Word2vec的Skip-Gram 系列1
转自雷锋网的一篇很棒的文章,写的通俗易懂。自己消化学习了。原文地址是
https://www.leiphone.com/news/201706/PamWKpfRFEI42McI.html
这次的分享主要是对Word2Vec模型的两篇英文文档的翻译、理解和整合,这两篇英文文档都是介绍Word2Vec中的Skip-Gram模型。下一篇专栏文章将会用TensorFlow实现基础版Word2Vec的skip-gram模型,所以本篇文章先做一个理论铺垫。
原文英文文档请参考链接:
- Word2Vec Tutorial - The Skip-Gram Model
- Word2Vec (Part 1): NLP With Deep Learning with Tensorflow (Skip-gram)
什么是Word2Vec和Embeddings?
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
我们从直观角度上来理解一下,cat这个单词和kitten属于语义上很相近的词,而dog和kitten则不是那么相近,iphone这个单词和kitten的语义就差的更远了。通过对词汇表中单词进行这种数值表示方式的学习(也就是将单词转换为词向量),能够让我们基于这样的数值进行向量化的操作从而得到一些有趣的结论。比如说,如果我们对词向量kitten、cat以及dog执行这样的操作:kitten - cat + dog,那么最终得到的嵌入向量(embedded vector)将与puppy这个词向量十分相近。
模型
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。本篇文章仅讲解Skip-Gram模型。
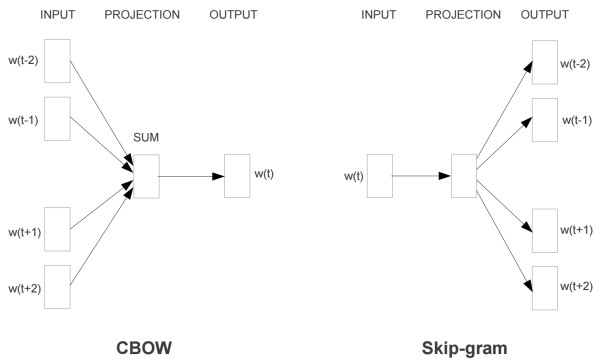
Skip-Gram模型的基础形式非常简单,为了更清楚地解释模型,我们先从最一般的基础模型来看Word2Vec(下文中所有的Word2Vec都是指Skip-Gram模型)。
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵——后面我们将会看到这些权重在Word2Vec中实际上就是我们试图去学习的“word vectors”。基于训练数据建模的过程,我们给它一个名字叫“Fake Task”,意味着建模并不是我们最终的目的。
上面提到的这种方法实际上会在无监督特征学习(unsupervised feature learning)中见到,最常见的就是自编码器(auto-encoder):通过在隐层将输入进行编码压缩,继而在输出层将数据解码恢复初始状态,训练完成后,我们会将输出层“砍掉”,仅保留隐层。
The Fake Task
我们在上面提到,训练模型的真正目的是获得模型基于训练数据学得的隐层权重。为了得到这些权重,我们首先要构建一个完整的神经网络作为我们的“Fake Task”,后面再返回来看通过“Fake Task”我们如何间接地得到这些词向量。
接下来我们来看看如何训练我们的神经网络。假如我们有一个句子“The dog barked at the mailman”。
首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;
有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是['The', 'dog','barked', 'at']。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 ('dog', 'barked'),('dog', 'the')。
神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词是output word的可能性。这句话有点绕,我们来看个栗子。第二步中我们在设置skip_window和num_skips=2的情况下获得了两组训练数据。假如我们先拿一组数据 ('dog', 'barked') 来训练神经网络,那么模型通过学习这个训练样本,会告诉我们词汇表中每个单词是“barked”的概率大小。
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。举个栗子,如果我们向神经网络模型中输入一个单词“Soviet“,那么最终模型的输出概率中,像“Union”, ”Russia“这种相关词的概率将远高于像”watermelon“,”kangaroo“非相关词的概率。因为”Union“,”Russia“在文本中更大可能在”Soviet“的窗口中出现。我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。下面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。

我们的模型将会从每对单词出现的次数中习得统计结果。例如,我们的神经网络可能会得到更多类似(“Soviet“,”Union“)这样的训练样本对,而对于(”Soviet“,”Sasquatch“)这样的组合却看到的很少。因此,当我们的模型完成训练后,给定一个单词”Soviet“作为输入,输出的结果中”Union“或者”Russia“要比”Sasquatch“被赋予更高的概率。
模型细节
我们如何来表示这些单词呢?首先,我们都知道神经网络只能接受数值输入,我们不可能把一个单词字符串作为输入,因此我们得想个办法来表示这些单词。最常用的办法就是基于训练文档来构建我们自己的词汇表(vocabulary)再对单词进行one-hot编码。
假设从我们的训练文档中抽取出10000个唯一不重复的单词组成词汇表。我们对这10000个单词进行one-hot编码,得到的每个单词都是一个10000维的向量,向量每个维度的值只有0或者1,假如单词ants在词汇表中的出现位置为第3个,那么ants的向量就是一个第三维度取值为1,其他维都为0的10000维的向量(ants=[0, 0, 1, 0, ..., 0])。
还是上面的例子,“The dog barked at the mailman”,那么我们基于这个句子,可以构建一个大小为5的词汇表(忽略大小写和标点符号):("the", "dog", "barked", "at", "mailman"),我们对这个词汇表的单词进行编号0-4。那么”dog“就可以被表示为一个5维向量[0, 1, 0, 0, 0]。
模型的输入如果为一个10000维的向量,那么输出也是一个10000维度(词汇表的大小)的向量,它包含了10000个概率,每一个概率代表着当前词是输入样本中output word的概率大小。
下图是我们神经网络的结构:
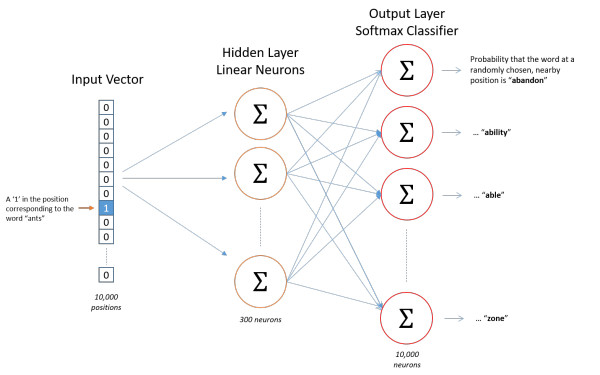
隐层没有使用任何激活函数,但是输出层使用了sotfmax。
我们基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对,input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。
隐层
说完单词的编码和训练样本的选取,我们来看下我们的隐层。如果我们现在想用300个特征来表示一个单词(即每个词可以被表示为300维的向量)。那么隐层的权重矩阵应该为10000行,300列(隐层有300个结点)。
Google在最新发布的基于Google news数据集训练的模型中使用的就是300个特征的词向量。词向量的维度是一个可以调节的超参数(在Python的gensim包中封装的Word2Vec接口默认的词向量大小为100, window_size为5)。
看下面的图片,左右两张图分别从不同角度代表了输入层-隐层的权重矩阵。左图中每一列代表一个10000维的词向量和隐层单个神经元连接的权重向量。从右边的图来看,每一行实际上代表了每个单词的词向量。

所以我们最终的目标就是学习这个隐层的权重矩阵。
我们现在回来接着通过模型的定义来训练我们的这个模型。
上面我们提到,input word和output word都会被我们进行one-hot编码。仔细想一下,我们的输入被one-hot编码以后大多数维度上都是0(实际上仅有一个位置为1),所以这个向量相当稀疏,那么会造成什么结果呢。如果我们将一个1 x 10000的向量和10000 x 300的矩阵相乘,它会消耗相当大的计算资源,为了高效计算,它仅仅会选择矩阵中对应的向量中维度值为1的索引行(这句话很绕),看图就明白。

我们来看一下上图中的矩阵运算,左边分别是1 x 5和5 x 3的矩阵,结果应该是1 x 3的矩阵,按照矩阵乘法的规则,结果的第一行第一列元素为0 x 17 + 0 x 23 + 0 x 4 + 1 x 10 + 0 x 11 = 10,同理可得其余两个元素为12,19。如果10000个维度的矩阵采用这样的计算方式是十分低效的。
为了有效地进行计算,这种稀疏状态下不会进行矩阵乘法计算,可以看到矩阵的计算的结果实际上是矩阵对应的向量中值为1的索引,上面的例子中,左边向量中取值为1的对应维度为3(下标从0开始),那么计算结果就是矩阵的第3行(下标从0开始)—— [10, 12, 19],这样模型中的隐层权重矩阵便成了一个”查找表“(lookup table),进行矩阵计算时,直接去查输入向量中取值为1的维度下对应的那些权重值。隐层的输出就是每个输入单词的“嵌入词向量”。
输出层
经过神经网络隐层的计算,ants这个词会从一个1 x 10000的向量变成1 x 300的向量,再被输入到输出层。输出层是一个softmax回归分类器,它的每个结点将会输出一个0-1之间的值(概率),这些所有输出层神经元结点的概率之和为1。
下面是一个例子,训练样本为 (input word: “ants”, output word: “car”) 的计算示意图。

直觉上的理解
下面我们将通过直觉来进行一些思考。
如果两个不同的单词有着非常相似的“上下文”(也就是窗口单词很相似,比如“Kitty climbed the tree”和“Cat climbed the tree”),那么通过我们的模型训练,这两个单词的嵌入向量将非常相似。
那么两个单词拥有相似的“上下文”到底是什么含义呢?比如对于同义词“intelligent”和“smart”,我们觉得这两个单词应该拥有相同的“上下文”。而例如”engine“和”transmission“这样相关的词语,可能也拥有着相似的上下文。
实际上,这种方法实际上也可以帮助你进行词干化(stemming),例如,神经网络对”ant“和”ants”两个单词会习得相似的词向量。
词干化(stemming)就是去除词缀得到词根的过程。
Word2vec的Skip-Gram 系列1的更多相关文章
- 利用Tensorflow进行自然语言处理(NLP)系列之二高级Word2Vec
本篇也同步笔者另一博客上(https://blog.csdn.net/qq_37608890/article/details/81530542) 一.概述 在上一篇中,我们介绍了Word2Vec即词向 ...
- Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
Paddle Graph Learning (PGL)图学习之图游走类模型[系列四] 更多详情参考:Paddle Graph Learning 图学习之图游走类模型[系列四] https://aist ...
- Tensorflow 的Word2vec demo解析
简单demo的代码路径在tensorflow\tensorflow\g3doc\tutorials\word2vec\word2vec_basic.py Sikp gram方式的model思路 htt ...
- Word2Vec总结
摘要: 1.算法概述 2.算法要点与推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合 内容: 1.算法概述 Word2Vec是一个可以将语言中的字词转换为向量表达(Vecto ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- Word2vec 理解
1.有DNN做的word2vec,取隐藏层到softmax层的权重为词向量,softmax层的叶子节点数为词汇表大小 2-3的最开始的词向量是随机初始化的 2.哈夫曼树:左边走 sigmoid(当前节 ...
- word2vec原理
最原始的是NNLM,然后对其改进,有了后面的层次softmax和skip gram 层次softmax:去掉了隐藏层,后面加了huffuman树,concat的映射层也变成了sum skip gram ...
- word2vec学习 spark版
参考资料: http://ir.dlut.edu.cn/NewsShow.aspx?ID=291 http://www.douban.com/note/298095260/ http://machin ...
- word2vec的Java源码【转】
一.核心代码 word2vec.java package com.ansj.vec; import java.io.*; import java.lang.reflect.Array; import ...
- word2vec原理总结
一篇很好的入门博客,http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/ 他的翻译,https://www. ...
随机推荐
- exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
1.虽然,不是大错,还说要贴一下,由于我运行run-example streaming.NetworkWordCount localhost 9999的测试案例,出现的错误,第一感觉就是Spark没有 ...
- vue生命周期探究(一)
前言 在使用vue开发的过程中,我们经常会接触到生命周期的问题.那么你知道,一个标准的工程项目中,会有多少个生命周期勾子吗?让我们来一起来盘点一下: 根组件实例:8个 (beforeCreate.cr ...
- (4).NET CORE微服务 Micro-Service ---- Consul服务发现和消费
上一章说了 Consul服务注册 现在我要连接上Consul里面的服务 请求它们的API接口 应该怎么做呢? 1.找Consul要一台你需要的服务器 1.1 获取Consul下的所有注册的服务 u ...
- Spring MVC 注解
概述 Spring MVC是一个采用依赖注入的思想编写.对象的依赖注入Bean的方式可以通过Spring XML里面配置,配置之后的Bean使用时候,无需使用New关键字建立对象.但是如果所有的B ...
- 移动端根据不同DPR加载大小不同的图片
1.首先创建mixin.styl文件代码如下: bg-image($url) // 创建bg-image($url)函数 background-image: url($url + "@2x. ...
- selenium WebDriver 对浏览器标签页的切换
关于selenium WebDriver 对浏览器标签页的切换,现在的市面上最新的浏览器,当点击一个链接打开一个新的页面都是在浏览器中打开一个标签页,而selenium只能对窗口进行切换的方法,只能操 ...
- B-number 数位dp
求有 13且能被13整除的个数 显然已目前的四个状态无法对问题进行完全解答了 关于能否被13整除 有必要加一个mod状态 当pre为2的时候说明已经存在过13了(直接继承即可) 当pre为1说 ...
- Codeforces Gym 101291C【优先队列】
<题目链接> 题目大意: 就是一道纯模拟题,具体模拟过程见代码. 解题分析:要掌握不同优先级的优先队列的设置.下面是对优先队列的使用操作详解: priority_queue<int& ...
- python爬取今日头条关键字图集
1.访问搜索图集结果,获得json如下(右图为data的一条的详细内容).页面以Ajax呈现,每次请求20个图集,其中 title --- 图集名字 artical_url --- 图集的地址 cou ...
- Linux 中 Windows 中文乱码
Linux 下 Windows 源代码中文乱码 由于 windows 和 linux 对文本的编码方式不同,所以经常会有 windows 中生成的文本在 linux 中打开乱码的情况. 比如: 我面临 ...