Hadoop生态集群MapReduce详解
一、概述
MapReduce是一种编程模型,这点很重要,仅仅是一种编程的模型,而不是具体的软件。在hadoop中,HDFS是分布式的文件存储系统,而MapReduce是一个分布式的计算框架。用于大规模数据集(大于1TB)的并行运算。 说白了就是程序运行时将数据操作分为好几部,主要是:拆分->排序->组合的过程。
二、原理和工作流程
2.1原理
一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,Map/Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。一般将计算节点称为nodemanager。
Map/Reduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
2.2流程
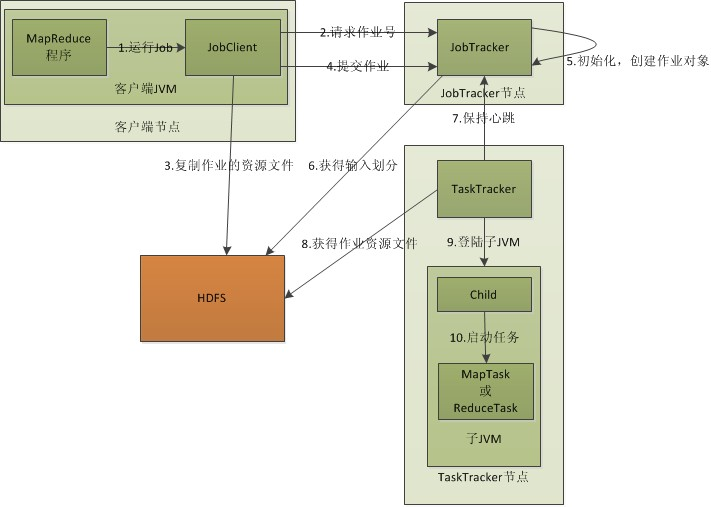
通过上面的流程图,在这对着个图的每一个程序进行一一的解读:
JobClient:
配置参数Configuration,打包成.jar文件存储在HDFS上,然后将文件路径提交给JobTracker的master服务,然后由master创建task将它们分发到各个TaskTracker服务中去执行。
JobTracker:
这是一个master服务,程序启动后,JobTracker负责资源监控和作业调度。JobTracker监控所有的TaskTracker和job的健康状况,一旦发生失败,即将之转移到其他节点上,同时JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop 中,任务调度器是一个可插拔的模块,用户可以根据自己的需要设计相应的调度器。
TaskTracker:
运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信接受作业,并负责直接执行每个任务。TaskTracker 会周期性地通过Heartbeat 将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。TaskTracker 使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop 调度器的作用就是将各个TaskTracker 上的空闲slot 分配给Task 使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用。TaskTracker 通过slot 数目(可配置参数)限定Task 的并发度。
Task分为Map Task和Reduce Task两种,均由TaskTracker启动。HDFS以block块存储数据,mapreduce处理的最小数据单位为split。split如何划分又用户自由设置。
流程解释:
第一步:编写好MapReduce程序后打包,运行。
第二步:程序执行成功。JobClient会根据配置文件信息向JobTracker申请可用的job(这里指的可用job是相应数量的maptask的工作进程)。JobTracker返回一个可用的JobID给JobClient。
第三步:根据得到的JobID, JobClient会把所需要的资源复制一份到HDFS上,这些资源包括MapReduce程序打包的JAR文件,配置文件和客户端计算所得的输入划分信息。JobTracker专门为该作业创建的文件夹中,文件夹名为该作业的JobID,JAR文件默认
会有10个副本(通过配置参数mapreduce.client.submit.file.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
第四步:JobClient提交作业到JobTracker,当JobTracker接收到作业之后,将其放到一个作业队列里面,等待作业调度器对其进行调度, 当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对应map和reduce任务,TaskTracker,根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。注意:map任务不是随便的分配给某个TaskTracker,这里有个概念叫数据本地化(Data-Local),指的是将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到改TaskTracker上运行,这叫“运算移动,数据不移动”,而分配reduce任务时不考虑数据本地化。
第五步:TaskTracker每隔一段时间会给JobTracker发送心跳,告诉JobTracker它依然在运行,同时心跳还携带了很多信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,会把该作业设置为(success),当JobClient查询状态时,它将得知任务完成,便显示一条消息给用户。
以上就是从JobClient,JobTracker,TaskTracker角度来分析MapReduce的工作原理。以上的工作原理将流程图的步骤进行了整合。
三,MapReduce编程模型
3.1 原理
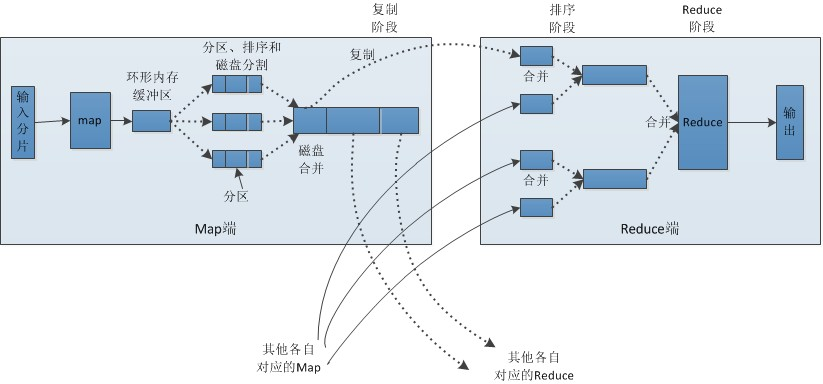
Map端:
1,mapReduce启动后会先扫描整个提交的文件, 然后回对文件进行切片处理:
例如:a.txt(200M), b.txt(300M), c.txt(100M),这些文件将会被切成:split00001 0-128M、split00002 128-200M,split00003 0-128M, split00004 128-256M, split00005 256M-300M, split00006 100M
2,根据切片的数量会启动相应数量的MapTask进行读取,若切片数量很多,而机器启动的MapTask到达了上限,则例如只有两台机器,每台只启动一个Mapask要处理上面的切片,则进行分批的读取,读取的模式是一行一行的读取。每读取一行就可以进行map处理,这个map处理是一个通用的接口,没有被写死,可以为我们自己去实现。而map的过程就是我们进行提取数据的过程,map过程参数的是一组组K:1, K2:1, K3:1数据。
3,map输出的结果会暂时存在在一个环形内存缓冲区内(该缓冲区的大小默认为100M,由io.sort.mb属性控制)。当缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将改缓冲区中的数据写入文件。
4,在将缓冲区数据写入磁盘之前,线程会根据reduce任务的数量将数据划分为相同的数据分区,也就是说一个reduce任务对应一个分区数据。当然也有可能出现一个reduce有多个分区的数据,这样做的目的为了避免有些reduce任务分配到大量的数据。而有些
reduce任务却很少数据。其实对数据分区就是一个hash的过程。然后对每个分区中的数据进行排序。如果此时设置了聚合(Combiner),会将排序后的结果进行聚合操作。这样做的目的是减少数据的写入磁盘的次数和数据的量。
5,当map任务输出最后一个记录后,可能会有溢出文件,这时需要将这些文件合并。合并的过程会不断的进行排序和combiner操作。目的有两个:1,尽量减少每次写入磁盘的数据量; 2,尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且排序的文件。为了减少网络传输的数据量,这里可以将数据进行压缩,只要将只要将mapred.compress.map.out设置为true就可以。
数据压缩:Gzip、Lzo、snappy。
6,将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和obTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就OK了。
Shuffle:
上面map参数的K:V数据会统一的提交到shuffle端,进行shuffle处理,在这个过程中,会对相同的K的值排在一起(排序),不同的K分在不同的区域,这样做的目的是为了ReduceTask读取。若这些K数据有很多组,如何将这些不同的K分配到
有限的ReduceTask中呢,这就需要对这些K进行hash,将这些hash取余,相同的就分在一组ReduceTask中。
Reduce:
1,Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2,随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
3,合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
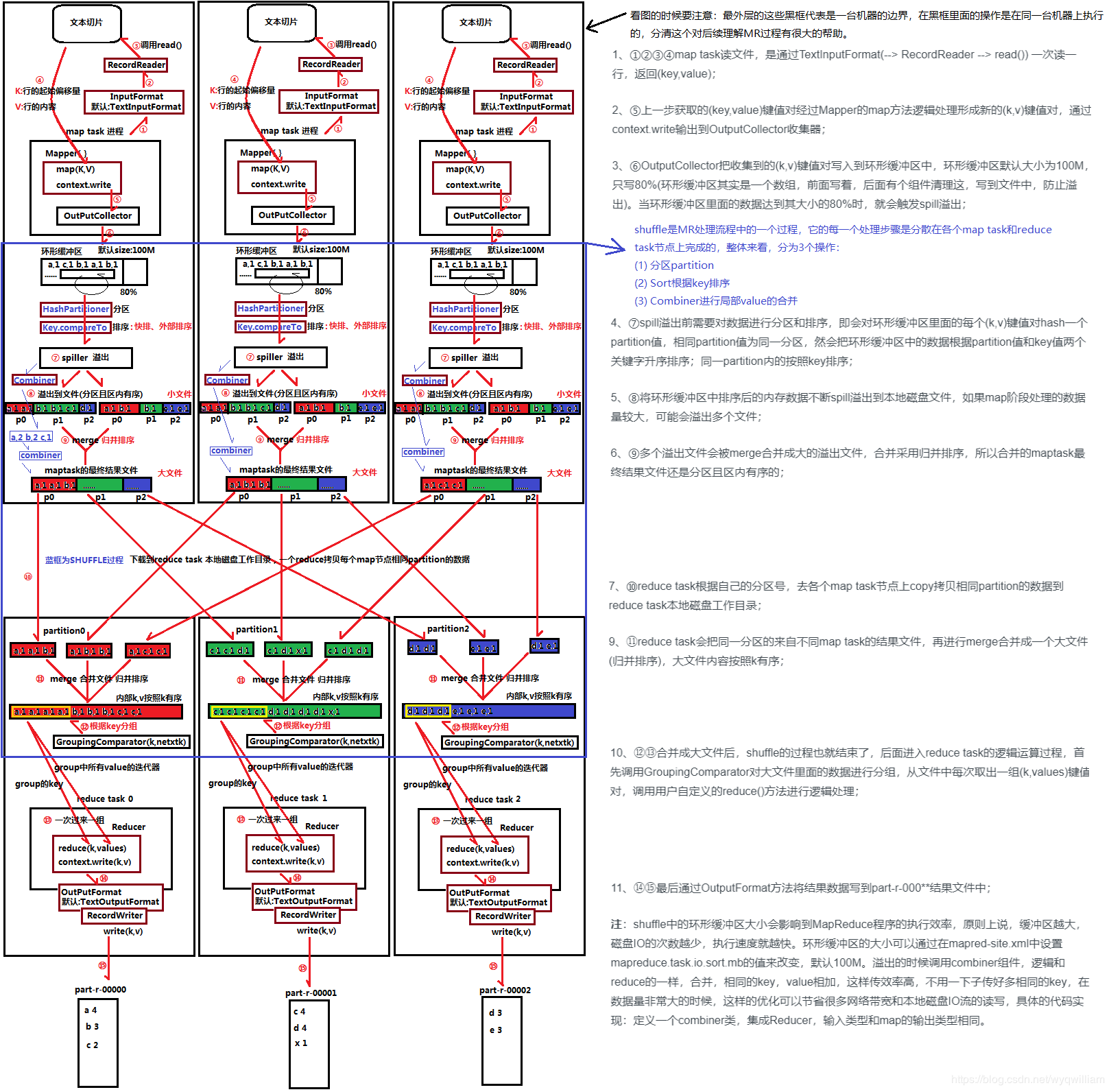
3.2 实例流程图
Hadoop生态集群MapReduce详解的更多相关文章
- Hadoop生态集群YARN详解
一,前言 Hadoop 2.0由三个子系统组成,分别是HDFS.YARN和MapReduce,其中,YARN是一个崭新的资源管理系统,而MapReduce则只是运行在YARN上的一个应用,如果把YAR ...
- Apache + Tomcat集群配置详解 (1)
一.软件准备 Apache 2.2 : http://httpd.apache.org/download.cgi,下载msi安装程序,选择no ssl版本 Tomcat 6.0 : http://to ...
- [转帖]Application Request Route实现IIS Server Farms集群负载详解
Application Request Route实现IIS Server Farms集群负载详解 https://www.cnblogs.com/knowledgesea/p/5099893.ht ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- MySQL集群搭建详解
概述 MySQL Cluster 是MySQL 适合于分布式计算环境的高实用.可拓展.高性能.高冗余版本,其研发设计的初衷就是要满足许多行业里的最严酷应用要求,这些应用中经常要求数据库运行的可靠性要达 ...
- Hadoop生态集群之HDFS
一.HDFS是什么 HDFS是hadoop集群中的一个分布式的我文件存储系统.他将多台集群组建成一个集群,进行海量数据的存储.为超大数据集的应用处理带来了很多便利. 和其他的分布式文件存储系统相比他有 ...
- Storm集群安装详解
storm有两种操作模式: 本地模式和远程模式. 本地模式:你可以在你的本地机器上开发测试你的topology, 一切都在你的本地机器上模拟出来; 远端模式:你提交的topology会在一个集群的机器 ...
- Centos7 zookeeper单机/集群安装详解和开机自启
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的功 ...
- Flume NG高可用集群搭建详解
.Flume NG简述 Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
随机推荐
- ubuntu install wiznote
sudo add-apt-repository ppa:wiznote-team #添加官方源 sudo apt-get update #更新源 sudo apt-get install wiznot ...
- mvc webapi路由重写
修改app_start/webapiconfig.cs using System.Web.Http; using System.Web.Routing; using Ninject; using Tx ...
- Spring配置动态数据源-读写分离和多数据源
在现在互联网系统中,随着用户量的增长,单数据源通常无法满足系统的负载要求.因此为了解决用户量增长带来的压力,在数据库层面会采用读写分离技术和数据库拆分等技术.读写分离就是就是一个Master数据库,多 ...
- undo与redo
http://www.cnblogs.com/HondaHsu/p/3724815.html
- 【netcore基础】.Net core通过 Lucene.Net 和 jieba.NET 处理分词搜索功能
业务要求是对商品标题可以进行模糊搜索 例如用户输入了[我想查询下雅思托福考试],这里我们需要先将这句话分词成[查询][雅思][托福][考试],然后搜索包含相关词汇的商品. 思路如下 首先我们需要把数据 ...
- 【thinkphp5】安全建议:隐藏后台登录入口地址
我们都知道后台 www.test.com/admin 是我们最常用的登录入口,方便的同时也留下了隐患,如果你刚好使用了 admin/ 这种账号密码的方式,会导致我们的后台完全暴露在外. 因此我们建 ...
- 解决Pycharm更新package出现的问题:AttributeError:module 'pip' has no attribute 'main'
很久一段时间没有更新Pycharm当中的package了,今天打开Pycharm点击package更新,发生了错误,AttributeError:module 'pip' has no attribu ...
- xcode8 iOS函数返回值使用警告
没有使用返回值时, 警告 swift: @warn_unused_result func doSomething() -> Bool { return true } OC: - (BOOL)do ...
- Spring 对事务管理的支持
1.Spring对事务管理的支持 Spring为事务管理提供了一致的编程模板,在高层次建立了统一的事务抽象.也就是说,不管选择Spring JDBC.Hibernate .JPA 还是iBatis,S ...
- Realm 简介
是一个跨平台的本地数据库,比sqlite 数据库更轻量级,执行效率更高. 官网地址:https://realm.io/docs/java/latest/