Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法
1.安装步骤:
首先,你要先进入pycharm的Project Interpreter界面,进入方法是:setting(ctrl+alt+s) ->Project Interpreter,Project Interpreter在具体的Project下。如下图所示:
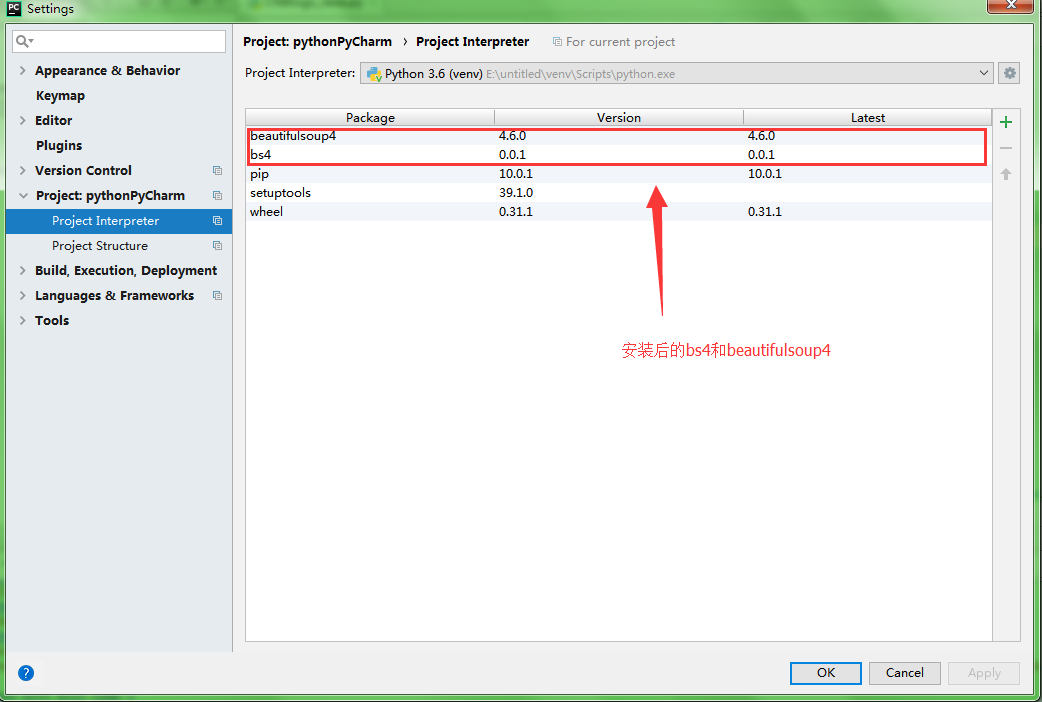
点击“+”,输入beautifulsoup ,就可以找到你要安装的插件了。
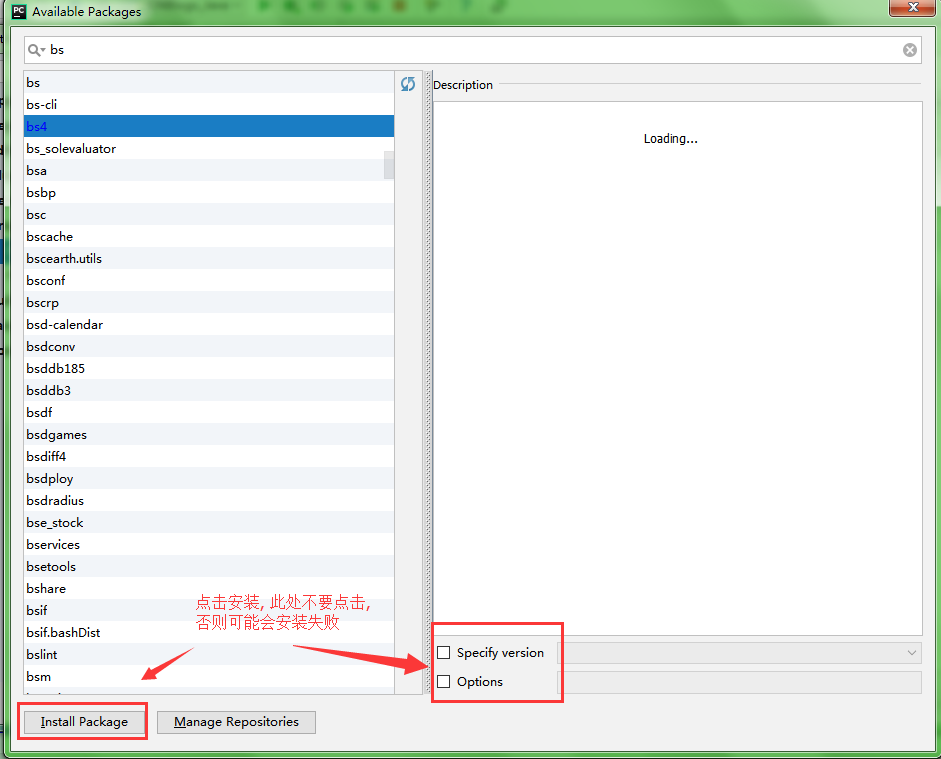
注意: Python3的选择bs4进行安装,Python2的选择beautifulSoup。
Pycharm安装package出现如下报错:
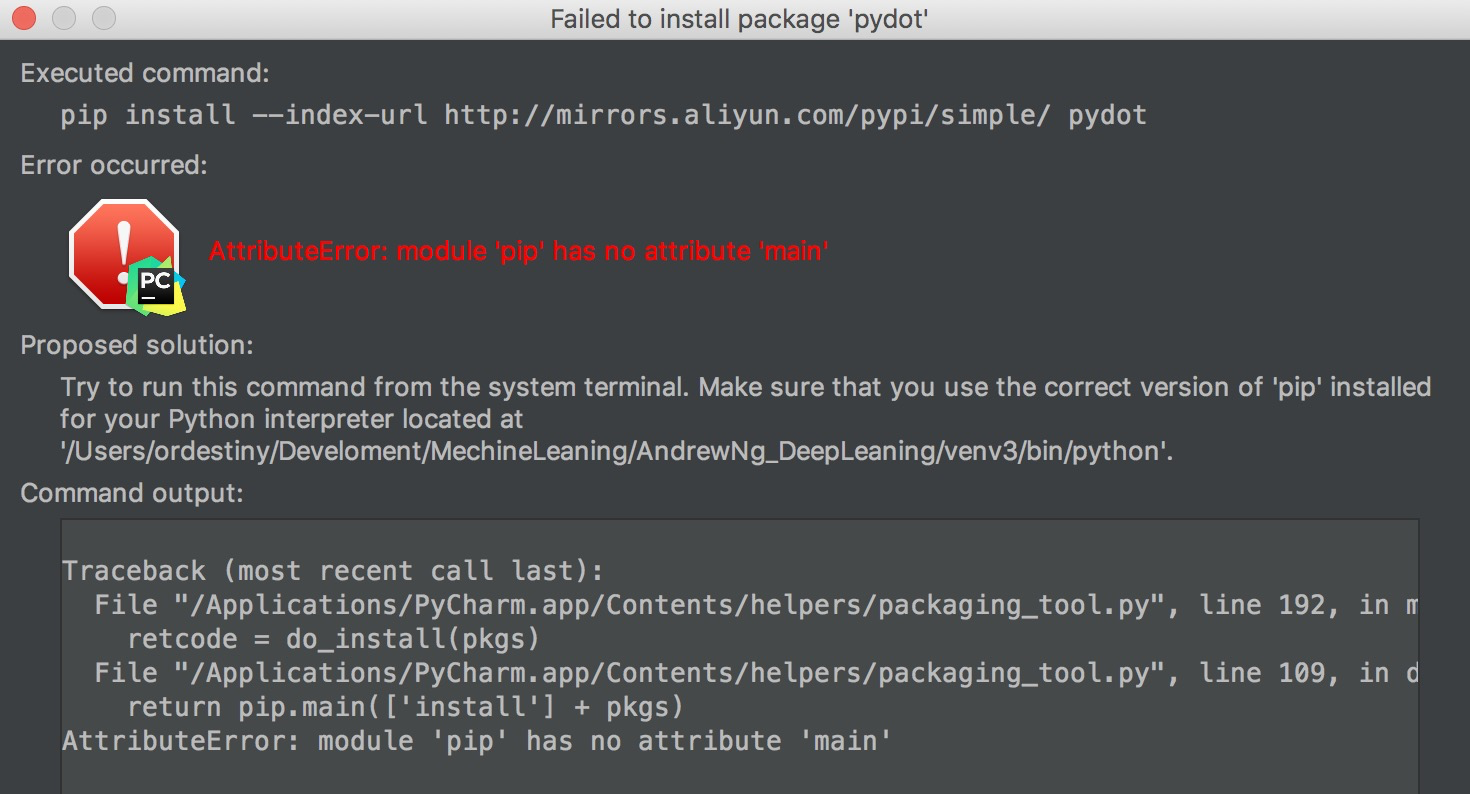
这是由于pip版本的问题,pip 10.0版本的没有main()方法, 因此更改如下代码即可:
可以考虑降个版本:python -m pip install --upgrade pip==9.0.3
解决方法:
找到C:\Program Files\JetBrains\PyCharm 2017.3.2安装目录下的 helpers/packaging_tool.py文件,找到如下代码:
def do_install(pkgs):
try:
import pip
except ImportError:
error_no_pip()
return main(['install'] + pkgs)
def do_uninstall(pkgs):
try:
import pip
except ImportError:
error_no_pip()
return main(['uninstall', '-y'] + pkgs)
修改为如下,保存即可
def do_install(pkgs):
try:
# import pip
try:
from pip._internal import main
except Exception:
from pip import main
except ImportError:
error_no_pip()
return main(['install'] + pkgs) def do_uninstall(pkgs):
try:
# import pip
try:
from pip._internal import main
except Exception:
from pip import main
except ImportError:
error_no_pip()
return main(['uninstall', '-y'] + pkgs)
再次运行就OK了
Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法的更多相关文章
- [转]Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法
原文地址:https://www.cnblogs.com/yysbolg/p/9040649.html 刚开始学习一门技术最麻烦的问题就是搞定IDE环境,直接在PyCharm里安装BeautifulS ...
- pycharm中导入包失败的解决办法
将鼠标移动到requests处,出现如下提示 按住alt+enter键,点击install package requests即可安装requests包 安装成功后
- python爬虫数据解析之BeautifulSoup
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. BeautfulSoup是python爬虫三 ...
- 【Python】在Pycharm中安装爬虫库requests , BeautifulSoup , lxml 的解决方法
BeautifulSoup在学习Python过程中可能需要用到一些爬虫库 例如:requests BeautifulSoup和lxml库 前面的两个库,用Pychram都可以通过 File--> ...
- 【XPath Helper:chrome爬虫网页解析工具 Chrome插件】XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插件网
[XPath Helper:chrome爬虫网页解析工具 Chrome插件]XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插 ...
- python爬虫网页解析之lxml模块
08.06自我总结 python爬虫网页解析之lxml模块 一.模块的安装 windows系统下的安装: 方法一:pip3 install lxml 方法二:下载对应系统版本的wheel文件:http ...
- python爬虫网页解析之parsel模块
08.06自我总结 python爬虫网页解析之parsel模块 一.parsel模块安装 官网链接https://pypi.org/project/parsel/1.0.2/ pip install ...
- web报表工具FineReport使用中遇到的常见报错及解决办法(二)
web报表工具FineReport使用中遇到的常见报错及解决办法(二) 这里写点抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己. 出现问题先搜一下文档上有没有,再看看度娘 ...
- win10 +python3.6环境下安装opencv以及pycharm导入cv2有问题的解决办法
一.安装opencv 借鉴的这篇博客已经写得很清楚了--------https://blog.csdn.net/u011321546/article/details/79499598 ,这 ...
随机推荐
- Spark中的Phoenix Dynamic Columns
代码及使用示例:https://github.com/wlu-mstr/spark-phoenix-dynamic phoenix dynamic columns HBase的数据模型是动态的,很多系 ...
- .Wait()与.GetAwaiter()之间有什么区别
两者都是同步等待操作的结果差异主要在于处理异常.使用Wait,异常堆栈跟踪不会改变并表示异常时的实际堆栈,因此如果您有一段代码在线程池线程上运行,那么您将拥有类似的堆栈 ThreadPoolThrea ...
- Js之设置日期时间 判断日期是否在范围内
var now = new Date(); var startDate = new Date(); startDate.setFullYear(2018, 08, 07); startDate.set ...
- 闲话ajax,例ajax轮询,ajax上传文件[开发篇]
引语:ajax这门技术早已见怪不怪了,我本人也只是就自己真实的经验去总结一些不足道的话.供不是特别了解的朋友参考参考! 本来早就想写一篇关于ajax的文章的,但是前段时间一直很忙,就搁置了,趁着元旦放 ...
- itext实现合同尾部签章部分自动添加,定位签名
使用的pom <!-- pdf处理 start--> <dependency> <groupId>com.itextpdf</groupId> < ...
- LDA-线性判别分析(三)推广到 Multi-classes 情形
本来是要调研 Latent Dirichlet Allocation 的那个 LDA 的, 没想到查到很多关于 Linear Discriminant Analysis 这个 LDA 的资料.初步看了 ...
- 2.WF 4.5 流程引擎设计思路
本文主要给大家分享下基于WF 4.5框架的流程引擎设计思路 1.流程启动时的数据写入EventMsgPP对象中,ObjectAssemblyType记录流程启动时需要的类型,ObjectContent ...
- GO入门——6. struct与方法
1 struct Go 中的struct与C中的struct非常相似,并且Go没有class 使用 type struct{} 定义结构,名称遵循可见性规则 支持指向自身的指针类型成员 支持匿名结构, ...
- Linux_CentOS-服务器搭建 <三> 补充
今天 才发现,服务器上 JDK 都没有好好的安装下.在这里补充说下. 1.看看机子上JDK的安装了多少 $ rpm -qa |grep java 会出现类似: java-1.6.0-openjdk-1 ...
- Kali中装中文输入法小企鹅
STEP 1. 装fcitx框架,apt-get install fcitx STEP 2. 装googlepinyin输入法,apt-get install fcitx-googlepinyin S ...