Generative Adversarial Nets[BEGAN]
本文来自《BEGAN: Boundary Equilibrium Generative Adversarial Networks》,时间线为2017年3月。是google的工作。
作者提出一个新的均衡执行方法,该方法与从Wasserstein距离导出的loss相结合,用于训练基于自动编码器的GAN。该方法在训练中会平衡生成器和判别器。另外,它提供一个新的近似收敛测度,快而且稳定,且结果质量高。同时作者提出一种控制图像多样性和可视化质量之间权衡的方法。作者专注于图像生成任务,即使在更高分辨率下也能创造视觉质量的新里程碑。
1 引言
GAN现在已经成为一类用于学习数据分布\(p_{model}(x)\)的方法,并提供生成模型可以基于其进行采样。GAN可以生成非常有说服力的图像,比通过逐像素loss的自动编码器生成的图像要有纹理的多。然而GAN仍然面对一些问题:
- 基本很难训练,即使采用了一些技巧[15,16]。
- 正确的超参数选择是关键。
- 控制生成的样本的图像多样性也是很困难的。
- 平衡判别器和生成器之间的收敛也很难:判别器总是在训练开始就容易更收敛.
- GAN容易遭受mode collapse。
提出的启发式正则如批判别(batch discrimination)[16]和排斥正则化器(repelling regularizer)[21]都一定程度缓解这些问题。本文的贡献:
- 一个简单鲁棒的GAN结构,基于标准训练过程更快速和稳定的收敛;
- 一个均衡概念用于平衡生成器和判别器;
- 一个新的控制方法来平衡图像多样性和可视化质量;
- 一个收敛的近似测度。据作者所知,另一个就是Wasserstein GAN。
2 相关工作
DCGAN是首次提出卷积结构来提升可视化质量的。然后基于能量GAN(EBGAN)是一类用于将判别器建模成能量函数的GAN。该变种收敛的更稳定,而且同时也很容易训练和对超参数变化的鲁棒性。
而更早的GAN变种都缺少收敛测度。Wasserstein GAN近来引入的loss来扮演收敛测度。在他们的实现中,代价就是训练更慢了,但是好处就是稳定和更好的模式覆盖。
3 提出的方法
作者使用EBGAN中的自动编码器作为判别器。而典型的GAN是直接匹配数据分布的,作者的方法意在从Wasserstein距离导出的loss匹配自动编码器的loss分布。这目标可以通过使用一个典型GAN目标和额外的均衡项来平衡判别器和生成器达到。作者的方法更容易训练而且相对经典GAN使用的是更简单的神经网络结构。
3.1 自动编码器的Wasserstein距离下界
我们期望研究匹配误差分布的影响,而不是直接匹配样本的分布。 作者首先引入自动编码器的loss,然后计算介于真实的和生成的样本的自动编码器loss分布之间的Wasserstein距离的下限。
首先引入\(\mathcal{L}:\mathbb{R}^{N_x}\mapsto R^+\)作为训练逐像素自动编码器的loss:
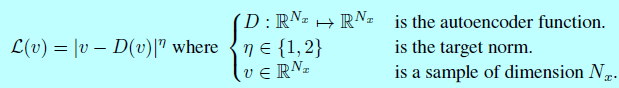
令\(\mu_{1,2}\)作为自动编码器loss的两个分布,令\(\Gamma(\mu_1,\mu_2)\)是所有\(\mu_1\)和\(\mu_2\)的耦合集合,令\(m_{1,2}\in \mathbb{R}\)是他们各自的均值。Wasserstein距离可以表示成:
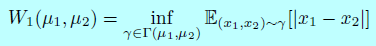
使用Jensen不等式,我们可以得到一个\(W_1(\mu_1,\mu_2)\)的下界:
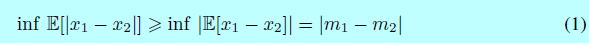
注意的是我们意在最优化介于自动编码器loss分布的Wasserstein距离下界,而不是样本分布。
3.2 GAN目标
作者设计的判别器能够最大化介于自动编码器loss的等式1。令\(\mu_1\)表示loss \(\mathcal{L}(x)\)的分布,其中\(x\)是真实样本。令\(\mu_2\)是loss \(\mathcal{L}(G(z))\)的分布,其中\(G:\mathbb{R}^{N_z}\mapsto \mathbb{R}^{N_x}\)是生成器函数,\(z\in[-1,1]^{N_z}\)是维度为\(N_z\)的均匀随机样本。
因为\(m_1,m_2\in\mathbb{R}^+\)只有2个可能的方案去最大化\(|m_1-m_2|\):
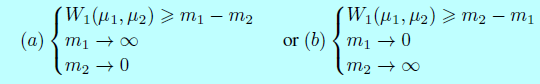
作者选择解决方案(b)作为目标,因为最小化\(m_1\)很自然的自动编码真实的图片。给定判别器和生成器参数\(\theta_D\)和\(\theta_G\),通过最小化\(\mathcal{L}_D\)和\(\mathcal{L}_G\),作者将该问题表示成GAN目标,其中\(z_D\)和\(z_G\)采样自\(z\):
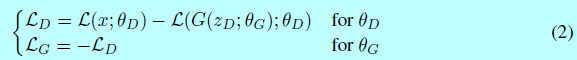
下面,会使用缩写表示法:\(G(\cdot)=G(\cdot,\theta_G)\)和\(mathcal{L}(\cdot)=\mathcal{L}(\cdot;\theta_D)\)。
该式子虽然类似WGAN中的式子,不过还是有2个重要的差别:
- 介于loss之间进行匹配分布,不是介于样本之间;
- 不显式需要判别器是K-Lipschitz,因为这里不是使用的Kantorovich和Rubinstein对偶原理[18]
对于函数近似,我们必须考虑每个函数G和D的表征能力。这是有模型实现的函数和参数量共同决定的。通常的情形是G和D不是很好平衡,判别器D很容易压倒另一方。为了考虑到这种情况,作者引入了均衡概念。
3.3 均衡(Equilibrium)
实际上,平衡生成器和判别器的loss是很关键的;当平衡时:

如果我们生成的样本不能让判别器与真实样本进行区分,则他们错误的分布应该是一样的,当然也包含期望误差。该概念让我们平衡分配给生成器和判别器的影响,让他们谁都赢不了对方。
更进一层,我们可以通过一个新的超参数\(\gamma\in[0,1]\)去自定义均衡的程度,定义如下:

在本文的模型中,判别器有2个竞争的目标:1)自动编码真实图片;2)判别器判别生成的图片和真实图片。\(\gamma\)项让我们能够平衡这2个目标。更低的\(\gamma\)值生成更少的图像多样性,因为判别器更关注自动编码真实图片。作者这里将\(\gamma\)看成是多样性的比率。也存在图像清晰且具有细节的边界。
3.4 边界均衡GAN(Boundary Equilibrium GAN)
BEGAN的目标是:
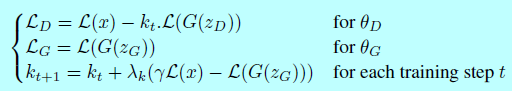
这里使用比例控制论(Proportional Control Theory)来管理均衡\(\mathbb{E}[\mathcal{L}(G(z))]=\gamma\mathbb{E}[\mathcal{L}(x)]\)。这是通过变量\(k_t\in[0,1]\)来控制在梯度下降过程中多少程度重视\(\mathcal{L}(G(z_D))\)。这里初始化\(k_0=0\)。超参数\(\lambda_k\)是\(k\)的比例增益;在机器学习中,它就是\(k\)的学习率。作者使用0.001。本质上,这可以被认为是闭环反馈控制的一种形式,其中在每一步调整\(k_t\)以管理式子4。
在早期训练过程中,G倾向生成自动编码器容易重构的数据,因为此时生成的数据接近0,而真实数据分布还没学习准确。这主要是因为早期是\(\mathcal{L}(x)>\mathcal{L}(G(z))\),这会通过均衡约束在整个训练过程中进行管理。
式子1的近似引入和式子4中\(\gamma\)对Wasserstein距离有很大的影响。后续,评估由各种\(\gamma\)值产生的样本是主要关注点,如下面结果部分所示。
相比传统GAN需要交替训练D和G,或者预训练D。本文提出的BEGAN都不需要。采用Adam和默认的超参数训练即可。\(\theta_D\)和\(\theta_G\)是基于他们各自的loss关于Adam优化器独立更新的,本文中batchsize采用\(n=16\)。
3.4.1 收敛测度
决定GAN的收敛通常是一个困难的任务,因为原始式子是以零和游戏定义的。而且后续训练中会出现一个loss上升,另一个loss下降的情况。epochs的数值或者可视化肉眼检测通常是唯一实际可以感知当前训练程度的方法。
作者提出一个全局收敛测度方式,也是通过使用均衡概念:我们可以构建收敛过程,先找到比例控制算法\(|\gamma\mathcal{L}(x)-\mathcal{L}(G(z_G))|\)的瞬时过程误差,然后找到该误差的最低绝对值的最接近重建\(\mathcal{L}(x)\)。该测度可以形式化为两项的和:
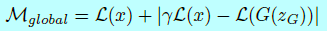
该测度可以用来决定什么时候该网络达到最终态还是该模型已经坍塌。
3.5 模型结构
判别器\(D:\mathbb{R}^{N_x}\mapsto \mathbb{R}^{N_x}\)是基于卷积神经网络的自动编码器。\(N_x=H\times W\times C\)表示\(x\)的维度,其中对应的表示为高,宽,通道。作者将深度编码和解码器共同构建一个自动编码器。意图尽可能简单的避免需要典型GAN的那些技巧。
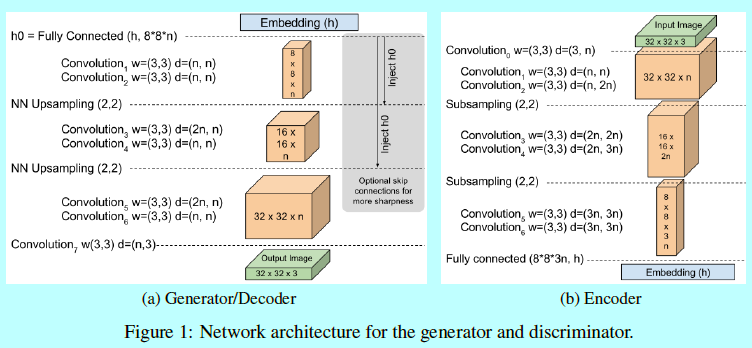
如图1所示,作者使用3x3的卷积和指数线性单元(ELU)作为输出层激活函数。每一层以一定量(通常是2)进行重复。作者实验发现更多的重复会有更好的可视化结果。每次下采样时,卷积滤波器会线性增长。下采样是通过stride=2进行子采样实现的,上采样是通过最近邻实现的。在介于编码器和生成器的边界上,处理的数据的张量通过全连接层进行映射(后面不跟任何非线性函数),嵌入状态为\(h\in\mathbb{R}^{N_h}\),这里\(N_h\)是自动编码器隐藏层的维度。
生成器\(G:\mathbb{R}^{N_z}\mapsto \mathbb{R}^{N_x}\)使用同样的结构(权重不同)作为判别器的解码器。作者选择这个结构纯粹就是因为他简单。输入状态是\(z\in[-1,1]^{N_z}\)是均匀采样。
3.5.1 可选的改善
这个简单结构获得了很好的质量结果,也具有很好的鲁棒性。
此外,还有一些方式有助于梯度传播并生成更清晰的图片。受到深度残差网络的启发,作者通过消失的残差来初始化网络:如连续的同样尺度的层,层的输入是与他的输出相结合的:\(in_{x+1}=carry\times in_x+(1-carry)\times out_x\)。在本文实验中,以\(carry=1\)开始,然后到16000 steps(一个epoch)时逐步减少到0。
同时引入skip连接来帮助梯度传播。第一个解码器张量\(h_0\)是通过将\(h\)映射到一个\(8\times 8\times n\)张量上获取的。在每个上采样step之后,输出与\(h_0\)的上采样以相同维度进行合并。skip连接是基于隐藏层和解码器每个后续上采样层之间建立的。
作者并没有测试经典GAN上的一些方法,如BN,dropout,转置卷积或卷积滤波器指数增长等。
4 实验
4.1 步骤
作者用Adam训练模型,其学习率为0.0001,当收敛测度开始停滞时,以衰减因子为2进行衰减。当以大学习率开始训练时,会观测到模型坍塌或者可视化假图现象,这可以简单的通过减少学习率来避免。作者训练的模型分辨率从32变化到256,增加或者移除卷积层一次来适应图像尺度,保证最终下采样后图片大小为8x8.作者在大部分实验中\(N_hN_z=64\)。
作者为128x128图像的最大模型的卷积有128个滤波器,总共有\(17.3\times 10^6\)个训练参数。在P100 GPU上大概需要训练2.5天。更小的模型如尺度为32x32的,在单块GPU上训练几个小时即可。
作者用360K个名人图像做训练集,以此代替CelebA。该数据集有更多人脸姿态变化,包括相机轴上的角度等等。
4.2 图像多样性和质量
4.3 空间连续性
4.4 收敛测度和图像质量
4.5 不平衡网络的均衡(Equilibrium for unbalanced networks)
4.6 数值实验
reference:
[1] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein gan. arXiv preprint arXiv:1701.07875, 2017.
[2] Sanjeev Arora, Rong Ge, Yingyu Liang, Tengyu Ma, and Yi Zhang. Generalization and equilibrium in generative adversarial nets (gans). arXiv preprint arXiv:1703.00573, 2017.
[3] Yoshua Bengio, Patrice Simard, and Paolo Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE transactions on neural networks, 5(2):157–166, 1994.
[4] Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289, 2015.
[5] Vincent Dumoulin, Ishmael Belghazi, Ben Poole, Alex Lamb, Martin Arjovsky, Olivier Mastropietro, and Aaron Courville. Adversarially learned inference. arXiv preprint arXiv:1606.00704, 2016.
[6] Ian Goodfellow. Nips 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160, 2016.
[7] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
[9] Gao Huang, Zhuang Liu, Kilian Q Weinberger, and Laurens van der Maaten. Densely connected convolutional networks. arXiv preprint arXiv:1608.06993, 2016.
[10] Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[11] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
[12] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), 2015.
[13] Aaron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, and Koray Kavukcuoglu. Conditional image generation with pixelcnn decoders. arXiv preprint arXiv:1606.05328, 2016.
[14] Ben Poole, Alexander A Alemi, Jascha Sohl-Dickstein, and Anelia Angelova. Improved generator objectives for gans. arXiv preprint arXiv:1612.02780, 2016.
[15] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
[16] Tim Salimans, Ian Goodfellow,Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In Advances in Neural Information Processing Systems, pages 2226–2234, 2016.
[17] Rupesh Kumar Srivastava, Klaus Greff, and Jürgen Schmidhuber. Highway networks. arXiv preprint arXiv:1505.00387, 2015.
[18] Cédric Villani. Optimal transport: old and new, volume 338. Springer Science & Business Media, 2008.
[19] D Warde-Farley and Y Bengio. Improving generative adversarial networks with denoising feature matching. ICLR submissions, 8, 2017.
[20] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaolei Huang, Xiaogang Wang, and Dimitris Metaxas. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. arXiv preprint arXiv:1612.03242, 2016.
[21] Junbo Zhao, Michael Mathieu, and Yann LeCun. Energy-based generative adversarial network. arXiv preprint arXiv:1609.03126, 2016.
Generative Adversarial Nets[BEGAN]的更多相关文章
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
- 论文笔记之:Conditional Generative Adversarial Nets
Conditional Generative Adversarial Nets arXiv 2014 本文是 GANs 的拓展,在产生 和 判别时,考虑到额外的条件 y,以进行更加"激烈 ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- 论文笔记之:Generative Adversarial Nets
Generative Adversarial Nets NIPS 2014 摘要:本文通过对抗过程,提出了一种新的框架来预测产生式模型,我们同时训练两个模型:一个产生式模型 G,该模型可以抓住数据分 ...
- Generative Adversarial Nets[CycleGAN]
本文来自<Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks>,时间线为2017 ...
- Generative Adversarial Nets[CAAE]
本文来自<Age Progression/Regression by Conditional Adversarial Autoencoder>,时间线为2017年2月. 该文很有意思,是如 ...
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- Generative Adversarial Nets[Pre-WGAN]
本文来自<towards principled methods for training generative adversarial networks>,时间线为2017年1月,第一作者 ...
- Generative Adversarial Nets[pix2pix]
本文来自<Image-to-Image Translation with Conditional Adversarial Networks>,是Phillip Isola与朱俊彦等人的作品 ...
随机推荐
- xamarin.forms之使用CarouselView插件模仿网易新闻导航
在APP中基本都能见到类似网易.今日头条等上边横向导航条,下边是左右滑动的页面,之前做iOS的时候模仿实现过,https://github.com/ywcui/ViewPagerndicator,在做 ...
- JsonConvert.DeserializeObject反序列化
JObject ci = JsonConvert.DeserializeObject<JObject>(row); string s = ci["txtContent" ...
- [MySQL] explain中的using where和using index
1. 查看表中的所有索引 show index from modify_passwd_log; 有两个 一个是id的主键索引 , 一个是email_id的普通索引 2. using index表示 ...
- PHP中private、public、protected的区别详解
先简单粗俗的描述下:public 表示全局,类内部外部子类都可以访问:private表示私有的,只有本类内部可以使用:protected表示受保护的,只有本类或子类或父类中可以访问: 再啰嗦的解释下: ...
- 轻松搞定RocketMQ入门
RocketMQ是一款分布式.队列模型的消息中间件,具有以下特点: 能够保证严格的消息顺序 提供丰富的消息拉取模式 高效的订阅者水平扩展能力 实时的消息订阅机制 亿级消息堆积能力 RocketMQ网络 ...
- Java对Excel数据处理(利用POI解析Excel)
前言 研究生复试结束我在学校官网上看到了全校按姓氏排列的拟录取名单,但是官网并没有给出每个人的专业,只有学号,另外还知道本专业的复试名单,所以我想知道对于本专业的拟录取名单.具体做法就是,扫描复试名单 ...
- Dynamics Customer Engagement V9版本配置面向Internet的部署时候下一步按钮不可点击的解决办法
微软动态CRM专家罗勇 ,回复299或者20190120可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me . Dynamics 3 ...
- 2018年终总结之AI领域开源框架汇总
2018年终总结之AI领域开源框架汇总 [稍显活跃的第一季度] 2018.3.04——OpenAI公布 “后见之明经验复现(Hindsight Experience Reply, HER)”的开源算法 ...
- window64位电脑如何通过VMware Workstation12.5.6安装苹果操作系统 macOS High Sierra 10.13
1.下载 VMware-workstation-full-12.5.6.exe,macOS High Sierra 10.13.iso 2.安装 VMware-workstation时不要选择C盘,因 ...
- Python+ITchart实现微信中男女比例,城市分布统计并可视化显示
直接上代码: import itchat import os import csv import pandas as pd from pyecharts import Bar,Pie,Geo impo ...