/details/2011046 直接从网上资料转载过来,作为自己的参考.这个写的很清楚.先拿来看看. 1.正则表 ...
- python 正则表达式汇总
一. 正则表达式基础 1.1.概念介绍 正则表达式是用于处理字符串的强大工具,它并不是Python的一部分. 其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同. 它拥 ...
- Python第四天 流程控制 if else条件判断 for循环 while循环
Python第四天 流程控制 if else条件判断 for循环 while循环 目录 Pycharm使用技巧(转载) Python第一天 安装 shell 文件 Python第二天 ...
- 【repost】Python正则表达式
星光海豚 python正则表达式详解 正则表达式是一个很强大的字符串处理工具,几乎任何关于字符串的操作都可以使用正则表达式来完成,作为一个爬虫工作者,每天和字符串打交道,正则表达式更是不可或缺的技 ...
随机推荐
- 20165206 2017-2018-2 《Java程序设计》第8周学习总结
20165206 2017-2018-2 <Java程序设计>第8周学习总结 教材学习内容总结 进程:进程是程序的一次动态执行过程,对应了从代码加载.执行至执行完毕的一个完整过程,这个过程 ...
- Docker建立自己的私有仓库
拉去仓库镜像 docker pull registry:latest 创建存储账户的文件夹路径 mkdir -p /{dir}/auth/ 创建用户密码信息文件 docker run --entryp ...
- [转] js前端解决跨域问题的8种方案(最新最全)
1.同源策略如下: URL 说明 是否允许通信 http://www.a.com/a.jshttp://www.a.com/b.js 同一域名下 允许 http://www.a.com/lab/a.j ...
- [转] jQuery的deferred对象详解
jQuery的开发速度很快,几乎每半年一个大版本,每两个月一个小版本. 每个版本都会引入一些新功能.今天我想介绍的,就是从jQuery 1.5.0版本开始引入的一个新功能----deferred对象. ...
- IIS异常
http 错误 500.19 - internal server error 今天发布wcf到本地的IIS上,访问时出现了500.19错误.有效解决办法:是因为IIS没有安装完全,把能勾选的全部勾选上 ...
- Ncurses-窗口
前面介绍过标准屏幕 stdscr, stdscr 只是 WINDOW 结构的一个特例. 我们可以使用函数 newwin 和 delwin 来创建和销毁窗口 WINDOW *newwin(int num ...
- 【BZOJ4715】囚人的旋律
题解: 思考了很久这个图的特点没有发现 看了题解瞬间醒悟原来要在序列上做 还原出这张图显然是O(N^2)可以做的 然后其实就比较简单了 首先为了满足独立集,我们需要保证所取元素递增 为了满足覆盖集,我 ...
- JAVA中值类型和引用类型的不同(面试常考)
转载:https://www.cnblogs.com/1ming/p/5227944.html 1. JAVA中值类型和引用类型的不同? [定义] 引用类型表示你操作的数据是同一个,也就是说当你传一个 ...
- P1605 迷宫 dfs回溯法
题目背景 迷宫 [问题描述] 给定一个N*M方格的迷宫,迷宫里有T处障碍,障碍处不可通过.给定起点坐标和 终点坐标,问: 每个方格最多经过1次,有多少种从起点坐标到终点坐标的方案.在迷宫 中移动有上下 ...
- day14,函数的使用方法:生成器表达式,生成器函数
生成器表达式: #列表推导式 # y = [1,2,3,4,5,6,7,8] # x = [1,4,9,16,25,36,49,64] # x = [] # for i in y: # x.appen ...