使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻
依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻
以下是搜索页面,得到吉林疫苗的搜索信息,里面包含了新闻信息和视频信息
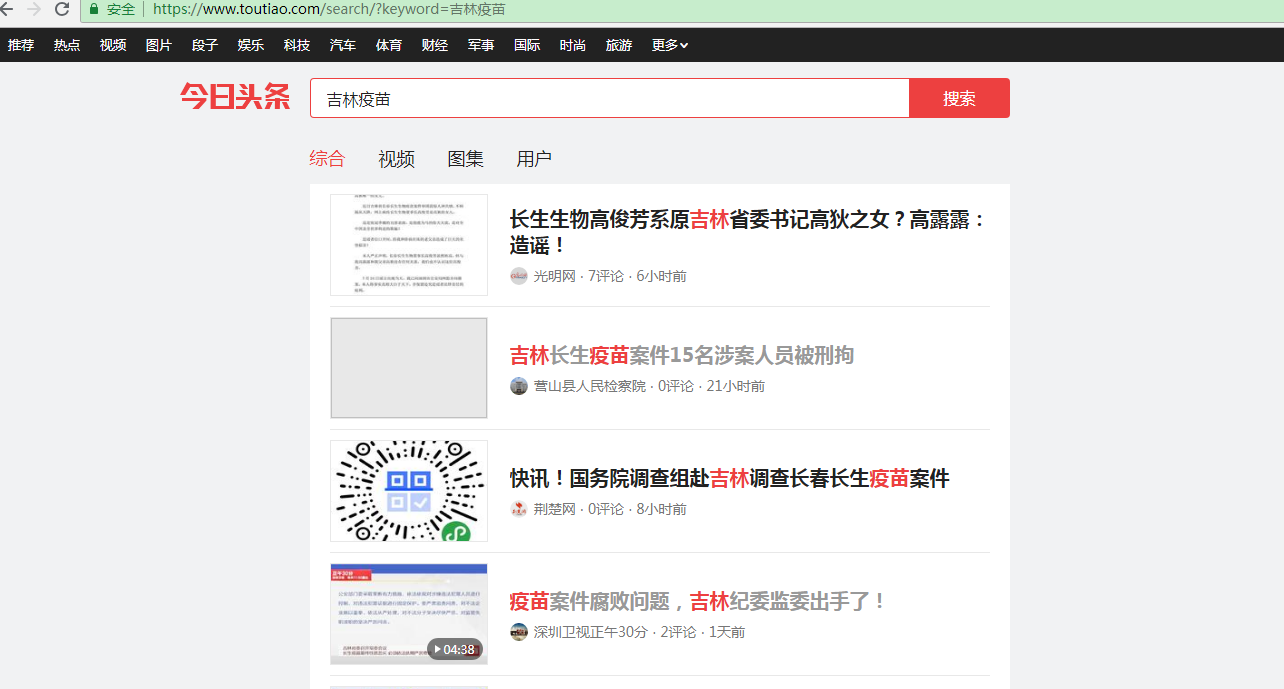
通过F12中network得到了接口url信息:https://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E5%90%89%E6%9E%97%E7%96%AB%E8%8B%97&autoload=true&count=20&cur_tab=1&from=search_tab
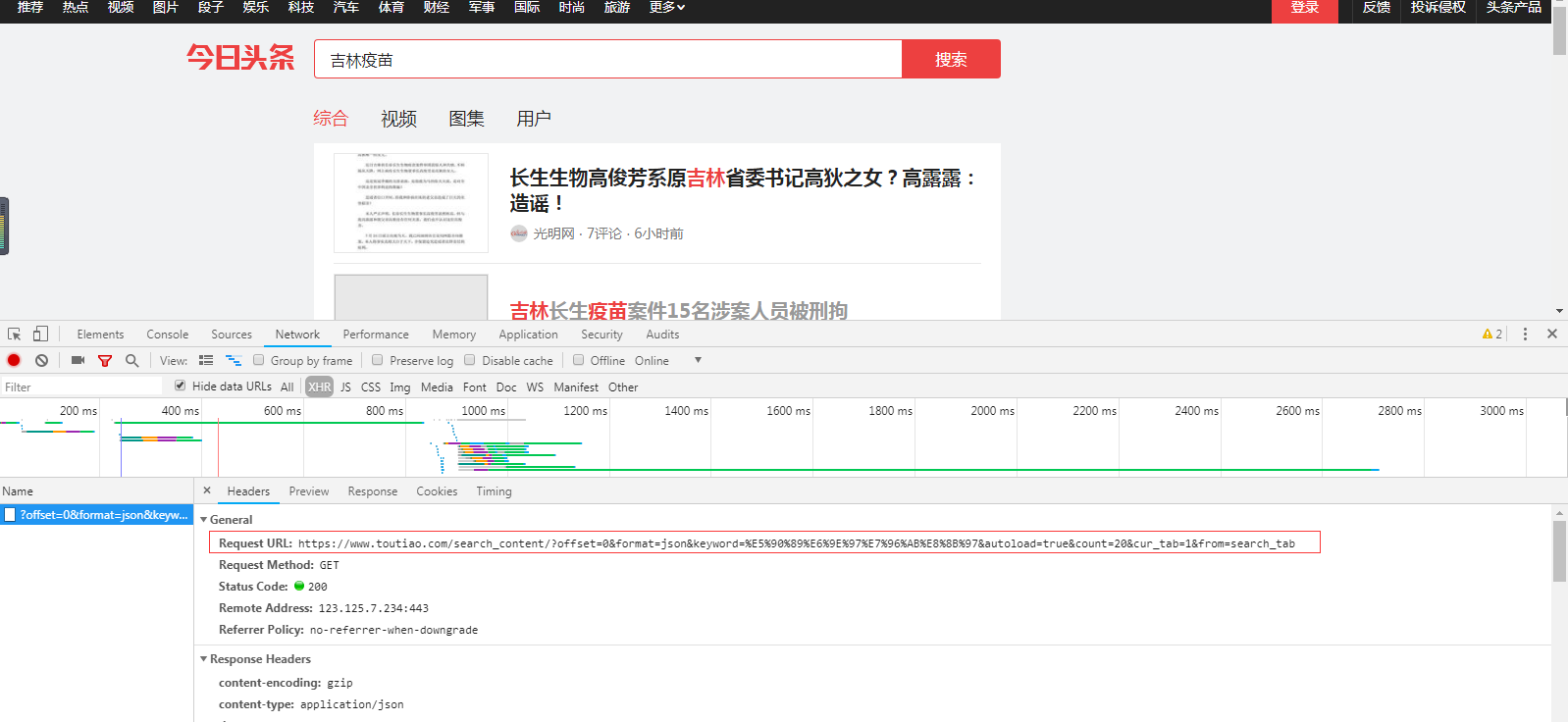
在Postman里面访问接口信息得到json信息(信息里面包含了文章的标题和链接)
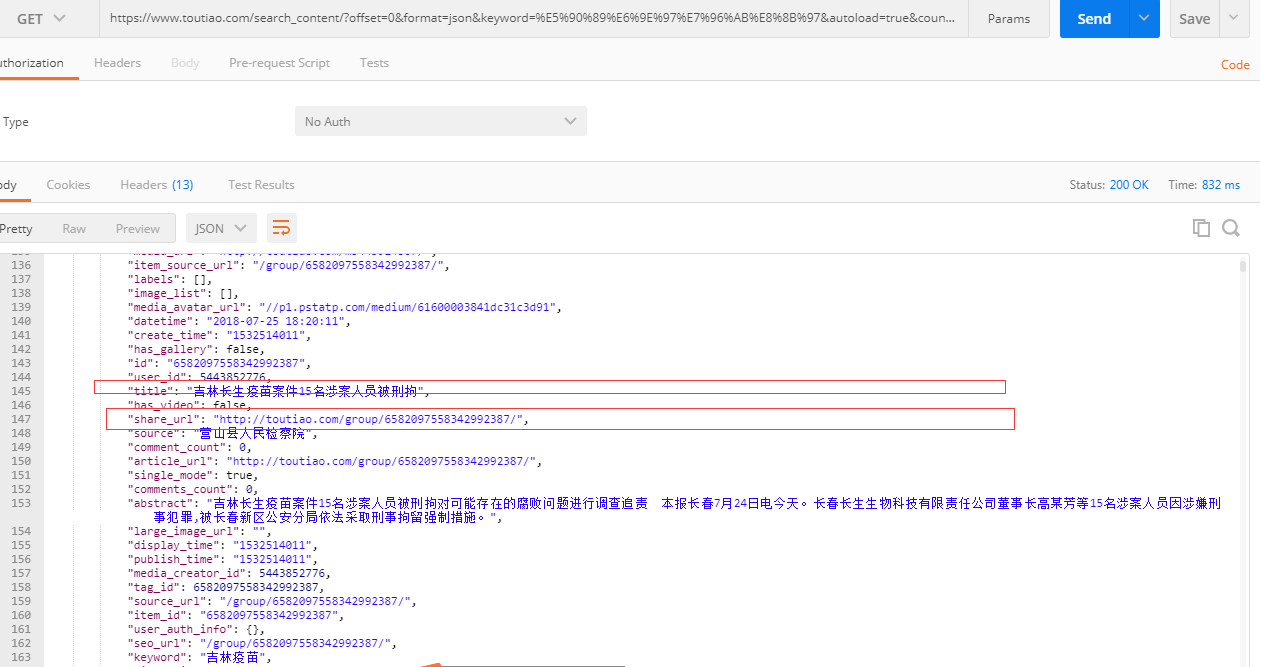
基于这些信息来开发爬虫核心代码
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
import time
import json
from toutiao.items import ToutiaoItem class ToutiaoSerachSpider(scrapy.Spider):
name = 'toutiao_serach'
allowed_domains = ['toutiao.com']
###接口信息,这里为了方便把 &keyword= 挪到了最后边
start_urls = ['https://www.toutiao.com/search_content/?offset=0&format=json&autoload=true&count=20&cur_tab=1&from=search_tab&keyword='] def parse(self, response):
new_key_word=response.url+'吉林疫苗'
yield scrapy.Request(new_key_word,callback=self.main_parse) def main_parse(self,response):
search_content_data=json.loads(response.text)
for aa in search_content_data['data']:
if 'open_url' in aa.keys() and 'play_effective_count'not in aa.keys(): ### 去除搜索后得到的综合里面 保留文章信息类型,去除视频信息类型
yield scrapy.Request(aa['article_url'],callback=self.content_parse) def content_parse(self,response): driver = webdriver.PhantomJS()
driver.get(response.url)
time.sleep(3)
title = driver.find_element_by_class_name('article-title').text
content=driver.find_element_by_class_name('article-content').text item=ToutiaoItem()
item['title'] =title
item['content']=content yield item
最后得到新闻信息

使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)的更多相关文章
- 使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面 查看源代码你会发现 全是js代码,说明今日头条的内容是通过js动态生成的. 用火狐浏览器F12查看得知 ...
- Python 爬虫爬取今日头条街拍上的图片
# 今日头条--街拍 import requests from urllib.parse import urlencode import os from hashlib import md5 from ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- 爬虫七之分析Ajax请求并爬取今日头条
爬取今日头条图片 这里只讨论出现的一些问题,代码在最下面github链接里. 首先,今日头条取消了"图集"这一选项,因此对于爬虫来说效率降低了很多: 在所有代码都完成后,也许是爬取 ...
- Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- 用Ajax爬取今日头条图片集
Ajax原理 在用requests抓取页面时,得到的结果可能和浏览器中看到的不一样:在浏览器中可以正常显示的页面数据,但用requests得到的结果并没有.这是因为requests获取的都是原始 ...
随机推荐
- 关于vue build时一直报错
真鸡儿坑,截图说下是什么错: 像上面这种,一大堆,看不出具体是为什么,然后根据网上搜到的教程注释了webpack.base.conf.js里的某一行: 重新build,成功.......... 醉了啊 ...
- Django的Models字段含义
在model中添加字段的格式一般为: field_name = field_type(**field_options) 一 field options(所有字段共用) 1 null 默认为F ...
- python + django + echart 构建中型项目
1. python生产环境, 多层modules 导入问题: 多个modules 如何导入不同级别的包: 在每个modules下新建 __init__.pyimport os, sys dir_myt ...
- this直接加在函数或者是 “原型”对象的区别
如果加在函数上,可以用函数直接调用,如果是加在原型对象时,那就的创建新对象,才能使用,最重要的是影响继承 直接加在函数上的,不能被新对象继承
- CLOUD配置审批流发消息
1.进入流程中心-工作流-流程设计中心 2.新增物料管理冻结流程 3.进入修改配置项 4.新消息节点 5.写入消息标题,内容等 6.填入接收人 7.保存后发布 8.进入流程配置中心 9.捆绑并启用 1 ...
- router-link RangeError: Maximum call stack size exceeded
报错的原因是路由不能写外部链接 写成<a href=""></a>
- 使用FindBugs寻找bug,代码分析
安装就不说了,网上很多. 一些常见的错误信息 Bad practice 代码中的一些坏习惯 Class names should start with an upper case letter 主要包 ...
- Python之Mock的入门
参考文章: https://segmentfault.com/a/1190000002965620 一.Mock是什么 Mock这个词在英语中有模拟的这个意思,因此我们可以猜测出这个库的主要功能是模拟 ...
- BZOJ 1855 股票交易 (算竞进阶习题)
单调队列优化dp dp真的是难..不看题解完全不知道状态转移方程QAQ 推出方程后发现是关于j,k独立的多项式,所以可以单调队列优化.. #include <bits/stdc++.h> ...
- [RPM,YUM]RHEL Centos mount local source / RHEL CentOS挂载本地源
RHEL: 使用YUM安装Oracle必要软件包,将操作系统ISO文件“rhel-server-6.5-x86_64.iso”分别上传至两个节点主机“/root”目录,以root用户登录,执行以下命令 ...