Streaming从Spark2X迁移到Spark1.5 summary
配置文件的加载是一个难点,在local模式下非常容易,但是submit后一直报找不到文件,后来采用将properties文件放在加载类同一个package下,打包到同一个jar中解决。
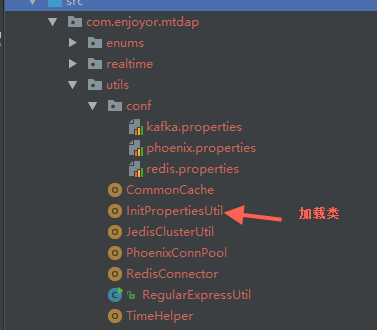
import java.io.{BufferedInputStream , InputStream}
import java.util.Properties
/**
* Created by wulei on 2018/4/4.
* Description: 参数初始化公共类
*/
object InitPropertiesUtil extends Serializable {
/**
* get kafka's properties
* @return java.util.Properties
*/
def initKafkaPro: Properties = {
val prop: Properties = new Properties
val in: InputStream = getClass.getResourceAsStream("conf/kafka.properties")
if (in == null){
println("ERROR : kafka.properties init failed in is null")
}
prop.load(new BufferedInputStream(in))
prop
}
/**
* get redis's properties
* @return java.util.Properties
*/
def initRedisPro: Properties = {
val prop: Properties = new Properties
val in: InputStream = getClass.getResourceAsStream("conf/redis.properties")
prop.load(new BufferedInputStream(in))
prop
}
}
问题: ClassNotFoundException: org.apache.hadoop.hbase.ipc.controller.ClientRpcControllerFactory
java.lang.RuntimeException: java.sql.SQLException: ERROR 103 (08004): Unable to establish connection.
at nl.work.kafkastreamconsumer.phoenix.PhoenixConnection.<init>(PhoenixConnection.java:41)
at nl.work.kafkastreamconsumer.phoenix.LinePersister$1.call(LinePersister.java:40)
at nl.work.kafkastreamconsumer.phoenix.LinePersister$1.call(LinePersister.java:32)
at org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1.apply(JavaPairRDD.scala:999)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:328)
at scala.collection.Iterator$class.foreach(Iterator.scala:727)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1157)
at scala.collection.generic.Growable$class.$plus$plus$eq(Growable.scala:48)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:103)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:47)
at scala.collection.TraversableOnce$class.to(TraversableOnce.scala:273)
at scala.collection.AbstractIterator.to(Iterator.scala:1157)
at scala.collection.TraversableOnce$class.toBuffer(TraversableOnce.scala:265)
at scala.collection.AbstractIterator.toBuffer(Iterator.scala:1157)
at scala.collection.TraversableOnce$class.toArray(TraversableOnce.scala:252)
at scala.collection.AbstractIterator.toArray(Iterator.scala:1157)
at org.apache.spark.rdd.RDD$$anonfun$17.apply(RDD.scala:813)
at org.apache.spark.rdd.RDD$$anonfun$17.apply(RDD.scala:813)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1498)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1498)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:61)
at org.apache.spark.scheduler.Task.run(Task.scala:64)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:203)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.sql.SQLException: ERROR 103 (08004): Unable to establish connection.
at org.apache.phoenix.exception.SQLExceptionCode$Factory$1.newException(SQLExceptionCode.java:362)
at org.apache.phoenix.exception.SQLExceptionInfo.buildException(SQLExceptionInfo.java:133)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.openConnection(ConnectionQueryServicesImpl.java:282)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.access$300(ConnectionQueryServicesImpl.java:166)
at org.apache.phoenix.query.ConnectionQueryServicesImpl$11.call(ConnectionQueryServicesImpl.java:1831)
at org.apache.phoenix.query.ConnectionQueryServicesImpl$11.call(ConnectionQueryServicesImpl.java:1810)
at org.apache.phoenix.util.PhoenixContextExecutor.call(PhoenixContextExecutor.java:77)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.init(ConnectionQueryServicesImpl.java:1810)
at org.apache.phoenix.jdbc.PhoenixDriver.getConnectionQueryServices(PhoenixDriver.java:162)
at org.apache.phoenix.jdbc.PhoenixEmbeddedDriver.connect(PhoenixEmbeddedDriver.java:126)
at org.apache.phoenix.jdbc.PhoenixDriver.connect(PhoenixDriver.java:133)
at java.sql.DriverManager.getConnection(DriverManager.java:571)
at java.sql.DriverManager.getConnection(DriverManager.java:233)
at nl.work.kafkastreamconsumer.phoenix.PhoenixConnection.<init>(PhoenixConnection.java:39)
... 25 more
Caused by: java.io.IOException: java.lang.reflect.InvocationTargetException
at org.apache.hadoop.hbase.client.HConnectionManager.createConnection(HConnectionManager.java:457)
at org.apache.hadoop.hbase.client.HConnectionManager.createConnection(HConnectionManager.java:350)
at org.apache.phoenix.query.HConnectionFactory$HConnectionFactoryImpl.createConnection(HConnectionFactory.java:47)
at org.apache.phoenix.query.ConnectionQueryServicesImpl.openConnection(ConnectionQueryServicesImpl.java:280)
... 36 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.GeneratedConstructorAccessor8.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.hbase.client.HConnectionManager.createConnection(HConnectionManager.java:455)
... 39 more
Caused by: java.lang.UnsupportedOperationException: Unable to find org.apache.hadoop.hbase.ipc.controller.ClientRpcControllerFactory
at org.apache.hadoop.hbase.util.ReflectionUtils.instantiateWithCustomCtor(ReflectionUtils.java:36)
at org.apache.hadoop.hbase.ipc.RpcControllerFactory.instantiate(RpcControllerFactory.java:56)
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.<init>(HConnectionManager.java:769)
at org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImplementation.<init>(HConnectionManager.java:689)
... 43 more
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hbase.ipc.controller.ClientRpcControllerFactory
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:191)
at org.apache.hadoop.hbase.util.ReflectionUtils.instantiateWithCustomCtor(ReflectionUtils.java:32)
... 46 more
追踪ClientRpcControllerFactory这个类,将会发现是phoenix-core-4.4.0-HBase-1.0.jar中的,根据报错信息,可以知道也确实HBase的连接出现问题,于是我第一步去找是否将phoenix-core-4.4.0-HBase-1.0.jar这个包拷贝到Spark Client下,有的,
第二,我去找自己的spark-submit jars命令中是否对该包的引用有误,比如路径、逗号符号等,错误依然不在此。嗯! 放弃思考,已超出自己的理解范围了,马上在stackoverflow上找到这个原生Bug
I had have same problem. The reason of problem,Phoenix use a custom rpc controller factory which is a Phoenix-specific one to configure the priorities for index and system catalog table in cluster side. It is called ClientRpcControllerFactory. In sometimes Phoenix-enabled clusters are used from pure-HBase client applications resulting in ClassNotFoundExceptions in application code or MapReduce jobs. Since hbase configuration is shared between Phoenix-clients and HBase clients, having different configurations at the client side is hard. That's why you get this exception. This problem is fixed by HBASE-14960. If you hbase version older than 2.0.0, 1.2.0, 1.3.0, 0.98.17 You can define your client side rpc controller with this setting in hbase-site.xml: <property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.RpcControllerFactory</value>
</property>
Streaming从Spark2X迁移到Spark1.5 summary的更多相关文章
- 转:FSMT:文件服务器从03迁移到08R2实战演练
另外参见:http://www.canway.net/Lists/CanwayOriginalArticels/DispForm.aspx?ID=282 以前做过一个项目,是把文件服务器从03升级到0 ...
- 【大数据处理架构】1.spark streaming
1. spark 是什么? >Apache Spark 是一个类似hadoop的开源高速集群运算环境 与后者不同的是,spark更快(官方的说法是快近100倍).提供高层JAVA,Scala, ...
- 【开源】OSharp框架解说系列(5.2):EntityFramework数据层实现
OSharp是什么? OSharp是个快速开发框架,但不是一个大而全的包罗万象的框架,严格的说,OSharp中什么都没有实现.与其他大而全的框架最大的不同点,就是OSharp只做抽象封装,不做实现.依 ...
- 【转】最近搞Hadoop集群迁移踩的坑杂记
http://ju.outofmemory.cn/entry/237491 Overview 最近一段时间都在搞集群迁移.最早公司的hadoop数据集群实在阿里云上的,机器不多,大概4台的样子,据说每 ...
- How Cigna Tuned Its Spark Streaming App for Real-time Processing with Apache Kafka
Explore the configuration changes that Cigna’s Big Data Analytics team has made to optimize the perf ...
- 浅议Grpc传输机制和WCF中的回调机制的代码迁移
浅议Grpc传输机制和WCF中的回调机制的代码迁移 一.引子 如您所知,gRPC是目前比较常见的rpc框架,可以方便的作为服务与服务之间的通信基础设施,为构建微服务体系提供非常强有力的支持. 而基于. ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
随机推荐
- MongoDB增删改查实例
MongoDB之Java测试代码(DAO层),mongodbdao MongoInit.java是数据库初始化及连接类 MongoUtils.java是对mongodb的各种操作方法 MongoIni ...
- 通过反射调用Unity编辑器提供的各种功能
Unity编辑器功能丰富易上手,其实编辑器提供的大多数菜单操作,在代码里面都是能够找到对应接口的,但是这些接口都没有对我们开放,怎么办? 很简单,直接使用反射调用即可. 首先使用Reflector或I ...
- 三层构架和 MVC的区别和理解
1.三层构架和 MVC 意思一样么? Java WEB 开发中,服务端通常分为表示层.业务层.持久层,这就是所谓的三层架构: 1.表示层负责接收用户请求.转发请求.生成数据的视图等: 2.业务层负责组 ...
- 哪个 Linux 内核版本号是 “稳定的”? | Linux 中国
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/F8qG7f9YD02Pe/article/details/79329760 https://mmbi ...
- Java8学习笔记(十一)--并发与非并发流下reduce比较
BinaryOperator<Integer> operator = (l, r) -> l + r; BiFunction<Integer, Integer, Integer ...
- 浅从System.Web.Http.Owin的HttpMessageHandlerAdapter看适配器模式
本文版权归博客园和作者吴双本人共同所有 转载和爬虫请注明原文地址 www.cnblogs.com/tdws 一.写在前面 适配器模式(Adapter) 可用来在现有接口和不兼容的类之间进行适配.有助于 ...
- iOS开发之--在UIWindow上展示/移除一个View
代码如下: 展示 UIWindow *window = [[UIApplication sharedApplication].windows lastObject]; [window addSubvi ...
- ubuntu使任何地方右键都能打开terminal
ubuntu下安装terminal,在任何地方右键都可以快速的打开termial sudo apt-get install nautilus-open-terminal 重启电脑
- VS2015编译rtklib2.4.2
准备工作 在VS2015下新建一个win32的dll项目(空项目) 把在github上下载的rtklib2.4.2里的src文件夹复制到刚刚建立的win32下 把src里的文件添加到项目里,其中头文件 ...
- windows服务安装 System.IO.FileLoadException
报错如下: System.IO.FileLoadException: 未能加载文件或程序集“file:///D:\WindowsService\bin\Debug\WindowsService.exe ...