爬虫解析之css,xpath语法
一、xpath语法
xpath实例文档
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book> <book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book> </bookstore>
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
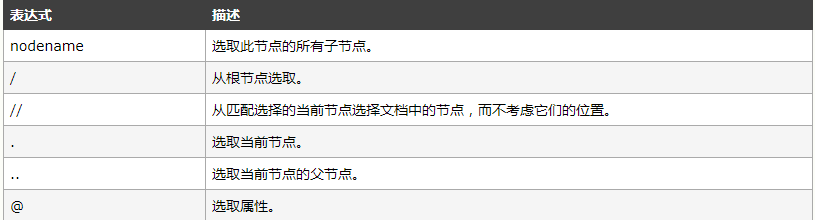
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:

谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
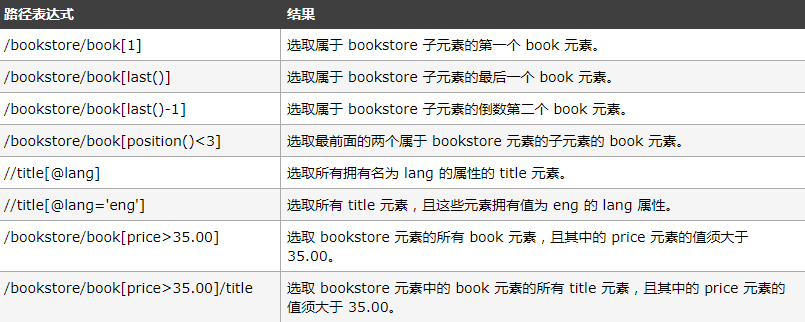
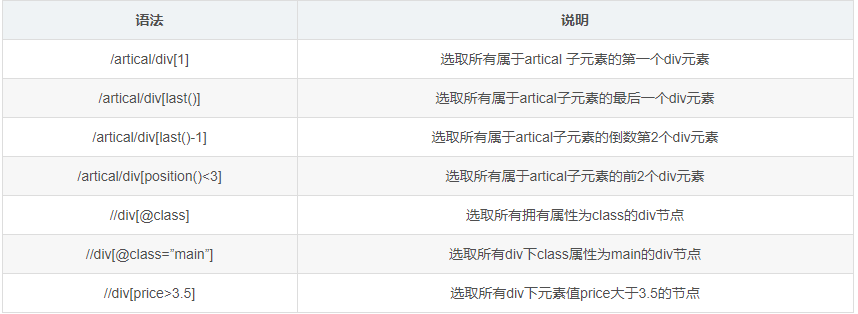
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。

实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

Xpath轴
轴可以定义相对于当前节点的节点集
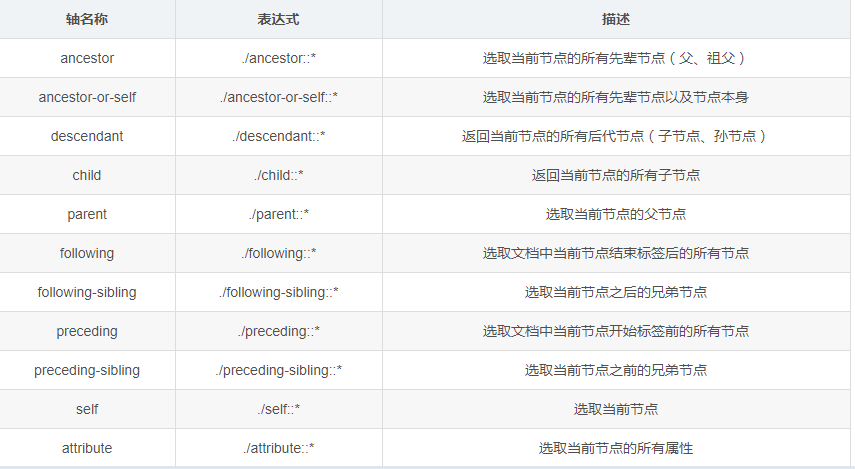
练习
选取所有 title
下面的例子选取所有 title 节点:
/bookstore/book/title 选取第一个 book 的 title
下面的例子选取 bookstore 元素下面的第一个 book 节点的 title:
/bookstore/book[1]/title 下面的例子选取 bookstore 元素下面的第一个 book 节点的 title:
xml.setProperty("SelectionLanguage","XPath");
xml.selectNodes("/bookstore/book[1]/title");
选取所有价格
下面的例子选取 price 节点中的所有文本:
/bookstore/book/price/text() 选取价格高于 35 的 price 节点
下面的例子选取价格高于 35 的所有 price 节点: /bookstore/book[price>35]/price 选取价格高于 35 的 title 节点
下面的例子选取价格高于 35 的所有 title 节点: /bookstore/book[price>35]/title
二、CSS语法
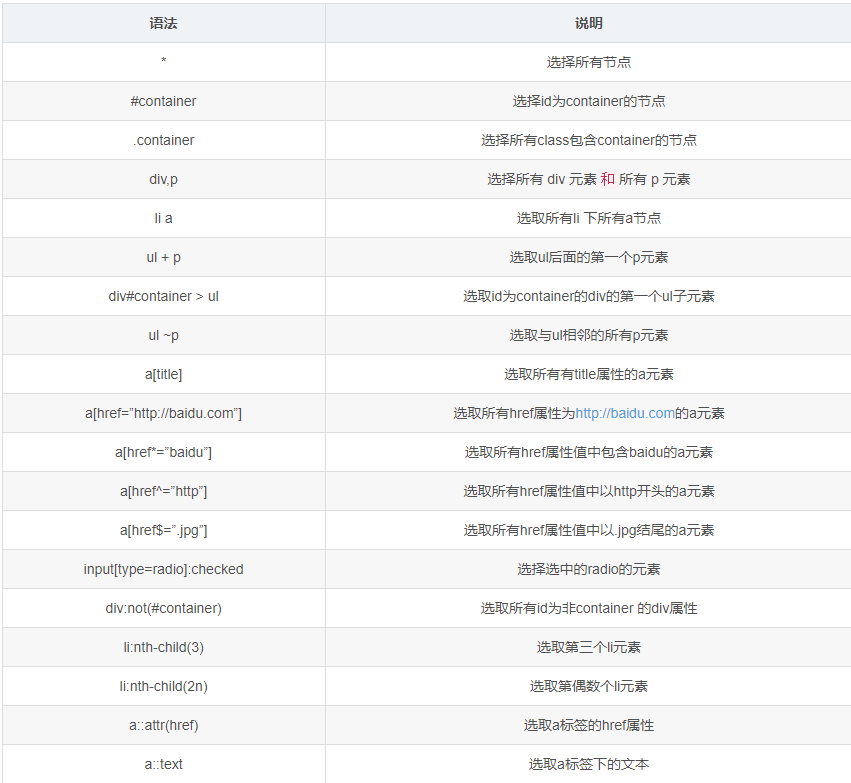
提取内容
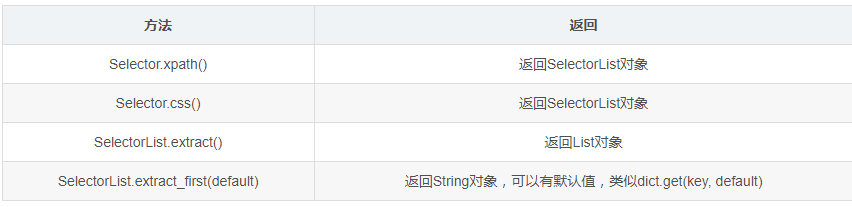
1) 按照审查元素的写法不一定正确,要按照网页源码的才行 因为不一样,网页源码才是你看到的 2) 浏览器有自带的复制xpath功能,firefox下载firebug插件 3) xpath有c的速度,所以按照[@class=""]准确性较高
爬虫实战xpath和css
class DrugInfo(object):
"""
提取的药品信息:
self.drug_name #药品名称
self.category #药品类型
self.cite #国家标准
self.company #生产厂家
self.address #厂家地址
self.license_number #批准文号
self.approval_date #批准日期
self.form_drug #剂型
self.spec #规格
self.store #储存方法
self.period_valid #有效期限
self.attention_rank #关注度排名
self.indication #适应症
self.component #成分
self.function #功能主治
self.usage_dosage #用法用量
self.contraindication #禁忌症
self.special_population #特殊人群用药
self.indications #适应症概况
self.is_or_not_medical_insurance #是否属于医保
self.is_or_not_infections #是否有传染性
self.related_symptoms #相关症状
self.related_examination #相关检查
self.adverse_reaction #不良反应
self.attention_matters #注意事项
self.interaction #药物相互作用
self.pharmacological_action #药理作用
self.revision_date #说明书修订日期
self.drug_use_consult #用药咨询
self.drug_use_experience #用药经验 """
def __init__(self,drug):
drug_dir = os.path.join(drug_path, drug)
self.drug_name = re.findall('(.*?)\[\d+\]',drug)[0]
self.drug_id = re.findall('.*?\[(\d+)\].*',drug)[0]
self.drug_dir = drug_dir
self.drug_use_experience = ''
self.drug_use_consult = ''
self.file_list = os.listdir(self.drug_dir) self.logger = Logger() self.result = True self.dispatch()
if self.drug_use_consult.__len__()==0:self.drug_use_consult = '无'
if self.drug_use_experience.__len__()==0:self.drug_use_experience = '无' def dispatch(self):
for file in self.file_list:
if file.endswith('药品概述.html'):
self.drug_summary(self.file_path(file))
elif file.endswith('详细说明书.html'):
self.drug_instruction(self.file_path(file))
elif re.match('.*?用药咨询.*',file):
self.drug_consultation(self.file_path(file))
elif re.match('.*?用药经验.*',file):
self.drug_experience(self.file_path(file))
else:
self.result = False
break def file_path(self,file):
return os.path.join(self.drug_dir,file) def read_file(self,file):
with open(file,'r') as f:
html = f.read()
return html def drug_summary(self,file):
"""药品概况"""
html = self.read_file(file)
selector = Selector(text=html)
self.category = selector.xpath('//div[@class="t1"]/cite[1]/span/text()').extract_first() #药品类型
if not self.category:
self.category = '未知'
self.cite = selector.xpath('//div[@class="t1"]/cite[2]/span/text()').extract_first() #国家标准
if not self.cite:
self.cite = '未知'
try:
self.company = selector.css('.t3 .company a::text').extract()[0] #生产厂家
except IndexError as e:
self.company = '未知'
try:
self.address = selector.css('.t3 .address::text').extract()[0] #厂家地址
except IndexError as e:
self.address = '未知'
try:
self.license_number = selector.xpath('//ul[@class="xxs"]/li[1]/text()').extract_first().strip() #批准文号
except AttributeError:
self.license_number = '未知'
try:
self.approval_date = selector.xpath('//ul[@class="xxs"]/li[2]/text()').extract_first().strip() #批准日期
except AttributeError:
self.approval_date = '未知'
try:
self.form_drug = selector.xpath('//ul[@class="showlis"]/li[1]/text()').extract_first().strip() #剂型
except AttributeError:
self.form_drug = '未知'
try:
self.spec = selector.xpath('//ul[@class="showlis"]/li[2]/text()').extract_first().strip() #规格
except AttributeError:
self.spec = '未知'
try:
self.store = selector.xpath('//ul[@class="showlis"]/li[3]/text()').extract_first().strip().strip('。') #储存方法
except AttributeError:
self.store = '未知'
try:
self.period_valid = selector.xpath('//ul[@class="showlis"]/li[4]/text()').extract_first().strip('。').replace('\n','') #有效期限
except AttributeError:
self.period_valid = '未知'
self.attention_rank = selector.css('.guanzhu cite font::text').extract_first() #关注度排名
if not self.attention_rank:
self.attention_rank = '未知'
self.indication = ','.join(selector.css('.whatsthis li::text').extract()) #适应症
if self.indication == '':
self.indication = '未知'
usage_dosage = selector.css('.ps p:nth-child(3)::text').extract_first() #用法用量
if usage_dosage:
self.usage_dosage = re.sub('<.*?>','',usage_dosage).strip().replace('\n','') #禁忌症
else:
self.usage_dosage = '未知'
indications = selector.css('#diseaseintro::text').extract_first() #适应症概况
if indications:
self.indications = re.sub('<.*?>','',indications).strip().replace('\n','') #禁忌症
else:
self.indications = '未知'
try:
self.is_or_not_medical_insurance = selector.css('.syz_cons p:nth-child(2)::text').extract_first().split(':')[1] #是否属于医保
except AttributeError as e:
self.is_or_not_medical_insurance = '未知'
try:
self.is_or_not_infections = selector.css('.syz_cons p:nth-child(3)::text').extract_first().split(':')[1].strip() #是否有传染性
except AttributeError as e:
self.is_or_not_infections = '未知'
self.related_symptoms = ','.join(selector.css('.syz_cons p:nth-child(4) a::text').extract()[:-1]) #相关症状
if len(self.related_symptoms) == 0:
self.related_symptoms = '未知'
self.related_examination = ','.join(selector.css('.syz_cons p:nth-child(5) a::text').extract()[:-1]) #相关检查
if len(self.related_examination) == 0:
self.related_examination = '未知' def drug_instruction(self,file):
"""详细说明书"""
html = self.read_file(file)
selector = Selector(text=html)
#注:不同药品之间网页结构有差别,提取的时候应注意
component = selector.xpath('//dt[text()="【成份】"]/following::*[1]').extract_first()
if not component:
self.component = '未知'
else:
self.component = re.sub('<.*?>','',component).strip() #成分
contraindication= selector.xpath('//dt[text()="【禁忌】"]/following::*[1]').extract_first()
if contraindication:
self.contraindication = re.sub('<.*?>','',contraindication).strip().replace('\n','') #禁忌症
else:
self.contraindication = '未知'
function = selector.xpath('//dt[text()="【功能主治】"]/following::*[1]').extract_first()
if function:
self.function = re.sub('<.*?>','',function).strip() #功能主治
else:
self.function = '未知' try:
self.adverse_reaction = selector.xpath('//dt[text()="【不良反应】"]/following::*[1]/p/text()').extract_first().strip('。') #不良反应
except AttributeError as e:
try:
self.adverse_reaction = selector.xpath('//dt[text()="【不良反应】"]/following::*[1]/text()').extract_first().strip('。') #不良反应
self.adverse_reaction = re.sub('<.*?>','',self.adverse_reaction).strip().replace('\n','') #注意事项
except AttributeError:
self.adverse_reaction = '未知'
attention_matters = selector.xpath('//dt[text()="【注意事项】"]/following::*[1]').extract_first()
if attention_matters:
self.attention_matters = re.sub('<.*?>','',attention_matters).strip().replace('\n','') #注意事项
else:
self.attention_matters = '未知'
self.logger.log('{}[{}]-注意事项为空'.format(self.drug_name,self.drug_id),False)
try:
self.interaction = selector.xpath('//dt[text()="【药物相互作用】"]/following::*[1]/p/text()').extract_first() #药物相互作用
self.interaction = re.sub('<.*?>','',self.interaction).strip().replace('\n','') #注意事项
except TypeError:
self.interaction = '未知'
try:
self.pharmacological_action = selector.xpath('//dt[text()="【药理作用】"]/following::*[1]/p/text()').extract_first() #药理作用
self.pharmacological_action = re.sub('<.*?>','',self.pharmacological_action).strip().replace('\n','')
except TypeError:
self.pharmacological_action = '未知'
try:
self.revision_date = selector.xpath('//dt[text()="【说明书修订日期】"]/following::*[1]/text()').extract_first().strip() #说明书修订日期
except AttributeError:
self.revision_date = '未知'
try:
self.special_population = selector.xpath('//dt[text()="【特殊人群用药】"]/following::*[1]/text()').extract_first() #特殊人群用药
self.special_population = re.sub('<.*?>','',self.special_population).strip().replace('\n','') #特殊人群用药
except TypeError:
self.special_population = '未知' def drug_consultation(self,file):
"""用药咨询"""
html = self.read_file(file)
selector = Selector(text=html)
drug_use_consult = selector.css('.dpzx_con .zx p::text').extract()
drug_use_consult = ''.join(drug_use_consult)
drug_use_consult = re.sub('<.*?>','',drug_use_consult).strip().replace('\n','') #用药咨询
self.drug_use_consult += drug_use_consult def drug_experience(self,file):
"""用药经验"""
html = self.read_file(file)
selector = Selector(text=html)
drug_use_experience = selector.css('.pls_box .pls_mid p::text').extract()
drug_use_experience = ''.join(drug_use_experience)
drug_use_experience = re.sub('<.*?>','',drug_use_experience).strip().replace('\n','') #用药经验
self.drug_use_experience += drug_use_experience.strip()
爬虫解析之css,xpath语法的更多相关文章
- Python爬虫利器三之Xpath语法与lxml库的用法
前面我们介绍了 BeautifulSoup 的用法,这个已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的是 Xpath 语法,同样是效率比较高的解析方法.如果大家对 Beau ...
- 爬虫解析库:XPath
XPath XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言.最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的 ...
- 12.Python爬虫利器三之Xpath语法与lxml库的用法
LXML解析库使用的是Xpath语法: XPath 是一门语言 XPath可以在XML文档中查找信息 XPath支持HTML XPath通过元素和属性进行导航 XPath可以用来提取信息 XPath比 ...
- python爬虫(8)--Xpath语法与lxml库
1.XPath语法 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPath 是 W3C XSLT 标准的主要元素,并且 XQuery ...
- 使用Dom4j的xPath解析xml文件------xpath语法
官方语法地址:http//www.w3school.com.cn/xpath/index.asp xpath使用路径表达式来选取xml文档中的节点或节点集.节点是通过沿着路径(path)或者步(ste ...
- Xpath语法-爬虫(一)
前言 这一章节主要讲解Xpath的基础语法,学习如何通过Xpath获取网页中我们想要的内容;为我们的后面学习Java网络爬虫基础准备工作. 备注:此章节为基础核心章节,未来会在网络爬虫的数据解析环节经 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(2)
上半部分内容链接 : https://www.cnblogs.com/lowmanisbusy/p/9069330.html 四.json和jsonpath的使用 JSON(JavaScript Ob ...
- 网页解析库-Xpath语法
网页解析库 简介 除了正则表达式外,还有其他方便快捷的页面解析工具 如:lxml (xpath语法) bs4 pyquery等 Xpath 全称XML Path Language, 即XML路径语言, ...
- Xpath re bs4 等爬虫解析器的性能比较
xpath re bs4 等爬虫解析器的性能比较 本文原始地址:https://sitoi.cn/posts/23470.html 思路 测试网站地址:http://baijiahao.baidu.c ...
随机推荐
- libstdc++适配Xcode10与iOS12
编译报错 当你开心得升级完新 macOS,以及新 XCode,准备体验了一把 Dark Mode 编程模式,开心的打开自己的老项目的时候,发现编译不通过了╮(╯_╰)╭ 如果你的工程中如果依赖 lib ...
- MySQL:1366 - Incorrect string value错误解决办法
今天使用navicat向MySQL中插入中文时,报错: - Incorrect string value:... 在我自己数据库设计之初,没有设计好字符编码格式的问题. 使用如下语句解决: alter ...
- Eclipse编程中免除alt+斜杠,设置自动提示
用eclipse进行编程时,设置自动提示 .abcdefghijklmnopqrstuvwxyz@
- Linux下禁止使用swap及防止OOM机制导致进程被kill掉
首先解释两个概念: swap:在linux里面,当物理内存不够用了,而又有新的程序请求分配内存,那么linux就会选择将其他程序暂时不用的数据交换到物理磁盘上(swap out),等程序要用的时候再读 ...
- LVS负载均衡集群
回顾-Nginx反向代理型负载 负载均衡(load balance)集群,提供了一种廉价.有效.透明的方法,来扩展网络设备和服务器的负载.带宽.增加吞吐量.加强网络数据处理能力.提高网络的灵活性和可用 ...
- C# 使用微软自带的Speech进行语音输出
1.在VS中使用微软自带的Speech进行语音播报,首先需要添加引用: 2.具体实现逻辑代码如下:
- docker pull报错failed to register layer: Error processing tar file(exit status 1): open permission denied
近来在一个云主机上操作docker pull,报错如下: failed to register layer: Error processing ): open /etc/init.d/hwclock. ...
- 定制json序列化
最近有人问我怎么定制一个json序列化,使序列化的时候只写出声明的父类成员,而不要把实际子类的成员写出来.当然,序列化用的是大家用的最多的json.net. 简单的说,这是个契约怎么解析的问题,jso ...
- Qt中的QWebView
一.Webkit了解 Webkit是一个开源的浏览器引擎,chrome也使用了作为核心.Qt中对Webkit做了封装,主要有以下几个类: QWebView :最常用的类,作为一个窗体控件 QWeb ...
- Zookeeper 客户端命令