Apache Hadoop 2.9.2 的Federation架构设计
Apache Hadoop 2.9.2 的Federation架构设计
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
能看到这篇文件,说明你对NameNode的工作原理想必已经了如指掌了。也知道他将来会面料的一些弊端,我们知道NameNode在启动时会将镜像文件(fsimage)和编辑日志(edits)从磁盘加载到内存,生成最初的元数据信息后,从而退出安全模式。但是随着数据量越来也多,逐步形成了大数据。根据有关技术报告知道,国内有几家优秀的互联网公司,如百度,腾讯和阿里巴巴等公司数据规模如下:
- 2013年百度相关技术报告称,百度数据总量接近1000PB,网页的数量大是几千亿个,每年更新几十亿个,每天查询次数几十亿次。
- 2013年腾讯相关技术报告称,腾讯约有8亿用户,4亿移动用户,总存储数据量经压缩处理以后在100PB左右,日新增200TB到300TB,月增加10%的数据量。
- 2013年阿里巴巴相关技术报告称,总体数据量为100PB,每天的活跃数据量已经超过50TB,共有4亿条产品信息和2亿多名注册用户,每天访问超过4000万人次。
综上所述,单台NameNode需要记录如上所属的公司数据,那定是相当吃力,而且还是6年前的数据信息,尽管你单台NameNode的内存是256G,依旧是不够用的,我们知道HA模式只是增加了集群的可用性,但是并没有负载均衡的作用,因为HA只能有一台机器可以对外提供写操作。那如何解决这个问题呢?其实官方已经想到了这个问题,相比大家也知道,就是联邦模式(Federation),本文将详细介绍如何部署联邦模式。
一.NameNode架构的局限性
1>.Namespace(名称空间)的限制
就像我们上面提到过的,由于NameNode在内存中存储所有的元数据(metadata),因此单个NameNode所能够存储的对象(文件+块)数据受到NameNode所在JVM的heap size的限制。
2>.隔离问题
由于HDFS仅有一个NameNode,无法隔离各个程序,因此HDFS上的一个实验程序就很可能影响整个HDFS上运行的程序。
3>.性能的瓶颈
由于是单个NameNode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个NameNode的吞吐量。
二.HDFS Federation架构设计
关于HDFS的联邦模式,官方文档是这样说的:(http://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/Federation.html)
In order to scale the name service horizontally, federation uses multiple independent Namenodes/namespaces. The Namenodes are federated; the Namenodes are independent and do not require coordination with each other. The Datanodes are used as common storage for blocks by all the Namenodes. Each Datanode registers with all the Namenodes in the cluster. Datanodes send periodic heartbeats and block reports. They also handle commands from the Namenodes.
这段话并不难理解,作为运维的小伙伴应该很容易明白这其实就是负载均衡,把之前只有一个NameNode进行元数据处理的事情现在交给了多个NameNode来处理,每个NameNode的处理的数据并不重复,当然Federation和HA模式并不冲突,为了解决多个联邦模式出现单点故障,因此,建议大家把联邦模式和HA一起部署,让多个NameNode的处理的元数据都不存在单点故障!
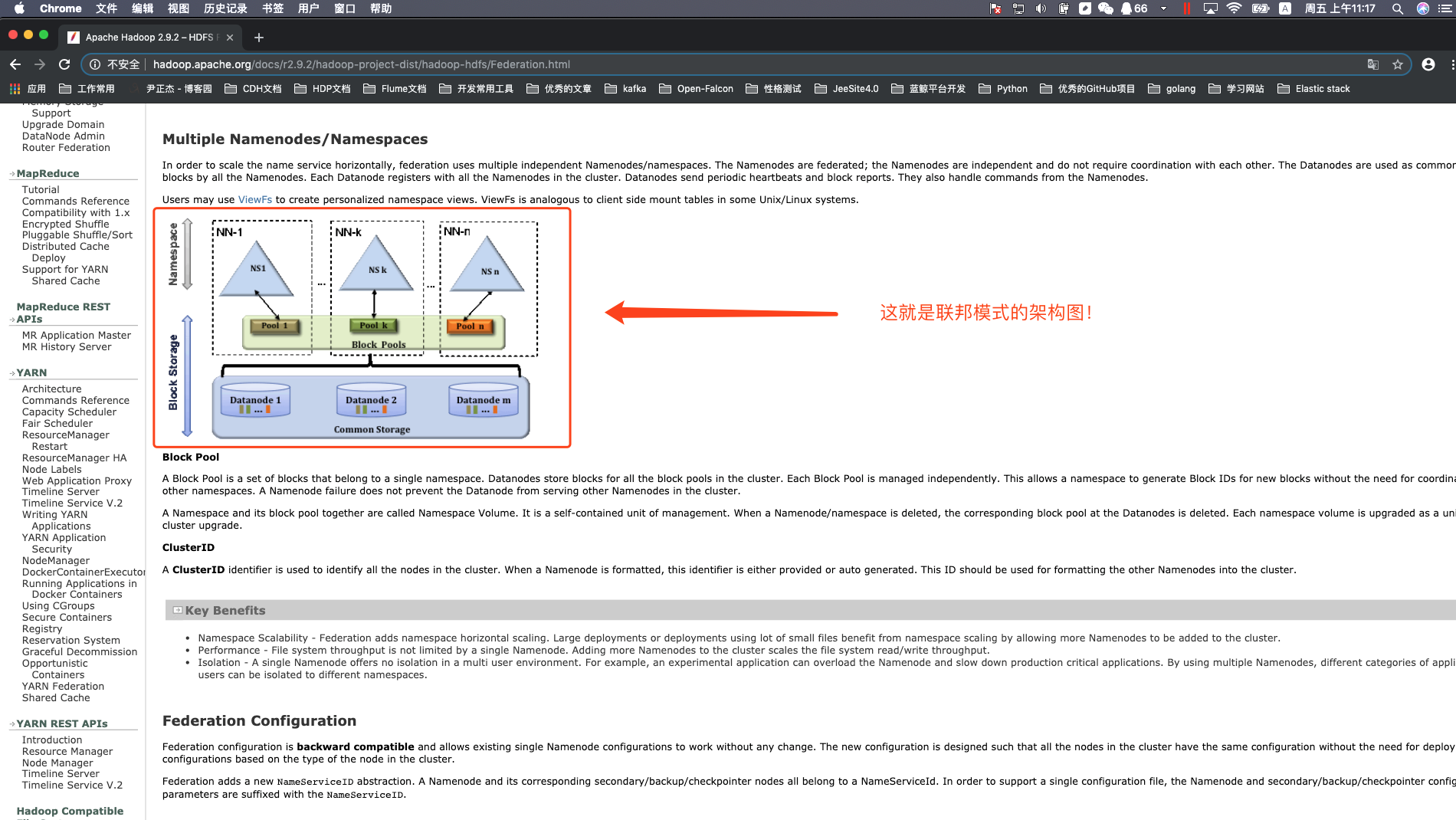
三.HDFS Federation特点总结
1>.通过多个namenode/namespace(Fsimage)把元数据的存储和管理分散到多个节点中,使到namenode/namespace可以通过增加机器来进行水平扩展。
2>.能把单个namenode的负载分散到多个节点中,在HDFS数据规模较大的时候不会也降低HDFS的性能。
3>.可以通过多个namespace来隔离不同类型的应用,把不同类型(如图片业务,爬虫业务,日志审计业务)应用的HDFS元数据的存储和管理分派到不同的namenode中(这样隔离行较强)。
4>.不同namenode的namespace(Fsimage)数据他们是无法相互访问的。
四.HDFS Federation部署实战
五.验证 HDFS Federation的可用性
(未完待续........)
Apache Hadoop 2.9.2 的Federation架构设计的更多相关文章
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- Apache hadoop namenode ha和yarn ha ---HDFS高可用性
HDFS高可用性Hadoop HDFS 的两大问题:NameNode单点:虽然有StandbyNameNode,但是冷备方案,达不到高可用--阶段性的合并edits和fsimage,以缩短集群启动的时 ...
- Ubuntu14.04用apt在线/离线安装CDH5.1.2[Apache Hadoop 2.3.0]
目录 [TOC] 1.CDH介绍 1.1.什么是CDH和CM? CDH一个对Apache Hadoop的集成环境的封装,可以使用Cloudera Manager进行自动化安装. Cloudera-Ma ...
- Hadoop学习笔记1---简介 优点 架构分析
一.Hadoop简介 Hadoop最早起源于Nutch.Nutch是一个开源的网络搜索引擎,由Doug Cutting于2002年创建.Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取. ...
- 【Hadoop学习】Apache Hadoop ResourceManager HA
简介 本向导简述了YARN资源管理器的HA,并详述了如何配置并使用该特性.RM负责追踪集群中的资源,并调度应用程序(如MapReduce作业).Hadoop2.4以前,RM是YARN集群中的单点故障. ...
- Apache Hadoop RPC Authentication 安全绕过漏洞
漏洞名称: Apache Hadoop RPC Authentication 安全绕过漏洞 CNNVD编号: CNNVD-201308-425 发布时间: 2013-08-28 更新时间: 2013- ...
- Apache Hadoop学习笔记一
官网:http://hadoop.apache.org/ 1 什么是Hadoop? Apache™Hadoop®项目开发了用于可靠,可扩展的分布式计算的开源软件. Apache Hadoop软件库是一 ...
- What Is Apache Hadoop
What Is Apache Hadoop? The Apache™ Hadoop® project develops open-source software for reliable, scala ...
- Apache Hadoop YARN: 背景及概述
从2012年8月开始Apache Hadoop YARN(YARN = Yet Another Resource Negotiator)成了Apache Hadoop的一项子工程.自此Apache H ...
随机推荐
- QT通过url下载图片到本地
/* strUrl:下载图片时需要的url strFilePath:下载图片的位置(/home/XXX/YYY.png) */ void ThorPromote::downloadFileFromUr ...
- 测者的测试技术手册:Junit执行单元测试用例成功,mvn test却失败的问题和解决方法
今天遇见了一个奇怪的问题,在IDE中run unit test,全部cases都成功了,但是后来通过mvn test运行case确保错了.在寻求原因的同时也找到了对应的解决方法. Run Unit T ...
- Testlink1.9.17使用方法( 第四章 测试需求管理 )
第四章 测试需求管理 QQ交流群:585499566 需求规格说明书是我们开展测试的依据.首先,我们可以对项目(产品)的需求规格说明书进行分解和整理,将其拆分为多个需求,一个项目可以包含多个需求,一个 ...
- 报错TypeError: $(...).live is not a function解决方法
报错的原因是这个方法在jquery1.7以后就被废除了, 1.7以后的版本改用.on()方法 之前的用法: .live(events, function) 新方法: .on(eventType, se ...
- win7系统搭建FTP服务器
工作需要,所以研究了一下. 1. 打开: 控制面板 -> 卸载程序 -> (左侧)打开或关闭windows功能 等个一小会,勾选如下图红色方框内的选项. 2. 开始 -> 搜索: I ...
- 实战 EF(LINQ) 如何以子查询的形式来 Join
如题,大多数网上关于 LINQ Join 的示例都是以 from x in TableA join ... 这样的形式,这种有好处,也有劣势,就是在比如我们使用的框架如果已经封装了很多方法,比如分页 ...
- 数据结构学习之字符串匹配算法(BF||KMP)
数据结构学习之字符串匹配算法(BF||KMP) 0x1 实验目的 通过实验深入了解字符串常用的匹配算法(BF暴力匹配.KMP.优化KMP算法)思想. 0x2 实验要求 编写出BF暴力匹配.KM ...
- GL-inet路由器当主控制作WIFI视频小车
以前也用单片机做过WIFI小车,但是单片机没有自带WIFI,仍然需要用到小路由器作为图传和控制信号传输.既然肯定要用到路由器,那何不直接用路由器作为主控呢,这样就省掉了单片机.这次作为主控的GL-in ...
- 使用try-with-resources优雅的关闭IO流
Java类库中包括许多必须通过调用close方法来手工关闭的资源.例如InputStream.OutputStream和java.sql.Connection.客户端经常会忽略资源的关闭,造成严重的性 ...
- JS 设计模式四 -- 模块模式
概念 模块模式的思路 就是 就是单例模式添加私有属性和私有方法,减少全局变量的使用. 简单的代码结构: var singleMode = (function(){ // 创建私有变量 var priv ...