Redis 数据结构的实现
Redis 数据结构的实现
先看个对照关系:
| Redis数据结构 | 实现一 | 实现二 |
| string | 整数(如果value能够表示为整数) | 字符串 |
| hash | 压缩列表(只包含少量键值对, 并且每个键值对的键和值要么就是小整数值, 要么就是长度比较短的字符串) | 字典 |
| list | 压缩列表(只包含少量列表项, 并且每个列表项要么就是小整数值, 要么就是长度比较短的字符串) | 双端链表 |
| set | 整数集合(当一个集合只包含整数值元素, 并且这个集合的元素数量不多时) | 字典 |
| sorted set | 压缩列表 | 跳表 |
再讨论每种数据结构的实现原理:
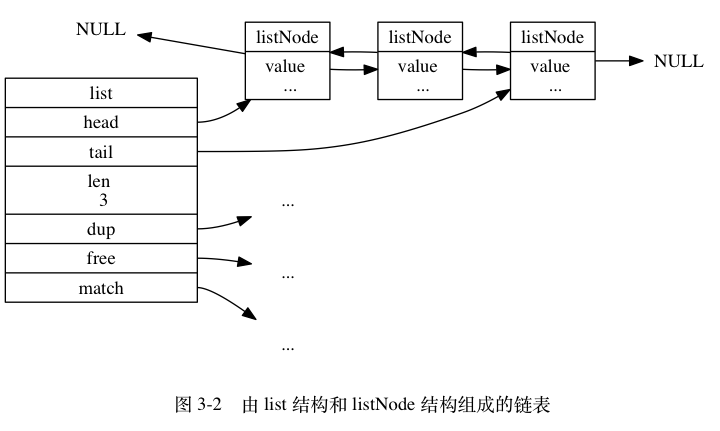
双端链表
实现如下:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
} list;
字典(dictionay)
Redis 的字典使用哈希表作为底层实现,
哈希表的实现如下:
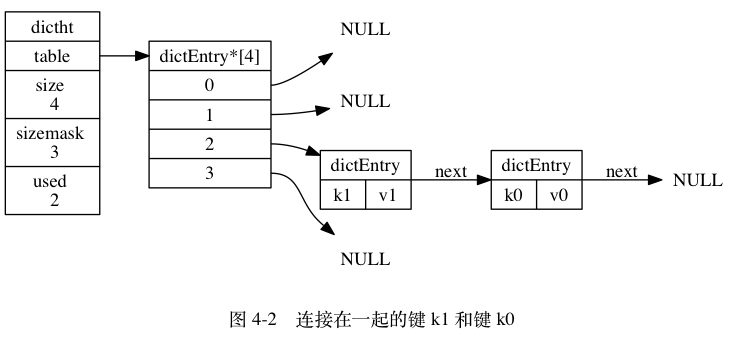
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
字典的实现:
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表,一般情况下只使用ht[0],rehash才使用ht[1]
dictht ht[];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
扩张和收缩(rehash)
随着操作的不断执行, 哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的负载因子(load factor)维持在一个合理的范围之内, 当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。
rehash步骤:
- 为字典的
ht[1]哈希表分配空间, 这个哈希表的空间大小取决于要执行的操作, 以及ht[0]当前包含的键值对数量 (也即是ht[0].used属性的值):- 如果执行的是扩展操作, 那么
ht[1]的大小为第一个大于等于ht[0].used * 2的 2^n (2的n次方幂); - 如果执行的是收缩操作, 那么
ht[1]的大小为第一个大于等于ht[0].used的 2^n 。
- 如果执行的是扩展操作, 那么
- 将保存在
ht[0]中的所有键值对 rehash 到ht[1]上面: rehash 指的是重新计算键的哈希值和索引值, 然后将键值对放置到ht[1]哈希表的指定位置上。 - 当
ht[0]包含的所有键值对都迁移到了ht[1]之后 (ht[0]变为空表), 释放ht[0], 将ht[1]设置为ht[0], 并在ht[1]新创建一个空白哈希表, 为下一次 rehash 做准备。
当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于
1; - 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于
5;
其中哈希表的负载因子可以通过公式:
# 负载因子 = 哈希表已保存节点数量 / 哈希表大小
load_factor = ht[].used / ht[].size
根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行, 服务器执行扩展操作所需的负载因子并不相同, 这是因为在执行 BGSAVE命令或 BGREWRITEAOF 命令的过程中, Redis 需要创建当前服务器进程的子进程, 而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率, 所以在子进程存在期间, 服务器会提高执行扩展操作所需的负载因子, 从而尽可能地避免在子进程存在期间进行哈希表扩展操作, 这可以避免不必要的内存写入操作, 最大限度地节约内存。
另一方面, 当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作。
为了避免 rehash 对服务器性能造成影响, 服务器不是一次性将 ht[0] 里面的所有键值对全部 rehash 到 ht[1] , 而是分多次、渐进式地将 ht[0] 里面的键值对慢慢地 rehash到 ht[1] 。以下是哈希表渐进式 rehash 的详细步骤:
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0]里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
整数集合(intset)
整数集合是用一个有序数组实现的,
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组, 但实际上 contents 数组的真正类型取决于 encoding 属性的值:
- 如果
encoding属性的值为INTSET_ENC_INT16, 那么contents就是一个int16_t类型的数组, 数组里的每个项都是一个int16_t类型的整数值 (最小值为-32,768,最大值为32,767)。 - 如果
encoding属性的值为INTSET_ENC_INT32, 那么contents就是一个int32_t类型的数组, 数组里的每个项都是一个int32_t类型的整数值 (最小值为-2,147,483,648,最大值为2,147,483,647)。 - 如果
encoding属性的值为INTSET_ENC_INT64, 那么contents就是一个int64_t类型的数组, 数组里的每个项都是一个int64_t类型的整数值 (最小值为-9,223,372,036,854,775,808,最大值为9,223,372,036,854,775,807)。
升级(upgrade)
intset 的升级操作:例如当向一个底层为 int16_t 数组的整数集合添加一个 int64_t 类型的整数值时, intset 已有的所有元素都会被转换成 int64_t 类型。
升级整数集合并添加新元素共分为三步进行:
- 根据新元素的类型, 扩展整数集合底层数组的空间大小, 并为新元素分配空间。
- 将底层数组现有的所有元素都转换成与新元素相同的类型, 并将类型转换后的元素放置到正确的位上, 而且在放置元素的过程中, 需要继续维持底层数组的有序性质不变。
- 将新元素添加到底层数组里面。
升级之后新元素的摆放位置
因为引发升级的新元素的长度总是比整数集合现有所有元素的长度都大, 所以这个新元素的值要么就大于所有现有元素, 要么就小于所有现有元素:
- 在新元素小于所有现有元素的情况下, 新元素会被放置在底层数组的最开头(索引
0); - 在新元素大于所有现有元素的情况下, 新元素会被放置在底层数组的最末尾(索引
length-1)。
注意:intset不支持降级!
跳表(skiplist)
数据结构定义如下:
typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
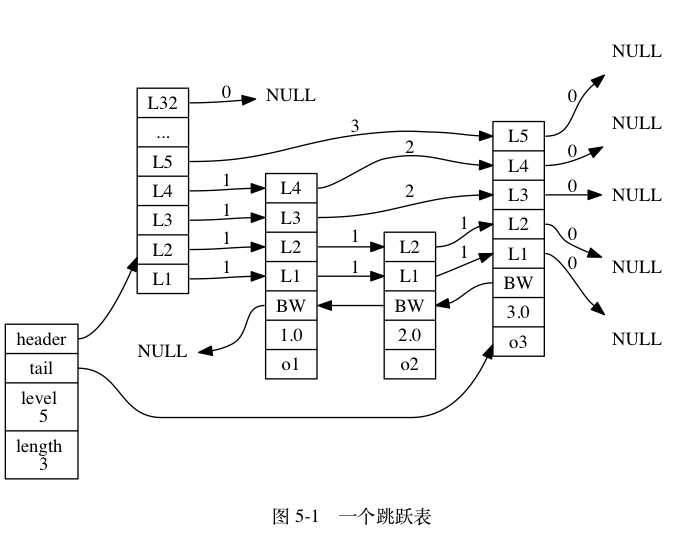
上图展示了一个跳跃表示例, 位于图片最左边的是 zskiplist 结构, 该结构包含以下属性:
header:指向跳跃表的表头节点。tail:指向跳跃表的表尾节点。level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。
位于 zskiplist 结构右方的是四个 zskiplistNode 结构, 该结构包含以下属性:
- 层(level):节点中用
L1、L2、L3等字样标记节点的各个层,L1代表第一层,L2代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。 - 后退(backward)指针:节点中用
BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。 - 分值(score):各个节点中的
1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。 - 成员对象(obj):各个节点中的
o1、o2和o3是节点所保存的成员对象。
压缩列表(ziplist)
ziplist是由若干个entry 组成,每个entry可以保存一个字节数组或者一个整数值。
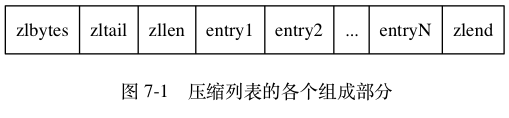
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
zlbytes |
uint32_t |
4 |
记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配, 或者计算 zlend的位置时使用。 |
zltail |
uint32_t |
4 |
记录压缩列表表尾节点距离压缩列表的起始地址有多少字节: 通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址。 |
zllen |
uint16_t |
2 |
记录了压缩列表包含的节点数量: 当这个属性的值小于 UINT16_MAX (65535)时, 这个属性的值就是压缩列表包含节点的数量; 当这个值等于 UINT16_MAX 时, 节点的真实数量需要遍历整个压缩列表才能计算得出。 |
entryX |
列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
zlend |
uint8_t |
1 |
特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
entry
entry可以保存一个字节数组或者一个整数值, 其中, 字节数组可以是以下三种长度的其中一种:
- 长度小于等于
63(2^{6}-1)字节的字节数组; - 长度小于等于
16383(2^{14}-1) 字节的字节数组; - 长度小于等于
4294967295(2^{32}-1)字节的字节数组;
而整数值则可以是以下六种长度的其中一种:
4位长,介于0至12之间的无符号整数;1字节长的有符号整数;3字节长的有符号整数;int16_t类型整数;int32_t类型整数;int64_t类型整数。
每个压缩列表entry都由 previous_entry_length 、 encoding 、 content 三个部分组成,

| 属性 | 类型 | 长度 | 用途 |
| previous_entry_length | 整型 | 1(小于254)或5(大于或等于254) | 前一个entry的长度 |
| encoding | 整型 | 记录content的类型和长度 | |
| content | 整数或字节数组 | entry的值 |
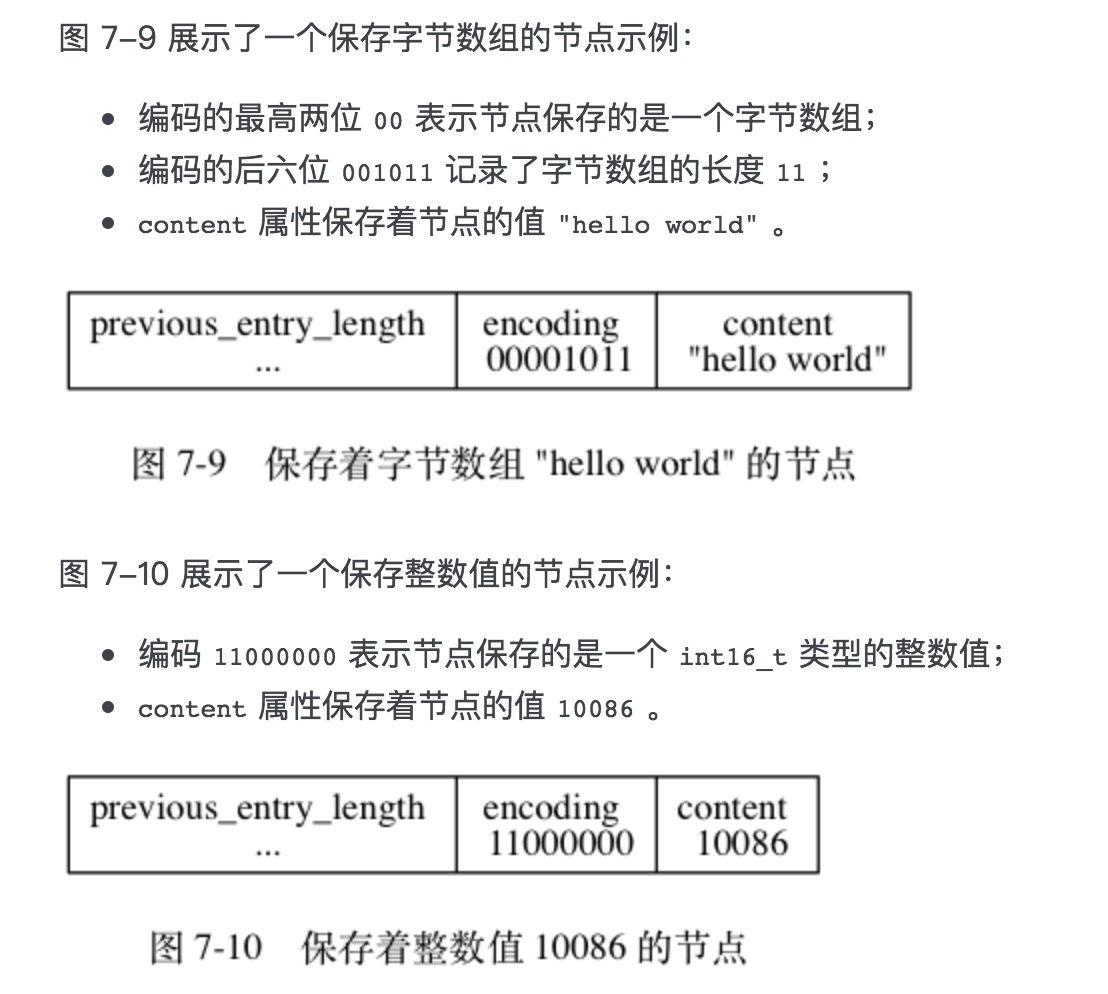
连锁更新(cascade update)
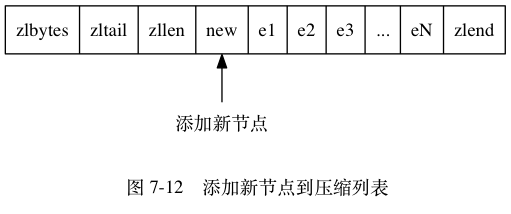
现在, 考虑这样一种情况: 在一个压缩列表中, 有多个连续的、长度介于 250 字节到 253 字节之间的节点 e1 至 eN ,如下图:

因为 e1 至 eN 的所有节点的长度都小于 254 字节, 所以记录这些节点的长度只需要 1 字节长的 previous_entry_length 属性, 换句话说, e1 至 eN 的所有节点的 previous_entry_length 属性都是 1 字节长的。
这时, 如果我们将一个长度大于等于 254 字节的新节点 new 设置为压缩列表的表头节点, 那么 new 将成为 e1 的前置节点, 如图
因为 e1 的 previous_entry_length 属性仅长 1 字节, 它没办法保存新节点 new 的长度, 所以程序将对压缩列表执行空间重分配操作, 并将 e1 节点的 previous_entry_length 属性从原来的 1 字节长扩展为 5 字节长。
现在, 麻烦的事情来了 —— e1 原本的长度介于 250 字节至 253 字节之间, 在为 previous_entry_length 属性新增四个字节的空间之后,e1 的长度就变成了介于 254 字节至 257 字节之间, 而这种长度使用 1 字节长的 previous_entry_length 属性是没办法保存的。
因此, 为了让 e2 的 previous_entry_length 属性可以记录下 e1 的长度, 程序需要再次对压缩列表执行空间重分配操作, 并将 e2 节点的 previous_entry_length 属性从原来的 1 字节长扩展为 5 字节长。
正如扩展 e1 引发了对 e2 的扩展一样, 扩展 e2 也会引发对 e3 的扩展, 而扩展 e3 又会引发对 e4 的扩展……为了让每个节点的 previous_entry_length 属性都符合压缩列表对节点的要求, 程序需要不断地对压缩列表执行空间重分配操作, 直到 eN 为止。
Redis 将这种在特殊情况下产生的连续多次空间扩展操作称之为“连锁更新”。
除了添加新节点可能会引发连锁更新之外, 删除节点也可能会引发连锁更新。
因为连锁更新在最坏情况下需要对压缩列表执行 N 次空间重分配操作, 而每次空间重分配的最坏复杂度为 O(N) , 所以连锁更新的最坏复杂度为 O(N^2) 。
参考文档:
http://redisbook.com/
Redis 数据结构的实现的更多相关文章
- Redis 数据结构使用场景
转自http://get.ftqq.com/523.get 一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的 ...
- Redis数据结构
Redis数据结构 Redis数据结构详解(一) 前言 Redis和Memcached最大的区别,Redis 除啦支持数据持久化之外,还支持更多的数据类型而不仅仅是简单key-value结构的数据 ...
- Redis数据结构底层知识总结
Redis数据结构底层总结 本篇文章是基于作者黄建宏写的书Redis设计与实现而做的笔记 数据结构与对象 Redis中数据结构的底层实现包括以下对象: 对象 解释 简单动态字符串 字符串的底层实现 链 ...
- Redis 数据结构与内存管理策略(上)
Redis 数据结构与内存管理策略(上) 标签: Redis Redis数据结构 Redis内存管理策略 Redis数据类型 Redis类型映射 Redis 数据类型特点与使用场景 String.Li ...
- Redis 数据结构与内存管理策略(下)
Redis 数据结构与内存管理策略(下) 标签: Redis Redis数据结构 Redis内存管理策略 Redis数据类型 Redis类型映射 Redis 数据类型特点与使用场景 String.Li ...
- Redis数据结构之intset
本文及后续文章,Redis版本均是v3.2.8 上篇文章<Redis数据结构之robj>,我们说到redis object数据结构,其有5中数据类型:OBJ_STRING,OBJ_LIST ...
- Redis数据结构之robj
本文及后续文章,Redis版本均是v3.2.8 我们知道一个database内的这个映射关系是用一个dict来维护的.dict的key固定用一种数据结构来表达,这这数据结构就是动态字符串sds.而va ...
- Redis 数据结构之dict(2)
本文及后续文章,Redis版本均是v3.2.8 上篇文章<Redis 数据结构之dict>,我们对dict的结构有了大致的印象.此篇文章对dict是如何维护数据结构的做个详细的理解. 老规 ...
- Redis 数据结构之dict
上篇文章<Redis数据结构概述>中,了解了常用数据结构.我们知道Redis以高效的方式实现了多种数据结构,因此把Redis看做为数据结构服务器也未尝不可.研究Redis的数据结构和正确. ...
- Redis数据结构以及应用场景
1. Redis数据结构以及应用场景 1.1. Memcache VS Redis 1.1.1. 选Memcache理由 系统业务以KV的缓存为主,数据量.并发业务量大,memcache较为合适 me ...
随机推荐
- python网络编程(九)
单进程服务器-非堵塞模式 服务器 #coding=utf-8 from socket import * import time # 用来存储所有的新链接的socket g_socketList = [ ...
- C++程序设计方法4:类模板
类模板 在定义类时也可以将一些类型抽象出来,用模板参数来替换,从而使类更具有通用性.这种类被称为模板类,例如: template <typename T> class A { T data ...
- yii2 advanced版基础部分
yii2 advanced版 一.目录结构 1.backend 和 frontend : 前后台入口,相当于是一个单独的Basic应用,有自己的 mvc 目录.配置文件目录.入口文件目录 2.cons ...
- 3ds max 学习笔记(四)--创建物体
添加物体: 1.初创建物体,从单视图进行创建,便于处于同一平面,在透视图观看效果.2.在基本对象处选择“长方体”:左键开始制作,松开左键此时控制的是长方形的高,然后点击左键完成:注:在max里点击右键 ...
- javascript中的常用表单事件用法
下面介绍几种javascript中常用的表单事件: 一,onsubmit:表单中的确认按钮被点击时发生的事件,如下案例. 案例解析:弹出表单中提交的内容 <form name="tes ...
- asp.net mvc ViewData 和 ViewBag区别,TempData
ViewData 和 ViewBag都是页面级别的生命周期,TempData--Passing data between the current and next HTTP requests Temp ...
- 导出使用NPOI
调用: DataTable table = new DataTable(); #region 创建 datatable table.Columns.Add(new DataColumn("账 ...
- fixed和sticky
<!DOCTYPE html><html> <head> <meta charset="utf-8"> <title>f ...
- CSS魔法堂:Transition就这么好玩
前言 以前说起前端动画必须使用JS,而CSS3为我们带来transition和@keyframes,让我们可以以更简单(声明式代替命令式)和更高效的方式实现UI状态间的补间动画.本文为近期对Tran ...
- 调用 LoadLibraryEx 失败,在 ISAPI 筛选器 "C:\Windows\Microsoft.NET\Framework\v4.0.30319\\aspnet_filter.dll" 上
开始 -> 运行 -> inetmgr -> 应用程序池 -> 找到 我的网站对象的 程序池 -> 右键 -> 高级设置 -> 启用32位应用程序 由 fal ...