Tensorflow Seq2seq attention decode解析
tensorflow基于 Grammar as a Foreign Language实现,这篇论文给出的公式也比较清楚。
这里关注seq2seq.attention_decode函数,
- 主要输入
decoder_inputs,
initial_state,
attention_states,
这里可以主要参考 models/textsum的应用,textsum采用的多层双向lstm,
假设只有一层,texsum将正向
最后输出的state作为 attention_decode的输入initial_state
(不过很多论文认为用逆向最后的state可能效果更好)
对应decocer_inputs就是标注的摘要的字符序列id对应查找到的embedding序列
而attention_states是正向负向输出concatenate的所有outputs(hidden注意output和hidden是等同概念)
- 关于linear
首先注意到在attention_decode函数用到了一个linear这个定义在rnn_cell._linear函数
他的输入是
一个list 可能的输入是比如
[ [batch_size, lenght1], [batch_size_length2]]
对应一个list 2个数组
它的作用是内部定义一个数组
对应这个例子 [length1 + length2, output_size]
也就是起到将[batch_size, length1][batch_size, length2]的序列输入映射到 [batch_size, output_size]的输出
这个在attention机制最后会遇到
先看attention的公式
将encoder的hidden states表示为
(h 1 , . . . , h T A)
将decoder的hidden states表示为
(d 1 , . . . , d T B) :=
(h T A +1 , . . . , h T A +T B).

这里最后计算得到的
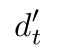
就是attention的结果
对应一个样本
就是长度为 atten_size的向量(就是所有attention输入向量按照第三个公式的线性叠加之后的结果)那么对应batch_size的输入
就是[batch_size, atten_size]的一个结果。
论文中提到后面会用到这个attention,
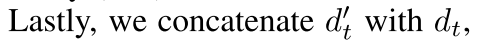
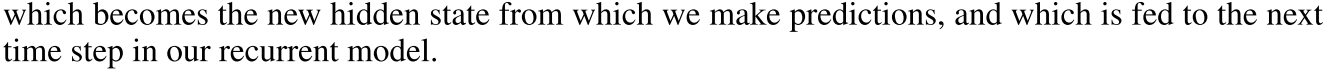
也就是说会concat attention的结果和原始hidden state的结果,那么如何使用呢,tf的做法
x = linear([inp] + attns, input_size, True)
# Run the RNN.
cell_output, state = cell(x, state)
就是说 inp是 [batch_size, input_size], attns [batch_size, attn_size] linear的输入对应 input_size
即在linear内部经过input和attns concate之后输出[batch_size, input_size]使得能够x作为输入继续进行rnn过程
- attention公式
继续看attention公式
,不要考虑batch_size就是按照一个样本来考虑第一个公式
对应3个举止 W1,W2都是[attn_size, atten_size]的正方形矩阵,h,d对应 [attent_size, 1]的向量v对应[atten_size, 1]的矩阵,
那么就是线性叠加之后做非线性变化tanh([attn_size, 1])->[attn_size, 1]最后和v做dot得到一个数值
表示u(i,t)即对应第i个attention向量在decode的t时刻时候应该的权重大小,
第二个公式表示使用softmax做归一化得到权重向量概率大小。
第三个公式上面已经分析。
- tensorflow中attention的实现
- 步骤1
这里第一个问题是我们按照batch操作所以对应处理的不是一个样本而是一批batch_size个样本。
那么上面的操作就不能按照tf.matmul来执行了,因为[batch_size, x, y][y, 1]这样相乘是不行的
tf的做法是使用1by1 convolution来完成,主要利用1by1 + num_channels + num_filters
关于conv2d的使用特别是配合1by1,num_channels, num_filters 这里解释的非常清楚
http://stackoverflow.com/questions/34619177/what-does-tf-nn-conv2d-do-in-tensorflow
# To calculate W1 * h_t we use a 1-by-1 convolution, need to reshape before.
hidden = array_ops.reshape(
attention_states, [-1, attn_length, 1, attn_size])
hidden_features = []
v = []
attention_vec_size = attn_size # Size of query vectors for attention.
for a in xrange(num_heads):
k = variable_scope.get_variable("AttnW_%d" % a,
[1, 1, attn_size, attention_vec_size])
hidden_features.append(nn_ops.conv2d(hidden, k, [1, 1, 1, 1], "SAME"))
v.append(
variable_scope.get_variable("AttnV_%d" % a, [attention_vec_size]))
atention_vec_szie == attn_size
attn_size 对应 num_channels (num_channels个位置相乘加和 dot)
attention_vec_size 对应 num_filters
刚好这个conv2d的对应就是batch_size版本的attention的第一个公式里面的
W1 * h_t
Conv2d输出[batch_size, atten_length, 1, attention_vec_size]
- def attention(query)的分析
attention(query)的输入是rnn上一步输出的state
输出 attns = attention(state)对应 [batch_size, attn_size]的矩阵
对应当前步骤需要用到的attention
def
attention(query):
"""Put attention masks on hidden using hidden_features and query."""
ds = [] # Results of attention reads will be stored here.
if nest.is_sequence(query): # If the query is a tuple, flatten it.
query_list = nest.flatten(query)
for q in query_list: # Check that ndims == 2 if specified.
ndims = q.get_shape().ndims
if ndims:
assert ndims == 2
query = array_ops.concat(1, query_list)
for a in xrange(num_heads):
with variable_scope.variable_scope("Attention_%d" % a):
y = linear(query, attention_vec_size, True)
y = array_ops.reshape(y, [-1, 1, 1, attention_vec_size])
# Attention mask is a softmax of v^T * tanh(...).
s = math_ops.reduce_sum(
v[a] * math_ops.tanh(hidden_features[a] + y), [2, 3])
a = nn_ops.softmax(s)
# Now calculate the attention-weighted vector d.
d = math_ops.reduce_sum(
array_ops.reshape(a, [-1, attn_length, 1, 1]) * hidden,
[1, 2])
ds.append(array_ops.reshape(d, [-1, attn_size]))
return ds
首先目前默认都是用state_is_tuple=True选项(这样效率更高,后面state_is_tupe=False将会depreciated)
前面已经说过tf实现的state对应两个(cell_state, hidden_state)
所以这里nest_issequence是True 对应最后处理后query 就是 [batch_size, 2 * input_size]
y = linear(query, attention_vec_size, True)
y = array_ops.reshape(y, [-1, 1, 1, attention_vec_size])
对应W2dt的计算
hidden_features[a] + y 则注意是 W2dt累加到
所有的hi(attn_length个)
a对应[batdh_size, attn_length]
Reshape[batch_size, atten_length, 1, 1]
Hidden [batch_size, atten_length, 1, atten_size]
最终返回 [batch_size, attn_size]
Tensorflow Seq2seq attention decode解析的更多相关文章
- 学习笔记CB014:TensorFlow seq2seq模型步步进阶
神经网络.<Make Your Own Neural Network>,用非常通俗易懂描述讲解人工神经网络原理用代码实现,试验效果非常好. 循环神经网络和LSTM.Christopher ...
- seq2seq attention
1.seq2seq:分为encoder和decoder a.在decoder中,第一时刻输入的是上encoder最后一时刻的状态,如果用了双向的rnn,那么一般使用逆序的最后一个时刻的输出(网上说实验 ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- DL4NLP —— seq2seq+attention机制的应用:文档自动摘要(Automatic Text Summarization)
两周以前读了些文档自动摘要的论文,并针对其中两篇( [2] 和 [3] )做了presentation.下面把相关内容简单整理一下. 文本自动摘要(Automatic Text Summarizati ...
- ChatGirl 一个基于 TensorFlow Seq2Seq 模型的聊天机器人[中文文档]
ChatGirl 一个基于 TensorFlow Seq2Seq 模型的聊天机器人[中文文档] 简介 简单地说就是该有的都有了,但是总体跑起来效果还不好. 还在开发中,它工作的效果还不好.但是你可以直 ...
- ChatGirl is an AI ChatBot based on TensorFlow Seq2Seq Model
Introduction [Under developing,it is not working well yet.But you can just train,and run it.] ChatGi ...
- Tensorflow的CNN教程解析
之前的博客我们已经对RNN模型有了个粗略的了解.作为一个时序性模型,RNN的强大不需要我在这里重复了.今天,让我们来看看除了RNN外另一个特殊的,同时也是广为人知的强大的神经网络模型,即CNN模型.今 ...
- tensorflow seq2seq.py接口实例
以简单英文问答问题为例测试tensorflow1.4 tf.contrib.legacy_seq2seq中seq2seq文件的几个seq2seq接口 github:https://github.com ...
- seq2seq+attention解读
1什么是注意力机制? Attention是一种用于提升Encoder + Decoder模型的效果的机制. 2.Attention Mechanism原理 要介绍Attention Mechanism ...
随机推荐
- PAT Basic 1020
1020 月饼 (25 分) 月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼.现给定所有种类月饼的库存量.总售价.以及市场的最大需求量,请你计算可以获得的最大收益是多少. 注意 ...
- numpy中的广播机制
广播的引出 numpy两个数组的相加.相减以及相乘都是对应元素之间的操作. import numpy as np x = np.array([[2,2,3],[1,2,3]]) y = np.arra ...
- C_狐狸和兔子的故事
题目描述 围绕着山顶有10个洞,一只狐狸和一只兔子各住一个洞.狐狸总想吃掉兔子.一天兔子对狐狸说:“你想吃我有一个条件,先把洞从1-10编上号,你从10号洞出发,先到1号洞找我:第二次隔1个洞找我,第 ...
- django的templatetags
创建tag方式,首先在需要使用tag的app下创建一个templatetags的python包, 然后在包里创建一个tag模块,例如hellotag.py from django import tem ...
- es6学习笔记二:生成器 Generators
今天这篇文章让我感到非常的兴奋,接下来我们将一起领略ES6中最具魔力的特性. 为什么说是“最具魔力的”?对于初学者来说,此特性与JS之前已有的特性截然不同,可能会觉得有点晦涩难懂.但是,从某种意义上来 ...
- SpringMVC Controller之间的重定向和转发
同一个controller之间重定向和转发 ①redirect 在Controller的映射方法中,其返回值改为:return "redirect:XXX"; ②forward 这 ...
- Wpf 之Canvas介绍
从这篇文章开始是对WPF中的界面如何布局做一个较简单的介绍,大家都知道:UI是做好一个软件很重要的因素,如果没有一个漂亮的UI,功能做的再好也无法吸引很多用户使用,而且没有漂亮的界面,那么普通用户会感 ...
- 透明Panel
unit TransparentPanel; interface uses Winapi.Windows, Winapi.Messages, System.SysUtils, System.Varia ...
- 加速Android Studio编译速度
一.修改运行内存 进入项目,菜单栏-help-Edit Custom VM Option Paste_Image.png 添加或修改为: -Xms2048m -Xmx2048m -XX:MaxPe ...
- CSS魔法堂:一起玩透伪元素和Content属性
前言 继上篇<CSS魔法堂:稍稍深入伪类选择器>记录完伪类后,我自然而然要向伪元素伸出"魔掌"的啦^_^.本文讲讲述伪元素以及功能强大的Contet属性,让我们可以通 ...