使用python编辑和读取word文档
python调用word接口主要用到的模板为python-docx,基本操作官方文档有说明。
使用python新建一个word文档,操作就像文档里介绍的那样:
from docx import Document
from docx.shared import Inches document = Document() document.add_heading('Document Title', 0) #插入标题 p = document.add_paragraph('A plain paragraph having some ') #插入段落
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='IntenseQuote') document.add_paragraph(
'first item in unordered list', style='ListBullet'
)
document.add_paragraph(
'first item in ordered list', style='ListNumber'
) document.add_picture('monty-truth.png', width=Inches(1.25)) #插入图片 table = document.add_table(rows=1, cols=3) #插入表格
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for item in recordset:
row_cells = table.add_row().cells
row_cells[0].text = str(item.qty)
row_cells[1].text = str(item.id)
row_cells[2].text = item.desc document.add_page_break() document.save('demo.docx') #保存文档
读取和编辑一个已有的word文档,只需在一开始添加上文件路径就行了,如下:
from docx import Document
from docx.shared import Inches document = Document('demo.docx') #打开文件demo.docx
for paragraph in document.paragraphs:
print(paragraph.text) #打印各段落内容文本 document.add_paragraph(
'Add new paragraph', style='ListNumber'
) #添加新段落 document.save('demo.docx') #保存文档
如果是想读取其中的图片或是更复杂地编辑,首先我们需要先来认识下docx文档的格式组成:
docx是Microsoft Office2007之后版本使用的,用新的基于XML的压缩文件格式取代了其目前专有的默认文件格式,在传统的文件名扩展名后面添加了字母“x”(即“.docx”取代“.doc”、“.xlsx”取代“.xls”、“.pptx”取代“.ppt”)。
docx格式的文件本质上是一个ZIP文件。将一个docx文件的后缀改为ZIP后是可以用解压工具打开或是解压的。事实上,Word2007的基本文件就是ZIP格式的,他可以算作是docx文件的容器。
docx 格式文件的主要内容是保存为XML格式的,但文件并非直接保存于磁盘。它是保存在一个ZIP文件中,然后取扩展名为docx。将.docx 格式的文件后缀改为ZIP后解压, 可以看到解压出来的文件夹中有word这样一个文件夹,它包含了Word文档的大部分内容。而其中的document.xml文件则包含了文档的主要文本内容。
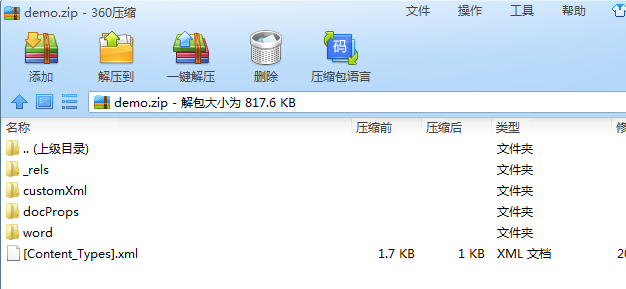
word目录下:

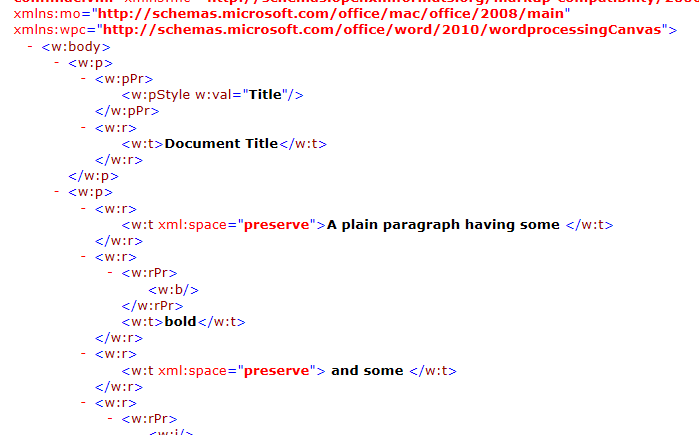
document.xml文件内容:
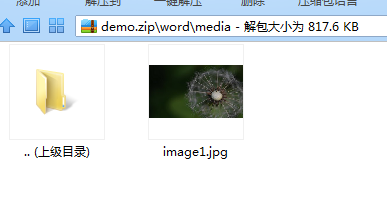
media目录下存放word文档中插入的图片:
所以,我们可以使用手工的方法编辑文件document.xml来对该word文档内容进行编辑,或是提取文档media中图片文件的方式来提取该word文档中所插入的所有图片。
import zipfile
f=zipfile.ZipFile('demo.docx','r')
for filename in f.namelist():
f.extract(filename)
使用python编辑和读取word文档的更多相关文章
- Python读取word文档(python-docx包)
最近想统计word文档中的一些信息,人工统计的话...三天三夜吧 python 不愧是万能语言,发现有一个包叫做 docx,非常好用,具体查看官方文档:https://python-docx.read ...
- Python读取word文档内容
1,利用python读取纯文字的word文档,读取段落和段落里的文字. 先读取段落,代码如下: 1 ''' 2 #利用python读取word文档,先读取段落 3 ''' 4 #导入所需库 5 fro ...
- Python用python-docx读写word文档
python-docx库可用于创建和编辑Microsoft Word(.docx)文件.官方文档:https://python-docx.readthedocs.io/en/latest/index. ...
- C#读取Word文档内容代码
首先要添加引用com组件:然后引用: using Word = Microsoft.Office.Interop.Word; 获取内容: /// /// 读取 word文档 返回内容 /// //// ...
- Python处理PDF和Word文档常用的方法
Python处理PDF和Word文档的模块是PyPDF2,使用之前需要先导入. 打开一个PDF文档的操作顺序是:用open()函数打开文件并用一个变量来接收,然后把变量给传递给PdfFileReade ...
- C# 设置、删除、读取Word文档背景——基于Spire.Cloud.Word
Spire.Cloud.Word.Sdk提供了接口SetBackgroudColor().SetBackgroudImage().DeleteBackground().GetBackgroudColo ...
- 利用POI工具读取word文档并将数据存储到sqlserver数据库中
今天实现了利用POI工具读取word文档,并将数据存储到sql数据库中,代码如下: package word; import java.io.File; import java.io.FileInpu ...
- java中读取word文档里的内容
package com.cn.peitest.excel.word; import java.io.FileInputStream; import java.io.FileOutputStream; ...
- [转载]linux上用PHP读取WORD文档
在linux上用PHP读取WORD文档,其实是使用了 antiword程序把word文档转化为txt文档. 再使用php执行系统命令调用而已. 具体操作如下: 1.安装antiword 官方站:htt ...
随机推荐
- Unity3d KeyCode 键盘各种键值详情
KeyCode :KeyCode是由Event.keyCode返回的.这些直接映射到键盘上的物理键. 值 对应键 Backspace 退格键 Delete Delete ...
- Idea中:No converter found for return value of type: class java.util.ArrayList:Json格式转换问题
1.在搞SSM框架的时候,前端发送请求后,显示如下错误. @ResponseBody注解进行返回List<对象>的json数据时出现 nested exception is java.la ...
- 试试Markdown哈
目录 一级标题 二级标题 三级标题 二级标题? 我擦了? 这什么语法.文字下面加-号,实现二级标题? 看看是几级标题 还真的是二级标题. ...... # 看来四个空格是个,嗯,默认的东西 ??中间是 ...
- C# 向程序新建的窗体中添加控件,控件需要先实例化,然后用controls.add添加到新的窗体中去
C# 向程序新建的窗体中添加控件,控件需要先实例化,然后用controls.add添加到新的窗体中去 Form settingForm = new Form(); setForm deviceSet ...
- mybatis 注解的方式批量插入,更新数据
一,当向数据表中插入一条数据时,一般先检查该数据是否已经存在,如果存在更新,不存在则新增 使用关键字 ON DUPLICATE KEY UPDATE zk_device_id为主键 model ...
- Linux:OpenSUSE系统的安装
又过了比较长的时间,基本上都是一周一更了,这期我们就来演示Linux系统中OpenSUSE系统的安装吧! 安装OpenSUSE系统 系统映像文件下载 OpenSUSE 15下载地址: https:// ...
- puthon文件头
#!/usr/bin/u/ubv/a python # -*- coding:utf-8 -*-
- JavaScript几种常见的继承方法
1.call() 方法 call() 方法是与经典的对象冒充方法最相似的方法.它的第一个参数用作 this 的对象.其他参数都直接传递给函数自身 function Huster(name,idNum, ...
- js 防抖 debounce 与 节流 throttle
debounce(防抖) 与 throttle(节流) 主要是用于用户交互处理过程中的性能优化.都是为了避免在短时间内重复触发(比如scrollTop等导致的回流.http请求等)导致的资源浪费问题. ...
- WINDOWS7环境下Informatica的安装[新手]
环境: 操作系统:Windows7(64位): 数据库:Oracle 11g R2: 数据库字符集:UTF-8 一.下载: (参考链接:https://blog.csdn.net/u011031430 ...