SQLServer之创建主XML索引
创建主XML索引注意事项
若要创建主 XML 索引,请使用 CREATE INDEX (Transact-SQL) Transact-SQL DDL 语句。 XML 索引不完全支持可用于非 XML 索引的所有选项。
创建 XML 索引时注意下列事项:
若要创建主 XML 索引,含有被索引的 XML 列的表(称为基表)必须具有主键的聚集索引。 这确保了在对基表进行了分区的情况下,可以使用相同的分区方案和分区函数对主 XML 索引进行分区。
如果存在 XML 索引,则不能修改基表的聚集主键。 在修改主键之前,必须删除表的所有 XML 索引。
您可以对单个 xml 类型列创建主 XML 索引。 您无法将 XML 类型列作为键列来创建任何其他类型的索引。 但是,可以在非 XML 索引中包含 xml L 类型列。 表中的每个 xml 类型列都可以有自己的主 XML 索引。 但是,一个 xml 类型列只允许有一个主 XML 索引。
XML 索引和非 XML 索引存在于相同的命名空间中。 因此,同一表的 XML 索引和非 XML 索引不能具有相同的名称。
对于 XML 索引,IGNORE_DUP_KEY 选项和 ONLINE 选项始终设置为 OFF。 您可以将这些选项的值指定为 OFF。
将用户表的文件组和分区信息应用于 XML 索引。 用户无法单独为 XML 索引指定这些信息。
DROP_EXISTING 索引选项可以删除主 XML 索引并创建一个新的主 XML 索引,或者删除辅助 XML 索引并创建一个新的辅助 XML 索引。 但是,此选项不能通过删除辅助 XML 索引来创建新的主 XML 索引,反之亦然。
主 XML 索引名称与视图名称有相同的限制。
不能对视图中的 xml 类型列、 xml 类型列的 表值变量或 xml 类型变量创建 XML 索引。
若要使用 ALTER TABLE ALTER COLUMN 选项将 xml 类型列从非类型化的 XML 更改为类型化的 XML,或者从类型化的 XML 更改为非类型化的 XML,则列不应存在 XML 索引。 如果确实存在,则在尝试更改列类型之前必须删除该索引。
创建 XML 索引时必须将选项 ARITHABORT 设置为 ON。 若要使用 XML 数据类型方法查询、删除、更新 XML 列中的值或向 XML 列中插入值,则必须对连接设置相同的选项。 如果没有设置,则 XML 数据类型方法将会失败。
备注
有关 XML 索引的信息可以在目录视图中找到。 但是,不支持 sp_helpindex 。 本主题后面部分提供的示例说明了如何查询目录视图以查找 XML 索引信息。
如果 XML 数据类型列包含类型为 XML 架构类型 xs:date 或 xs:dateTime (或这些类型的任何子类型)的值且这些值中的年份小于 1,则在对这样的 XML 数据类型列创建或重新创建主 XML 索引时,索引创建操作在 SQL Server 2008 和更高版本中将失败。 SQL Server 2005 允许使用这些值,因此在 SQL Server 2005中生成的数据库中创建索引时可能会出现这种问题。 有关详细信息,请参阅 类型化的 XML 与非类型化的 XML 的比较。
使用SSMS数据库管理工具创建主XML索引
使用表设计器创建主XML索引
1、连接数据库,选择数据库,选择数据表-》右键点击-》选择设计。
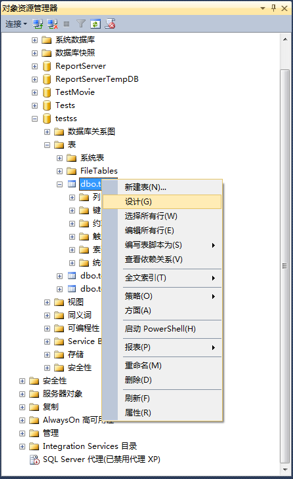
2、在表设计器窗口-》选择要创建xml索引的数据列-》右键点击-》选的xml索引。
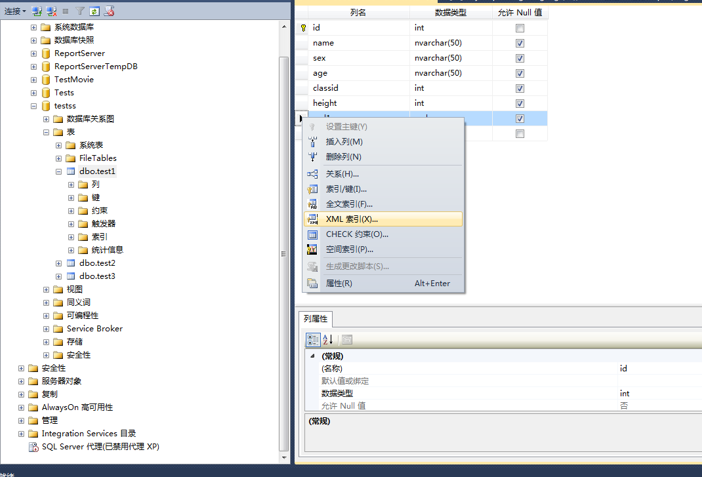
3、在xml索引弹出框-》点击添加,添加索引-》输入索引名称-》输入索引描述-》表设计器可以选择默认-》点击关闭。

4、点击保存(或者ctrl+s)-》关闭表设计器-》刷新表-》查询结果。
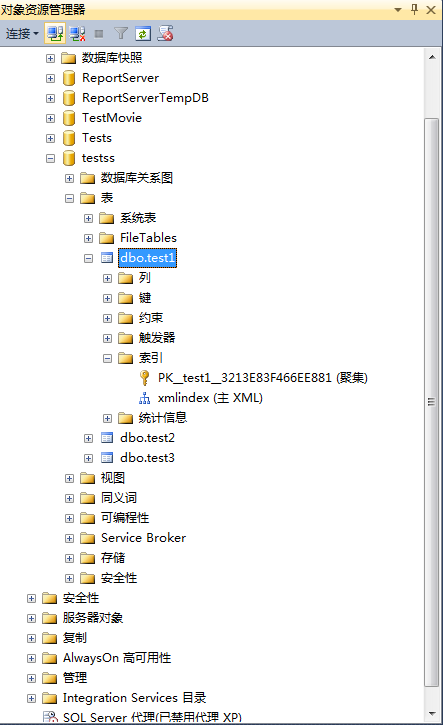
使用对象资源管理器创建主XML索引
1、连接数据库,选择数据库,选择数据表-》展开数据表-》右键点击索引-》选择新建索引-》选择主XML索引。

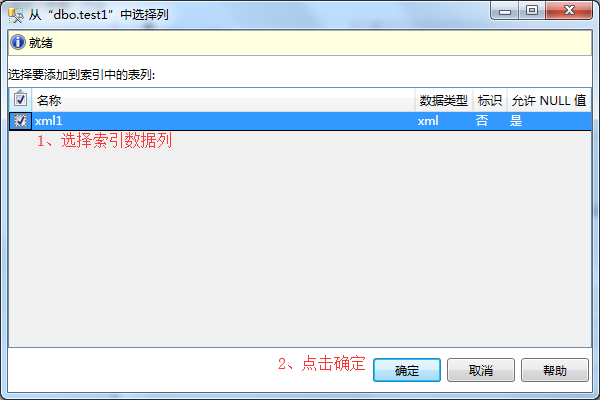
2、在新建索引弹出框-》输入索引名称-》点击添加选择索引数据列。
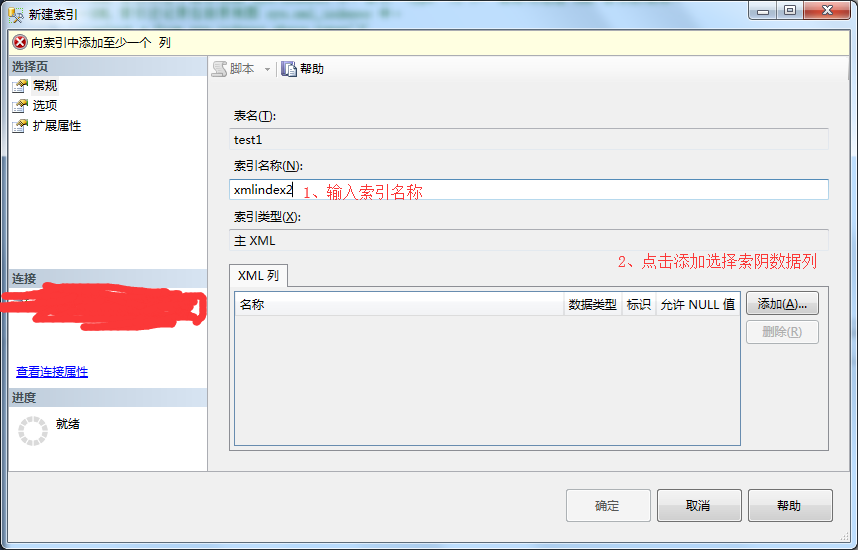
3、在数据列弹出框-》选择数据列-》点击确定。
4、在新建索引弹出框-》点击选项-》主XML索引属性可以自己设置,也可以选择系统默认。

5、在新建索引弹出框-》选择扩展属性-》输入扩展属性名称和值-》输入完成点击确定。

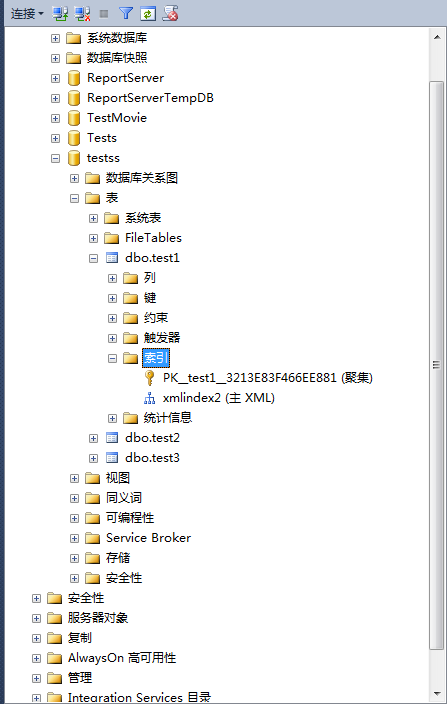
6、不需要刷新表可直接查看结果。
使用T-SQL脚本创建主XML索引
语法:
--声明数据库引用
use 数据库;
go
--判断xml索引是否存在,如果存在则先删除在创建
if exists(select * from sys.indexes where name=索引名称)
drop index 索引名称 on 表名;
go
--添加xml数据类型数据列
create
primary --声明为主索引
xml --声明为xml索引
index --声明创建索引
索引名称--声明索引名称
on 表名--声明索引所在表
(列名) --声明索引在哪个数据列
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index={ on | off },
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=n,
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute={ on | off },
--aloow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks={ on | off },
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
--allow_page_locks=off:不使用页锁。
allow_page_locks={ on | off },
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing={ on | off },
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb={ on | off },
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online={ on | off },
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
maxdop=max_degree_of_parallelism
)
go
--添加索引注释
execute sp_addextendedproperty N'MS_Description',N'缩影描述',N'user',N'dbo',N'table',N'test1',N'index',N'说明名称';
go
示例:
--声明数据库引用
use testss;
go
--判断xml索引是否存在,如果存在则先删除在创建
if exists(select * from sys.indexes where name='xmlindex')
drop index xmlindex on test1;
go
--添加xml数据类型数据列
create
primary --声明为主索引
xml --声明为xml索引
index --声明创建索引
xmlindex --声明索引名称
on test1 --声明索引所在表
(xml1) --声明索引在哪个数据列
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index=on,
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=1,
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute=off,
--aloow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks=on,
--aloow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_page_locks=on,
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing=off,
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb=on,
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online=off,
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
maxdop=1
)
go
--添加索引注释
execute sp_addextendedproperty N'MS_Description',N'第一个xml数据列',N'user',N'dbo',N'table',N'test1',N'index',N'xmlindex';
go

创建主XML索引优缺点
优点:
1、可以完整、一致的表示XML的值。
2、XML 值相对较大,而检索的部分相对较小。 生成索引避免了在运行时分析所有数据,并能实现高效的查询处理,从而使索引查找受益。
3、查询效率会大大提高。
缺点:
1、增加存储空间。
SQLServer之创建主XML索引的更多相关文章
- SQLServer之创建辅助XML索引
创建辅助XML索引 使用 CREATE INDEX (Transact-SQL)Transact-SQL DDL 语句可创建辅助 XML 索引并且可指定所需的辅助 XML 索引的类型. 创建辅助 XM ...
- sql语句创建主键、外键、索引、绑定默认值
use Mengyou88_Wuliu --创建公司表 create table dbo.Company2 ( CompanyID ,) not null, CompanyName ) null, A ...
- oracle建表的时候同时创建主键,外键,注释,约束,索引
--主键create table emp (id number constraint id_pr primary key ,name1 varchar(8));create table emp9 (i ...
- 5.oracle建表的时候同时创建主键,外键,注释,约束,索引
5.oracle建表的时候同时创建主键,外键,注释,约束,索引 1 --主键 )); ) ,constraint aba_pr primary key(id,name1)); --外键 )); --复 ...
- Oracle创建主键优劣
创建主键方式 一个表的主键是唯一标识,不能有重复,不允许为空. 一个表的主键可以由一个字段或多个字段共同组成. -- 列级,表级建立主键 1.create table constraint_test ...
- SqlServer性能优化 查询和索引优化(十二)
查询优化的过程: 查询优化: 功能:分析语句后最终生成执行计划 分析:获取操作语句参数 索引选择 Join算法选择 创建测试的表: select * into EmployeeOp from Adve ...
- oracle创建主键序列和在ibatis中应用
oracle创建主键序列 oracle主键序列的查询和ibitas中应用
- Oracle创建主键自增表
Oracle创建主键自增表 1.创建表 create table Test_Increase( userid number(10) NOT NULL primary k ...
- SQLServer之创建唯一聚集索引
创建唯一聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自动 ...
随机推荐
- 动手实现一个 LRU cache
前言 LRU 是 Least Recently Used 的简写,字面意思则是最近最少使用. 通常用于缓存的淘汰策略实现,由于缓存的内存非常宝贵,所以需要根据某种规则来剔除数据保证内存不被撑满. 如常 ...
- Xamarin.Android多窗口传值【1】
这种非常常见的场景我觉得大家都遇到过,那么我么可以通过Activity进行编码传值. using System.Text; using System; using Android.App; using ...
- 『最小表示法 Necklace』
最小表示法 这是一个简单的字符串算法,其解决的问题如下: 给定一个字符串\(S\),长度为\(n\),如果把它的最后一个字符不断放到最前面,会得到\(n\)个不同的字符串,那么我们称这\(n\)个字符 ...
- C语言程序猿必会的内存四区及经典面试题解析
前言: 为啥叫C语言程序猿必会呢?因为特别重要,学习C语言不知道内存分区,对很多问题你很难解释,如经典的:传值传地址,前者不能改变实参,后者可以,知道为什么?还有经典面试题如下: #include & ...
- JavaScript与WebAssembly进行比较
本文由云+社区发表 作者:QQ音乐前端团队 在识别和描述核心元素的过程中,我们分享了构建SessionStack时使用的一些经验法则,这是一个轻量级但健壮且高性能的JavaScript应用程序,以帮助 ...
- Docker 网络之理解 bridge 驱动
笔者在前文<Docker 网络之进阶篇>中介绍了 CNM(Container Network Model),并演示了 bridge 驱动下的 CNM 使用方式.为了深入理解 CNM 及最常 ...
- MyBatis动态代理执行原理
前言 大家使用MyBatis都知道,不管是单独使用还是和Spring集成,我们都是使用接口定义的方式声明数据库的增删改查方法.那么我们只声明一个接口,MyBatis是如何帮我们来实现SQL呢,对吗,我 ...
- C#工具:Bootstrap WPF Style,Bootstrap风格的WPF样式
简介 GitHub地址:https://github.com/ptddqr/bootstrap-wpf-style 此样式基于bootstrap-3.3.0,样式文件里的源码行数都是指的这个版本.CS ...
- (摘)Entity Framework Core 2.1带来更好的SQL语句生成方案
微软发布了Entity Framework Core2.1,为EF开发者带来了很多期待已久的特性.EF Core 2.1增加了对SQL GROUP BY的支持,支持延迟加载和数据种子等. EF Cor ...
- 37.QT-QTSingleApplication-程序只运行一个实例
QTSingleApplication由Qt官方提供的,用于实现只启动一个实例,并在启动时可以向向另一个实例通信(依赖于QtNetwork模块) QTSingleApplication下载路径:链接: ...