Redis使用规范
突出强调部分
- 【强制】key名不要包含特殊字符,如空格、换行、单双引号以及其他转义字符
- 【强制】拒绝bigkey(防止网卡流量、慢查询)
- 【强制】控制key的生命周期,redis不是垃圾桶
- 【强制】技术设计上避免热点key
- 【强制】禁止线上使用keys、flushall、flushdb、CONFIG等
- 【强烈建议】选择适合的数据类型
- 【强烈建议】使用批量操作提高效率,但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。如果用pipeline,也注意批次下key数量限制在500以内
- 【强烈建议】 O(N)命令关注N的数量。例如hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确N的值。有遍历的需求可以使用hscan、sscan、zscan代替
- 【强烈建议】避免多个应用使用一个Redis实例。正例:不相干的业务拆分,公共数据做服务化
- 【强烈建议】redis使用定位提前确认:技术评审确认redis是定位为存储,还是cache
一、键值设计
- key名设计
(1)【建议】: 可读性和可管理性
以业务名(或数据库名)为前缀(防止key冲突),用冒号分隔,比如业务名:表名:id

(2)【建议】:简洁性
保证语义的前提下,控制key的长度,当key较多时,内存占用也不容忽视,例如:

- (3)【强制】:不要包含特殊字符。 如空格、换行、单双引号以及其他转义字符
- value设计
- (1)【强制】:拒绝bigkey(防止网卡流量、慢查询)
a.string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。反例:一个包含200万个元素的list。
b.非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞,而且该操作不会出现在慢查询中(latency可查))
解释:由于redis单线程运行的机制,一个操作阻塞主线程,会导致该时间段内所有请求都堆积在tcp buffer中,得不到及时的处理。如果较多大kv在短时间内密集的执行删除或其他耗时操作,会导致该redis响应时间明显升高,甚至超时;在kv较大情况下,qps承压能力受网卡上限影响,同时大量数据在内存与网卡驱动之间进行复制,对cpu也有较大的消耗;对于大key写请求,主要的压力在于主从复制使用的出口带宽,主节点下面带的从节点越多,出口带宽消耗越严重,同时主节点cpu消耗也越严重。 - (2)【强烈建议】:选择适合的数据类型。
例如:
a.实体类型(要合理控制和使用数据结构内存编码优化配置,例如ziplist,但也要注意节省内存和性能之间的平衡)
反例:

正例:

b.典型的优化case是:1个大json存一个大string,只关注json中某一个或某几个属性的读,也要读取全部string;只修改json中一个属性,也要将整个string重新覆盖写。优化成hash后,可大大降低对网卡、cpu、内存容量的压力,同时当hash key个数较少(512内),value不是很大(64字节),可以进行压缩,降低redis自身的数据结构开销。
c.尽量避免key value中重复的内容,比如key使用id进行索引话,value中就可以不必再存放id字段。
- 3.【强制】:控制key的生命周期,redis不是垃圾桶。
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期),不过期的数据重点关注idletime。不建议在redis中存放1天以上不访问的数据,冷数据须考虑设置过期时间或使用db方式存储
解释:redis作为全内存数据库,使用其第一目的就是用成本换性能,内存存储成本比ssd及hdd都要高很多,典型的服务器有128G内存,若算上持久化对内存的额外消耗,常规情况下只能提供约80G的使用容量,因此对redis的存储空间要格外的珍惜,设计上如果允许一个key进入内存长时间不使用,不做缓存超时,就会造成资源上的浪费。 - 4.【强制】:技术设计上避免热点key,并且提供离线和实时分析工具。
二、命令使用
1.【强烈建议】 O(N)命令关注N的数量。例如hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确N的值。有遍历的需求可以使用hscan、sscan、zscan代替。
2.【强制】:禁用命令
禁止线上使用keys、flushall、flushdb、CONFIG等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。计划在公共基础库上禁止使用
3.【建议】合理使用select
redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线程处理,会有干扰。
4.【强烈建议】使用批量操作提高效率,但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。如果用pipeline,也注意批次下key数量限制在500以内

注意两者不同:

解释:mset、mget、del的多key操作,对于proxy会有额外的cpu消耗。这三种特殊的操作,在后端做多分片时,proxy需要将每个操作中的一批key按照后端分配规则,重组成n批key的组合,n等于分片数量,然后分别将重组后的n个多key操作分片发给后端每一个分片;回复消息时,也需要等待所有请求从后端回复回来,在proxy层进行结果merge,再返回给上层。因此这种操作在key数量上升时,对proxy的cpu会造成额外的压力,因此强烈建议控制批量操作的key数量,以及减少mset、mget、del等多key操作。对于一定要使用此种操作的服务,建议服务上线前根据自己的请求特点进行单独压测。一个pipline类型请求内容过多时,一次性达到redis-proxy时,会导致proxy申请内存数量暴涨,导致挤占同一物理机上混布的其他服务的资源,严重时会导致服务器重启。因此pipline类型请求需要严格限制单批次内的请求量。
5.【建议】Redis事务功能较弱,不建议过多使用
Redis的事务功能较弱(不支持回滚),而且集群版本(自研和官方)要求一次事务操作的key必须在一个slot上(可以使用hashtag功能解决)
6.【建议】Redis集群版本在使用Lua上有特殊要求:
- 1.所有key都应该由 KEYS 数组来传递,redis.call/pcall 里面调用的redis命令,key的位置,必须是KEYS array, 否则直接返回error,"-ERR bad lua script for redis cluster, all the keys that the script uses should be passed using the KEYS arrayrn"
- 2.所有key,必须在1个slot上,否则直接返回error, "-ERR eval/evalsha command keys must in same slotrn"
7.【建议】必要情况下使用monitor命令时,要注意不要长时间使用。
8.【强烈建议】数据预热:若一个业务流程需要多次读取redis中相同内容,建议流程起始点一次读取,多次使用,尽量减少与redis交互,减轻后端压力
三、客户端使用
1.【强烈建议】避免多个应用使用一个Redis实例。正例:不相干的业务拆分,公共数据做服务化。
2.【建议】
使用带有连接池的数据库,可以有效控制连接,同时提高效率,标准使用方式:
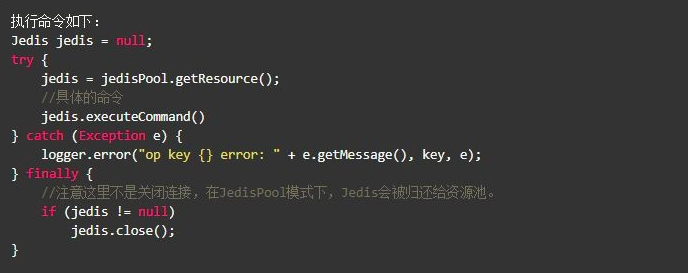
3.【建议】
高并发下建议客户端添加熔断功能(例如netflix hystrix)
4.【建议】
设置合理的密码,如有必要可以使用SSL加密访问
5.【建议】
根据自身业务类型,选好maxmemory-policy(最大内存淘汰策略),设置好过期时间。
默认策略是volatile-lru,即超过最大内存后,在过期键中使用lru算法进行key的剔除,保证不过期数据不被删除,但是可能会出现OOM问题。
其他策略如下:
- allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
- allkeys-random:随机删除所有键,直到腾出足够空间为止。
- volatile-random:随机删除过期键,直到腾出足够空间为止。
- volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略。
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error) OOM command not allowed when used memory",此时Redis只响应读操作。
四、相关工具
1.【建议】:数据同步
redis间数据同步可以使用:redis-port
2.【建议】:big key搜索
redis大key搜索工具
3.【建议】:热点key寻找(内部实现使用monitor,所以建议短时间使用)
facebook的redis-faina
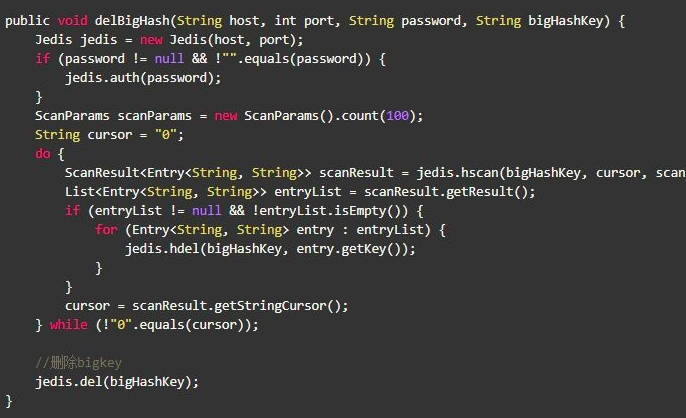
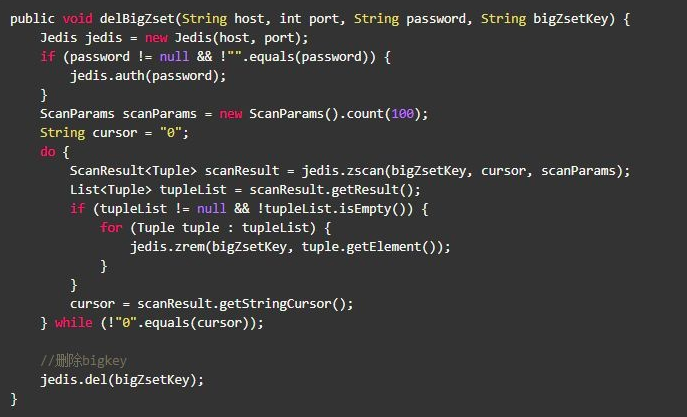
五 删除bigkey

Hash删除: hscan + hdel
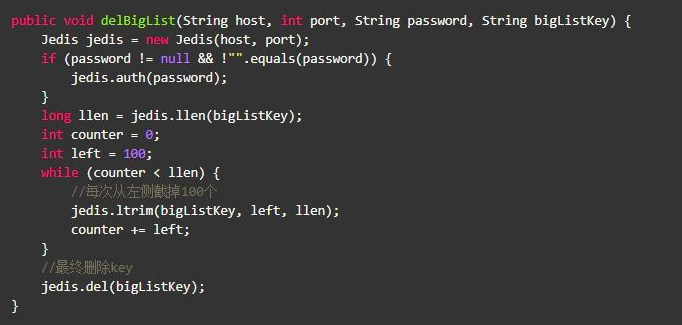
List删除: ltrim
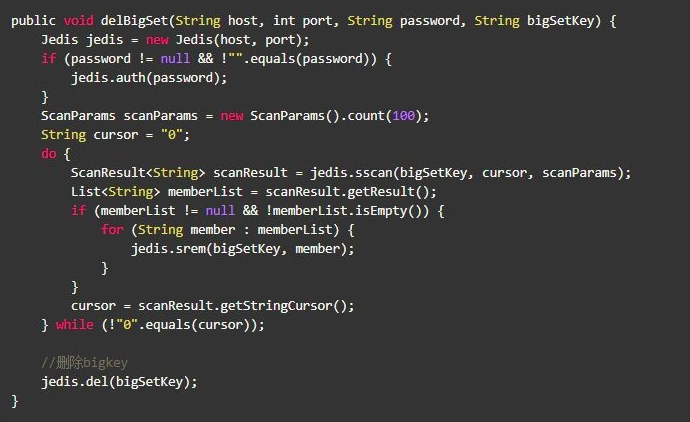
Set删除: sscan + srem
SortedSet删除: zscan + zrem
六、落实方式
1.加入研运技术评审check环节,检查redis的使用
2.加入codereview环节,check下redis的使用技术方案是否合理
3.离线和实时的监控报警完善,需要出人力持续优化
七、问题讨论
1.排行榜场景大key问题
- 如有活动排行榜功能,100w参加,每个人都需要知道自己的排名;zset 如业务必须超过5000的,可以设置不过期,手动删除元素,最后删除key, 禁止直接删key
- 这种大key方案是否短期内可以折衷接受,或者有更智能化的处理策略
- 是否考虑下做通用的排行榜服务了,应对通用排行榜需求,而不是目前的简单粗暴的大key方案
2.redis使用定位问题:redis是定位为存储,还是cache。这个需要上线前考虑清楚。 两种场景配置,lru策略都不一样。
- 技术评审需要提前确认定位;
- 需要替代方案,性能接近redis成本低的存储方案;
Redis使用规范的更多相关文章
- 完整阿里云Redis开发规范
完整阿里云Redis开发规范 原文地址 本文主要介绍在使用阿里云Redis的开发规范,从下面几个方面进行说明. 键值设计 命令使用 客户端使用 相关工具 删除bigkey 通过本文的介绍可以减少使用R ...
- 阿里云 Redis 开发规范
阿里云Redis开发规范-阿里云开发者社区 https://developer.aliyun.com/article/531067 https://mp.weixin.qq.com/s/UWE1Kx6 ...
- Redis 使用规范
Redis 使用规范围绕如下几个纬度展开: 键值对使用规范: 命令使用规范: 数据保存规范: 运维规范. 键值对使用规范 有两点需要注意: 好的 key 命名,才能提供可读性强.可维护性高的 key, ...
- 一份完整的阿里云 Redis 开发规范,值得收藏!
来源:yq.aliyun.com/articles/531067 作者:付磊-起扬 本文主要介绍在使用阿里云Redis的开发规范,从下面几个方面进行说明. 键值设计 命令使用 客户端使用 相关工具 通 ...
- 阿里云Redis开发规范
转自: https://yq.aliyun.com/articles/531067 摘要: 本文介绍了在使用阿里云Redis的开发规范,从键值设计.命令使用.客户端使用.相关工具等方面进行说明,通过本 ...
- Redis 开发规范
本文主要介绍在使用阿里云Redis的开发规范,从下面几个方面进行说明. 键值设计 命令使用 客户端使用 相关工具 通过本文的介绍可以减少使用Redis过程带来的问题. 一.键值设计 1.key名设计 ...
- redis使用规范文档 20170522版
运维redis很久了,一直是口头给rd说各种要求,尝试把这些规范总结成文档 摘选一些可能比较通用的规则如下: 强制:所有的key设置过期时间(最长可设置过期时间10天,如有特殊要求,联系dba说明原因 ...
- Redis开发规范
1.冷热数据分离,不要将所有数据全部都放到Redis中 虽然Redis支持持久化,但是Redis的数据存储全部都是在内存中的,成本昂贵.建议根据业务只将高频热数据存储到Redis中[QPS大于5000 ...
- 深入解读阿里云Redis开发规范
Key命名设计:可读性.可管理性.简介性 规范建议使用冒号即:进行分割拼接,因为很多Redis客户端是根据冒号分类的.比如有几个Key:apps:app:1.apps:app:2和apps:app:3 ...
- 2020阿里巴巴官方最新Redis开发规范!
本文主要介绍在使用阿里云Redis的开发规范,从下面几个方面进行说明. 键值设计 命令使用 客户端使用 相关工具 通过本文的介绍可以减少使用Redis过程带来的问题. 一.键值设计 1.key名设计 ...
随机推荐
- Java中的CAS实现原理
一.什么是CAS? 在计算机科学中,比较和交换(Conmpare And Swap)是用于实现多线程同步的原子指令. 它将内存位置的内容与给定值进行比较,只有在相同的情况下,将该内存位置的内容修改为新 ...
- 关于input输入框内设置小图标的问题
其实很简单,只需要html和css就可以搞定啦 首先:<input class="layui-input" id="test1" placeholder= ...
- Javascript 智能输入数字且保留小数点后三位
html: <input type="text" name="cprice" placeholder="最多保留小数点后三位" onk ...
- React文档(十二)组合vs继承
React拥有很强大的组合模型,我们建议使用组合来替代继承来重利用组件之间的代码. 在本章节中,我们将讨论一些开发者经常触及继承的问题,并且我们该如何使用组合来解决这些问题. 组合 一些组件事先不知道 ...
- 数据结构与算法之PHP排序算法(快速排序)
一.基本思想 快速排序又称划分交换排序,是对冒泡排序的一种改进,亦是分而治之思想在排序算法上的典型应用. 它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部 ...
- js 数组的pop(),push(),shift(),unshift()方法小结
关于数组的一些操作方法小结: pop(),push(),shift(),unshift()四个方法都可改变数组的内容以及长度: 1.pop() :删除数组的最后一个元素,并返回被删除的这个元素的值: ...
- [luogu P2234] [HNOI2002]营业额统计
[luogu P2234] [HNOI2002]营业额统计 题目描述 Tiger最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况. Tiger拿出了公司 ...
- java中double和float精度丢失问题及解决方法
在讨论两位double数0.2和0.3相加时,毫无疑问他们相加的结果是0.5.但是问题总是如此吗? 下面我们让下面两个doubles数相加,然后看看输出结果: @Test public void te ...
- SSH免密码登录教程
在一些受信任的环境中配置免密码登录,是比较方便的:而对于ansible等自动化工具配置免密码登录更是必要的. 免密码登录的要点就是,把想让服务器信任的客户机的公钥发送到服务器. 当客户机连接服务器时直 ...
- NODE_ENV=production关于不同系统的写法
通过NODE_ENV可以来设置环境变量(默认值为development).一般我们通过检查这个值来分别对开发环境和生产环境下做不同的处理.可以在命令行中通过下面的方式设置这个值: linux & ...