在线安装TIDB集群
在线安装TiDB集群
- 服务器准备
说明:TiDB8需要能够连接外网,以便下载各类安装包
TiDB4非必须,但最好是有一台,因为后续测试Mysql数据同步或者进行性能比较时,都要用到
TiKV最好是采用Ext4文件格式,所以使用挂载盘的方式增加(如果没有数据盘,那么不配置也能安装成功)
| 机器名 | IP | 操作系统 | 配置 | 用途 |
| TiDB1 | ***.62 | CentOS7.4 X64 | 4C+8G+60G+200G扩展 | TiKV+TiSpark |
| TiDB2 | ***.63 | CentOS7.4 X64 | 4C+8G+60G+200G扩展 | TiKV+TiSpark |
| TiDB3 | ***.64 | CentOS7.4 X64 | 4C+8G+60G+200G扩展 | TiKV+TiSpark |
| TiDB4 | ***.65 | CentOS7.4 X64 | 4C+8G+260G | Mysql5.7+测试工具 |
| TiDB5 | ***.66 | CentOS7.4 X64 | 4C+8G+60G | TiDB+PD |
| TiDB6 | ***.67 | CentOS7.4 X64 | 4C+8G+60G | TiDB+PD |
| TiDB7 | ***.68 | CentOS7.4 X64 | 4C+8G+60G | TiDB+PD |
| TiDB8 | ***.69 | CentOS7.4 X64 | 4C+8G+60G | 中控机ansible+monitor |
- TiKV数据盘挂载
在TiDB1,TiDB2,TiDB3都需要进行操作。
执行 vi /etc/fstab
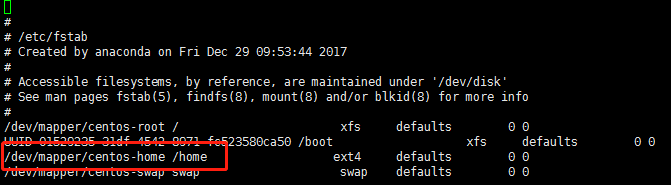
添加挂载参数
/dev/mapper/centos-home /home ext4 defaults,nodelalloc,noatime
参数解释:
noatime - 不更新文件系统上 inode 访问记录,可以提升性能
nodelalloc情况下每5秒文件系统会提交日志触发回写;delalloc情况下,系统会在约每30秒左右触发一次回写。对于频繁读写,可以加快写入速度。
最后一个0表示是否使用fsck选项,fsck命令通过检测该字段来决定文件系统通过什么顺序来扫描检查,根文件系统/对应该字段的值应该为1,其他文件系统应该为2。若文件系统无需在启动时扫描检查,则设置该字段为0。
卸载目录并重新挂载
# umount /home
# mount -a
确认是否生效,如果生效了会多出nodelalloc
# mount -t ext4
/dev/mapper/centos-home on /home type ext4 (rw,noatime,seclabel,nodelalloc,data=ordered)
- 在中控机上添加tidb用户并设置免密码
添加用户
# useradd tidb
# passwd tidb
如果密码设置过短,则会提示密码少于8位,但只是警告继续即可。若设置不成功,可修改vi /etc/login.defs中的PASS_MIN_LEN参数
设置免密
# visudo
将tidb ALL=(ALL) NOPASSWD: ALL加入到最后一行并保存
- 在中控机上配置 用户、Ansible、免密
使用tidb用户登录中控机
下载TiDb-Ansible
$ cd /home/tidb
$ sudo yum -y install git
$ git clone -b release-2.0 https://github.com/pingcap/tidb-ansible.git
版本可以到github上看一下,是否有更新。如果使用主线版本执行 git clone https://github.com/pingcap/tidb-ansible.git
安装ansible
$ sudo yum -y install epel-release
$ sudo yum -y install python-pip curl
$ sudo yum -y install sshpass
$ cd tidb-ansible
$ sudo pip install -r ./requirements.txt
$ ansible --version
ansible 2.5.
配置其它服务器的免密
$ ssh-keygen -t rsa
生成密钥,连续回车即可
配置设置免密的目标服务器,注意将***换成真实的IP。
$ vi hosts.ini [servers]
***.***.***.
***.***.***.
***.***.***.
***.***.***.
***.***.***.
***.***.***.
***.***.***.68
***.***.***.69
[all:vars]
username = tidb
ntp_server = pool.ntp.org
使用ansible执行免密
$ ansible-playbook -i hosts.ini create_users.yml -k
检验
$ ssh ***.***.***.
$ sudo -su root
如果在中控机上能够无密码登录,并且登录后可以无密码切换到root。即说明免密设置成功
特别注意中控机本机也要免密,后续将组件安装到中控机时就不用再进行特别的设置了
- 关闭所有服务器上的防火墙
使用tidb用户登录,关闭防火墙,并取消开机启动
$ cd /home/tidb/tidb-ansible
$ ansible -i hosts.ini all -m shell -a "firewall-cmd --state" -b
$ sudo systemctl stop firewalld.service
$ sudo systemctl disable firewalld.service
$ ansible -i hosts.ini all -m shell -a "systemctl stop firewalld.service" -b
$ ansible -i hosts.ini all -m shell -a "systemctl disable firewalld.service" -b
- 设置NTP
使用tidb用户登录中控机,安装ntp服务
$ cd /home/tidb/tidb-ansible
$ ansible -i hosts.ini all -m shell -a "yum install -y ntp" -b
配置中控机做为时间服务器
$ sudo vi /etc/ntp.conf 文件做如下修改
# Hosts on local network are less restricted.
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
restrict ***.**.*.0 mask 255.255.255.0 # Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server 127.127.1.0
server .centos.pool.ntp.org iburst
server .centos.pool.ntp.org iburst
server .centos.pool.ntp.org iburst
server .centos.pool.ntp.org iburst
说明:需要增加一个restrict,可以使用当前服务器的IP段,上面使用***是为了保密。注意填写自己的IP段。
ntp中本机使用server 127.127.1.0
配置所有从机的ntp配置
$ sudo vi /etc/ntp.conf 文件做如下修改
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server ***.***.***.69 iburst
server .centos.pool.ntp.org iburst
server .centos.pool.ntp.org iburst
iburst : 当server不可达时,以默认发包速率的8倍向服务器发包。***是为了保密,请修改为主控机的实际IP
启动ntp服务
使用tidb登录中控机
$ cd /home/tidb/tidb-ansible
$ ansible -i hosts.ini all -m shell -a "systemctl disable chronyd.service" -b
$ ansible -i hosts.ini all -m shell -a "systemctl enable ntpd.service" -b
$ ansible -i hosts.ini all -m shell -a "systemctl start ntpd.service" -b
检验ntp服务
$ ansible -i hosts.ini all -m shell -a "ntpstat" -b
$ ansible -i hosts.ini all -m shell -a "ntpq -p" -b
ntpstat可以查看服务器的ntp状态,ntpq可以查看各服务器当前使用的时间服务器
特别注意:服务器重启以后,去启动tidb时,可能会提示ntp同步不成功,确保ntp服务是开启的,等待几分钟就好了。
- 配置集群规划
本次每台服务器只配置一个TiKV,并且使用标准目录配置,如果需要一台服务器配置多KV或者调整数据目录,请参考官方文档
| 机器名 | IP | 操作系统 | 配置 | 用途 |
| TiDB1 | ***.62 | CentOS7.4 X64 | 4C+8G+60G+200G扩展 | TiKV+TiSpark |
| TiDB2 | ***.63 | CentOS7.4 X64 | 4C+8G+60G+200G扩展 | TiKV+TiSpark |
| TiDB3 | ***.64 | CentOS7.4 X64 | 4C+8G+60G+200G扩展 | TiKV+TiSpark |
| TiDB4 | ***.65 | CentOS7.4 X64 | 4C+8G+260G | Mysql5.7+测试工具 |
| TiDB5 | ***.66 | CentOS7.4 X64 | 4C+8G+60G | TiDB+PD |
| TiDB6 | ***.67 | CentOS7.4 X64 | 4C+8G+60G | TiDB+PD |
| TiDB7 | ***.68 | CentOS7.4 X64 | 4C+8G+60G | TiDB+PD |
| TiDB8 | ***.69 | CentOS7.4 X64 | 4C+8G+60G | 中控机ansible+monitor |
使用tidb登录中控机,进行规划配置
$ cd /home/tidb/tidb-ansible
$ vi inventory.ini 将服务器IP配置到各配置项下面
## TiDB Cluster Part
[tidb_servers]
***.***.**
***.***.**
***.***.** [tikv_servers]
***.***.**
***.***.**
***.***.** [pd_servers]
***.***.**
***.***.**
***.***.** [spark_master]
***.***.** [spark_slaves]
***.***.**
***.***.** ## Monitoring Part
# prometheus and pushgateway servers
[monitoring_servers]
***.***.** [grafana_servers]
***.***.** # node_exporter and blackbox_exporter servers
[monitored_servers]
***.***.**
***.***.**
***.***.**
***.***.**
***.***.**
***.***.**
***.***.**
***.***.**
请将***替换为实际的IP
- 安装TiDB集群
安装前检验
执行以下命令如果所有 server 返回 tidb 表示 ssh 互信配置成功。
$ ansible -i inventory.ini all -m shell -a 'whoami'
执行以下命令如果所有 server 返回 root 表示 tidb 用户 sudo 免密码配置成功。
$ ansible -i inventory.ini all -m shell -a 'whoami' -b
下载安装包
$ ansible-playbook local_prepare.yml
执行后会自动下载最新的TiDB包到downloads目录中
修改系统环境,修改内核参数
$ ansible-playbook bootstrap.yml
修改后会做一些检测,也会提示一些错误,例如CPU核数不够,如果不是关键问题,可以直接继续。
根据inventory.ini部署集群
$ ansible-playbook deploy.yml
部署需要的时间比较长,可以看看日志输出,当出现以下字样时,说明部署成功。如果failed不是0,那么可以重新执行部署,如果多次部署还不成功,则需要看一下,错误原因了。
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
localhost : ok= changed= unreachable= failed= Congrats! All goes well. :-)
为spark配置JDK
如果使用了TiSpark,那么需要为对应的服务器配置JDK。首先将JDK安装包放到中控机上,然后再传给TiSpark所在的服务器。
如果可以直接传过去,也可以不使用此种方式
$ cd /home/tidb
$ mkdir software
先将jdk文件传送到此目录中,jdk-8u91-linux-x64.tar.gz
在TiKV的服务器上创建/opt/jdk目录。然后回到中控机使用scp进行传输
scp jdk-8u91-linux-x64.tar.gz root@***.**.**.:/opt/jdk/
scp jdk-8u91-linux-x64.tar.gz root@***.**.**.:/opt/jdk/
scp jdk-8u91-linux-x64.tar.gz root@***.**.**.:/opt/jdk/
请将***换成实际IP
使用root切换到62、63、64三台服务器上,进行jdk解压,并进行环境变量配置。以62为例
$ ssh 172.18.100.62
$ su -
# cd /opt/jdk/
# tar zxvf jdk-8u91-linux-x64.tar.gz
# vi /etc/profile 在文件的最后位置增加JDK配置。 done export JAVA_HOME=/opt/jdk/jdk1.8.0_91
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar unset i
unset -f pathmunge
验证JDK安装是否成功
# source /etc/profile
# java -version
# su - tidb
# java -version
- 启动和停止TiDB集群
使用tidb登录,启动集群
$ cd /home/tidb/tidb-ansible
$ ansible-playbook start.yml
出现以下输出,代表启动成功
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
localhost : ok= changed= unreachable= failed= Congrats! All goes well. :-)
使用tidb登录,停止集群
$ cd /home/tidb/tidb-ansible
$ ansible-playbook stop.yml
出现以下输出,代表停止成功
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
***.***.**. : ok= changed= unreachable= failed=
localhost : ok= changed= unreachable= failed= Congrats! All goes well. :-)
- 检查集群状态
使用mysql客户端工具测试
mysql -u root -h ***.***.**.66 -P 4000mysql -u root -h ***.***.**.67 -P 4000mysql -u root -h ***.***.**.68 -P 4000
通过浏览器访问监控平台
地址:http://***.***.**.69:3000 默认帐号密码是:admin/admin
至此平台安装完成,TiSpark目前还没有测试,代测试后补充这部分内容。
- 安装mysql客户端
如果手头没有mysql服务器,那么就无法使用mysql命令,所以这里提供mysql客户端的安装方法
$ cd /home/tidb/
$ mkdir software
$ cd software
$ mkdir mysql
$ sudo yum -y install wget
$ wget https://repo.mysql.com//mysql57-community-release-el7-11.noarch.rpm
$ sudo yum install -y mysql57-community-release-el7-.noarch.rpm
$ sudo yum install -y mysql-community-client
安装成功后,安装目录就可以删除了。
- 使用tpch-mysql加载数据(可选)
下载tpch工具
$ cd /home/tidb
$ git clone https://github.com/maobuji/tpch-mysql
$ cd tpch-mysql/test-tools
$ chmod *.sh
配置tpch导入工具
$ vi config.properties
在文件中配置数据库地址、用户名等内容
生成待导入数据
$ sh dataMake.sh
创建库表并导入数据
$ sh dataImport.sh
导入数据库需要一定时间,需要耐心等待
如果设置的是并发导入,任务会进入后台,且结束不会提示。如果用ps查到类似的进程,则说明还在导入中
$ ps -ef|grep tpch tidb : pts/ :: mysql -h 172.34.34.66 -P -uroot --local-infile= -D tpch
如果希望知道进度,可以将config文件中的target_db_asynchronous 改为1,逐表进行导入。
生成查询sql
$ sh queryMake.sh
$ cd queries
目录下会生成tpch的22个查询sql,可以用于测试执行
- 启动TiSpark
使用tidb用户登录TIDB1,启动master
$ cd /home/tidb/deploy/spark
$ ./sbin/start-master.sh
启动成功后,可以访问http://TIDB1_IP:8080/ 进入管控台,后续加入Spark-Slave后也可以通过管控台查看Slave是否已加入集群
使用tidb用户登录TIDB2,TIDB3,启动Slave
$ cd /home/tidb/deploy/spark
$ ./sbin/start-slave.sh spark://TIDB1_IP:7077
再次访问管控台,可以看到Slave已经加入了
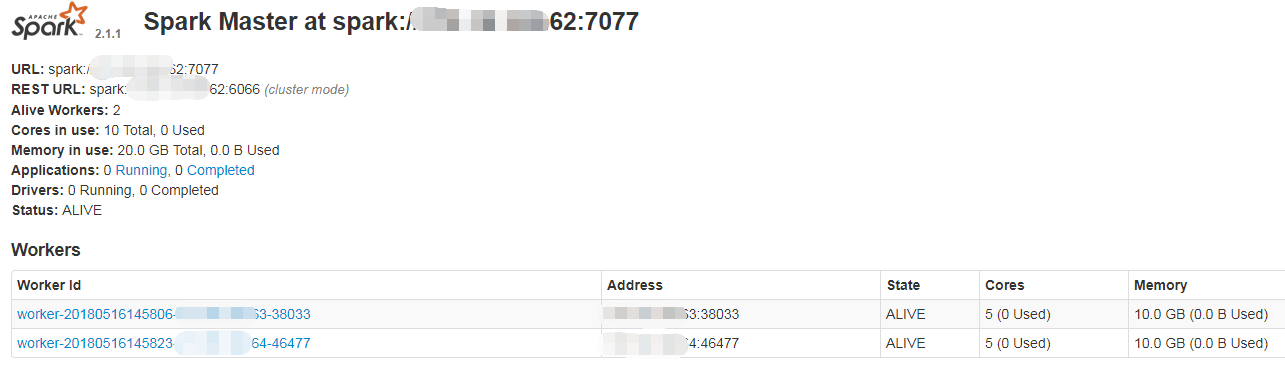
配置信息
TiSpark需要配置PD信息
/home/tidb/deploy/spark/conf/spark-defaults.conf
由于我们在开始的规划文档中已经配置好了,所以只要看一下文件内容即可,不再需要配置了
spark.tispark.pd.addresses这个配置项目应该指向PD的IP列表,如果没有则手工配置 ***.***.**.66:2379,***.***.**.67:2379,***.***.**.68:2379
- 运行TiSpark测试
目前数据库中已经有了tpch数据库,我们对这个数据库进行查询。
$ cd /home/tidb/deploy/spark/bin
$ sh spark-shell 启动成功后会出现如下输出:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.
/_/ Using Scala version 2.11. (Java HotSpot(TM) -Bit Server VM, Java 1.8.0_91)
Type in expressions to have them evaluated.
Type :help for more information.
执行查询
scala> import org.apache.spark.sql.TiContext
import org.apache.spark.sql.TiContext scala> val ti = new TiContext(spark)
ti: org.apache.spark.sql.TiContext = org.apache.spark.sql.TiContext@3d6c7152 scala> ti.tidbMapDatabase("tpch") scala> spark.sql("select count(*) from lineitem").show
+--------+
|count()|
+--------+
| |
+--------+
除了使用spark-shell以外,也可以使用tispark-sql,即可以直接执行sql语句,不过该工具没有被默认安装,需要自己下载
使用tidb保持登录在TiSpark的master上
$ cd /home/tidb/deploy/spark/bin
$ sudo yum install -y wget
$ wget https://raw.githubusercontent.com/pingcap/tispark/master/core/scripts/tispark-sql
$ chmod tispark-sql
$ sh tispark-sql
等一会则进入输入模式
tispark-sql> use tpch;
tispark-sql> show databases;
以下内查询结果:
.......
18/05/17 10:14:32 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
18/05/17 10:14:32 INFO DAGScheduler: ResultStage 1 (processCmd at CliDriver.java:376) finished in 0.101 s
18/05/17 10:14:32 INFO DAGScheduler: Job 1 finished: processCmd at CliDriver.java:376, took 0.147235 s
test
tpch
mysql
default
Time taken: 0.206 seconds, Fetched 4 row(s)
18/05/17 10:14:32 INFO CliDriver: Time taken: 0.206 seconds, Fetched 4 row(s)
查询输出的日志内容非常多,结果也混在里边,目前还太清楚,如何配置参数,不输出查询过程。
自此, TiSpark测试完成
在线安装TIDB集群的更多相关文章
- 在线安装CM集群
https://www.cloudera.com/documentation/manager/5-0-x/Cloudera-Manager-Installation-Guide/cm5ig_insta ...
- Centos7配置TiDB集群
一:各模块属性 模块名称 状态 建议实例数 功能 负载均衡组件 TiDB 无状态 2 接收SQL请求,处理SQL相关逻辑,并通过PB找到存储数据的TiKV地址 LVS.HAProxy.F5 PB 集群 ...
- TiDB集群安装主要操作
TiDB集群安装主要操作 参考资料:https://www.cnblogs.com/plyx/archive/2018/12/21/10158615.html 一.TiDB数据简介 TiDB 是 Pi ...
- centos7.0 安装redis集群
生产环境下redis基本上都是用的集群,毕竟单机版随时都可能挂掉,风险太大.这里我就来搭建一个基本的redis集群,功能够用但是还需要完善,当然如果有钱可以去阿里云买云数据库Redis版的,那个还是很 ...
- CentOS7 搭建Ambari-Server,安装Hadoop集群(一)
2017-07-05:修正几处拼写错误,之前没发现,抱歉! 第一次在cnblogs上发表文章,效果肯定不会好,希望各位多包涵. 编写这个文档的背景是月中的时候,部门老大希望我们能够抽时间学习一下Had ...
- linux下redis的安装和集群搭建
一.redis概述 1.1.目前redis支持的cluster特性: 1):节点自动发现. 2):slave->master 选举,集群容错. 3):Hot resharding:在线分片. 4 ...
- 使用 Docker Compose 快速构建 TiDB 集群
本文档介绍如何在单机上通过 Docker Compose 快速一键部署一套 TiDB 测试集群.Docker Compose 可以通过一个 YAML 文件定义多个容器的应用服务,然后一键启动或停止. ...
- 部署TiDB集群
架构图 节点规划 120.52.146.213 Control Machine 120.52.146.214 PD1_TiDB1 120.52.146.215 PD2_TiDB2 120.52.146 ...
- tidb集群
tidb ansible部署 https://zhuanlan.zhihu.com/p/27308307?refer=newsql 网址:http://www.cnblogs.com/mowei/p/ ...
随机推荐
- .net core WebApi Interlocked配合ManualResetEventSlim实现并发同步
由于项目有某种需求,在WebApi中,有大量的请求需要操作相同的数据,因此需要用到并发同步机制去操作共享的数据. 本次配合使用Interlocked和ManualResetEventSlim来实现并发 ...
- Visual Basic 2017 操作Excel和word【1】持续更新……
我坚持在VB的路上走到黑………… 清单1.1 从应用程序对象导航到Excel中的工作表 Dim myWorkbooks As Excel.Workbooks = app.Workbooks ) ...
- python异常处理机制
python有五种异常处理机制,分别是 1.默认异常处理器. 如果我们没有对异常进行任何预防,那么程序在执行过程中发生异常就会中断程序,调用python默认的异常处理器,并在终端输出异常信息,如图所示 ...
- 添加网络打印机的步骤(xp和win2008+win7)
1.如题,设置好打印机的 ip地址和子网掩码等信息. 2 .xp不像其他新的系统那么好用那么智能...只能慢慢来 如果是xp,注意,请添加网络打印机的时候选 :添加本地打印机,,记得哦 然后如图 然 ...
- golang结构体、接口、反射
struct结构体 struct用来自定义复杂数据结构,可以包含多个字段属性,可以嵌套; go中的struct类型理解为类,可以定义方法,和函数定义有些许区别; struct类型是值类型. struc ...
- python自学第12天 模块定义,导入,内置模块
1.定义模块:用来从逻辑上组织python代码(实现一个功能),本质是.py结尾的python 包:本质就是一个目录(必须带有一个_init_.py文件)2.导入方法import module_nam ...
- php中wampserver多站点配置
1.修改默认端口 : 2.添加多站点: 3.在文件的结尾添加一个站点配置: <VirtualHost *:8080> ServerAdmin webmaster@duoduo.com Do ...
- Python 基于时间的进程通信
import time from multiprocessing import Process,Event def f1(e): time.sleep(2) n = 100 print("子 ...
- 剑指Offer 57. 二叉树的下一个结点 (二叉树)
题目描述 给定一个二叉树和其中的一个结点,请找出中序遍历顺序的下一个结点并且返回.注意,树中的结点不仅包含左右子结点,同时包含指向父结点的指针. 题目地址 https://www.nowcoder.c ...
- 04_安装Nginx图片服务器
一.安装Nginx 先安装Nginx,看我之前发的文章: 搭建Nginx服务器 二.安装vsftpd 再安装vsftpd组件,看我之前发的文章: Linux安装ftp组件 三.开始搭建Nginx图片服 ...