B+树的Copy-on-Write设计
本文主要介绍B+树的Copy-On-Write,包括由来、设计思路和核心源码实现(以Xapian源码为例)。中文的互联网世界里,对B树、B+树的科普介绍很丰富,但对它们在工业界的实际使用却几乎没有相关介绍文章,本文既是总结分享,也是资料索引。
在阅读本文之前需要先对B+树有概念上的认识,可以阅读wiki,也可以看看这两篇简单易懂的中文漫画解读,B-tree,B+tree。
在介绍CoW(Copy-on-Write)之前,首先思考这样一个问题:使用B+树的数据库在提供读、写服务时,如果叶子节点发生了节点分裂,而此时又有读行为,怎么保证读写的线程安全?譬如:准备读取叶子节点leaf时,leaf分裂为leaf和leaf-new两个block,这时候还是读取leaf节点,不就可能导致数据丢失了吗,怎么解决的?
其中的一种解决方法便是CoW B+树(其它解决方法还有:B-link树、加锁后原地更新数据等等),这种方法,也有些文章(见文末参考文献)起了一个抽象层次更高的名字,叫做:shadowing。实现思路:在对数据进行操作(增、删、改)之前,先把所有可能操作到的层级(所有祖先节点)数据块都拷贝一份出来,后面的修改就在这份拷贝后的数据块上做修改,修改完之后再把这些数据块写入到磁盘文件新的位置上,这时候磁盘中就有两份数据,一份是修改之前的,一份是修改之后的,从修改之前的根节点开始遍历,可以读到所有修改之前的旧版数据,从修改之后的新根节点开始遍历,可以读到所有修改之后的新版数据。 从不同的根节点进去可以读取到不同版本的数据,这个CoW既保证了读写安全,也带有很优雅的数据备份功能(数据快照)。
举个实际的例子:在一个有7个节点(block)的B+树中,根节点为A,其叶子节点C有修改操作。把C以及它的祖先节点都拷贝一份:C'、B'、A',然后再在这些新拷贝的节点上修改数据,最后将修改后的数据写入到磁盘文件新的位置上。在这个过程中,如果有业务在读取这颗B+树,仍然可以读取到C、B、A的完整旧数据。等到C'、B'、A'节点的数据刷写到磁盘完毕,再修改这颗B+树的根节点为A',这时业务就能读取到这颗B+树的新数据,此时旧数据A、B、C也仍然存在,可以选择保留作为备份,也可以选择回收磁盘空间。(参考了文末的文章《B-trees, Shadowing, and Clones》)
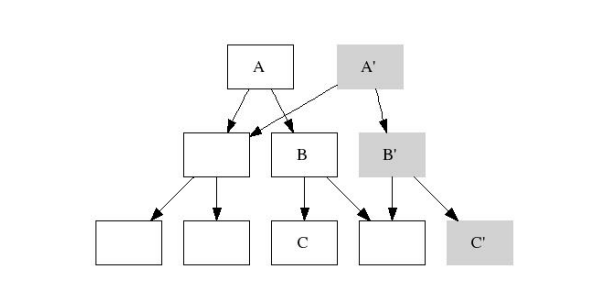
B+树的CoW示例,每一个框代表磁盘中的一个数据块(block)
原理部分介绍完了,很简单吧?
我们来看看Xapian是怎么实现CoW B+树的,因为这是一个大系统里的一部分代码,看不懂也没关系,感兴趣的朋友也可以直接阅读完整源码。
首先是,在修改前的节点拷贝。源码:
void GlassTable::alter() {
LOGCALL_VOID(DB, "GlassTable::alter", NO_ARGS);
Assert(writable);
if (flags & Xapian::DB_DANGEROUS) {
C[].rewrite = true;
return;
}
int j = ;
while (true) {
if (C[j].rewrite) return; /* all new, so return */
C[j].rewrite = true;
glass_revision_number_t rev = REVISION(C[j].get_p());
if (rev == revision_number + ) {
return;
}
Assert(rev < revision_number + );
uint4 n = C[j].get_n();
free_list.mark_block_unused(this, block_size, n); /// 将当前需要被拷贝的block设置为空闲,这个空闲标记要等到新block被刷到磁盘(commit操作)之后才生效
SET_REVISION(C[j].get_modifiable_p(block_size), revision_number + ); /// j层级的游标申请新的内存block,并设置版本号+1
n = free_list.get_block(this, block_size); /// 从空闲块中取一个块号作为新block的块序号(block_size*n也即是这个块在磁盘文件的偏移)
C[j].set_n(n); /// 将块序号设置到游标中
if (j == level) return; /// 如果根节点也已经拷贝完毕,则返回
j++; /// j+1,准备拷贝父节点
BItem_wr(C[j].get_modifiable_p(block_size), C[j].c).set_block_given_by(n); /// 修改当前(j-1)层级的父节点指向新的block,注意:这里修改的也是拷贝后的节点数据
}
}
然后,在新block中修改数据,这块包括了增、删、改,代码比较多,不贴。
最后,将所有的修改提交(commit),这里有顺序要求:1、将游标中所有未持久化的数据写入磁盘;2、在内存中让新根节点生效;3、新根节点以及其它meta信息写入版本文件(也就是记录B+树元信息的文件:iamglass文件)。
部分源码:
void GlassDatabase::apply() {
LOGCALL_VOID(DB, "GlassDatabase::apply", NO_ARGS);
if (!postlist_table.is_modified() &&
!position_table.is_modified() &&
!termlist_table.is_modified() &&
!value_manager.is_modified() &&
!synonym_table.is_modified() &&
!spelling_table.is_modified() &&
!docdata_table.is_modified()) {
return;
}
glass_revision_number_t new_revision = get_next_revision_number();
int flags = postlist_table.get_flags();
try {
set_revision_number(flags, new_revision); /// 这里做了数据写入磁盘、生效新节点数据的操作
} catch (const Xapian::Error &e) {
modifications_failed(new_revision, e.get_description());
throw;
} catch (...) {
modifications_failed(new_revision, "Unknown error");
throw;
}
/// 下面这一票代码,是为了记录修改到changeset文件,changeset文件用于主从节点的增量数据同步
GlassChanges * p;
p = changes.start(new_revision, new_revision + , flags);
version_file.set_changes(p);
postlist_table.set_changes(p);
position_table.set_changes(p);
termlist_table.set_changes(p);
synonym_table.set_changes(p);
spelling_table.set_changes(p);
docdata_table.set_changes(p);
}
以上是CoW B+tree的主要内容。
有朋友可能会有疑问,我就添加几个字节的数据,采用CoW设计,需要拷贝多个数据块,是否太浪费了?确实浪费,所以采用CoW的系统一般都会攒一堆数据之后,再写入到B+树索引中,在尽量保证时效性前提下减少拷贝新数据块、减少写磁盘;另外,对读多写少的业务场景来说,写入时的性能浪费几乎可以忽略,而带来的收益却是读取的高并发,是非常值得的trade-off。
参考《A Short History of the BTree》,CoW B+tree是第三代技术。第四代技术围绕着CoW的更新效率、空间浪费、随机IO这几方面的缺点做了优化,作者称之为“‘stratified B-tree”,相关文章《Stratified B-trees and versioning dictionaries》,后续有时间再做学习。
学习资料:
1、《Xapian源码1.4.10》
2、《how the append-only btree works》介绍如何实现append-only B-tree,非常详细易懂
3、《A Short History of the BTree》B-tree历史介绍
4、《B-tree, Shadowing, and Clones》 很详细的B+树 Shadowing、COW介绍文章
B+树的Copy-on-Write设计的更多相关文章
- dzzoffice的树型结构用户管理设计
在DzzOffice1.1的开发中,针对用户使用群体重新设计了,机构.部门.用户管理应用. 传统OA,企业相关程序,一般是设置机构-设置部门-设置职位-添加用户这样的步骤.每个步骤分为不同的管理界面. ...
- 二叉排序树、平衡二叉树、B树&B+树、红黑树的设计动机、缺陷与应用场景
之前面试时曾被问到"如果实现操作系统的线程调度应该采用什么数据结构?",因为我看过ucore的源码,知道ucore是采用斜堆的方式实现的,可以做到O(n)的插入.O(1)的查找.我 ...
- 关于树的常见操作-C++面试
#include <iostream> using namespace std; //树的存储结构与设计 struct BitNode { int data; BitNode* leftC ...
- 基于HTML5树组件延迟加载技术实现
HT for Web的HTML5树组件有延迟加载的功能,这个功能对于那些需要从服务器读取具有层级依赖关系数据时非常有用,需要获取数据的时候再向服务器发起请求,这样可减轻服务器压力,同时也减少了浏览器的 ...
- HT for Web的HTML5树组件延迟加载技术实现
HT for Web的HTML5树组件有延迟加载的功能,这个功能对于那些需要从服务器读取具有层级依赖关系数据时非常有用,需要获取数据的时候再向服务器发起请求,这样可减轻服务器压力,同时也减少了浏览器的 ...
- python gui之tkinter界面设计pythonic设计
ui的设计,控件id的记录是一件比较繁琐的事情. 此外,赋值和读取数据也比较繁琐,非常不pythonic. 有没有神马办法优雅一点呢?life is short. 鉴于控件有name属性,通过dir( ...
- Indian Scientists Design Device to Collect Solar Energy 印度科学家设计太阳能收集设备
Indian scientists have designed a new device they hope will solve one of the biggest problems with ...
- D&F学数据结构系列——B树(B-树和B+树)介绍
B树 定义:一棵B树T是具有如下性质的有根树: 1)每个节点X有以下域: a)n[x],当前存储在X节点中的关键字数, b)n[x]个关键字本身,以非降序存放,因此key1[x]<=key2[x ...
- 【算法】赫夫曼树(Huffman)的构建和应用(编码、译码)
参考资料 <算法(java)> — — Robert Sedgewick, Kevin Wayne <数据结构> ...
- 《Effective C++》设计与声明:条款18-条款25
条款18:让接口容易被正确使用,不容易被误用 注意使用const,explicit,shared_ptr等来限制接口. 必要时可以创建一些新的类型,限制类型操作,束缚对象等. 注意保持接口的一致性,且 ...
随机推荐
- win下开机不登陆系统自动运行程序的解决方案
文章作者:姜南(Slyar) 文章来源:Slyar Home (www.slyar.com) 转载请注明,谢谢合作. Jet的电脑可以定时开机了,但是他希望XP系统启动后在不登陆用户的情况下运行锐捷和 ...
- 安卓获取签名SHA1
Debug签名:D:\Java\jdk1.8.0_151\bin>keytool -list -v -keystore debug.keystore 无需密码 Relese签名:D:\Java ...
- Set接口下的集合
一.集合(定义字段的时候统一使用包装类) 1.集合大类分为List.Set.Map三种,其中,List集合是有序可重复的,并且可以使用普通for循环.增强for循环.正向迭代器.双向迭代器:Set集合 ...
- 理解WindowManagerService
--摘自<Android进阶解密> *WMS的职责* 1)窗口管理 WMS负责窗口的启动.添加和删除,另外窗口的大小和层级也是由WMS进行管理的 2)窗口动画 WMS的动画子系统Windo ...
- ARP欺骗配置及演示过程
目录 环境 软件 网络拓扑图 配置流程 配置构思 具体流程 问题 演示过程 状态 检查Attack前centOS7_1的ARP地址表 在kali上输入以下命令发动攻击 此时查看centOS7_1的AR ...
- MySQL 栏位修改为区分大小写
) BINARY CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL; ) BINARY CHARACTER SET utf8 COLLATE utf8_ ...
- 我对PMO的理解(持续更新)
PMO的价值 为项目管理提供方法上的指导,对项目的实施过程提供监督.评价. PMO应该从哪方面着手建立管理体系 如何量化工作 如何考评工作 如何激励员工 如何进行人工.成本核算 如何进行进度跟踪与控制 ...
- 英语口语练习系列-C41-食物词汇-鹊桥仙
词汇 1, rice [raɪs] n. 稻:米饭 vt. 把-捣成米糊状 Rice: 米饭 | 大米 | 稻 2, bread [bred] n. 面包:生计 vt. 在-上洒面包屑 Bread: ...
- SpringBoot报错:Invalid bound statement (not found)
错误原因: 没有发现Mybatis配置文件的路径 解决方法: 检查Mapper包名与xml文件标签的namespace数据名称是否相同 <mapper namespace="com.t ...
- C#线程--5.0之前时代(一)--- 原理和基本使用
一.开篇概念明晰: 多任务: 协作式多任务:cpu可以处理多种任务,但是这些任务是排队等候的,当cpu在处理一个任务的时候,其他的任务被锁定,只有当cpu处理完当前任务,才可以继续处理下一个任务(专一 ...