windows版influxDB安装与配置
一、下载链接https://portal.influxdata.com/downloads,选windows版

二、解压到安装盘,目录如下
三、修改conf文件,代码如下,直接复制粘贴(1.4.2版本),注意修改路径,带D盘的改为你的安装路径就好,一共三个,注意网上有配置admin进行web管理,但新版本配置文件里没有admin因为官方给删除了,需下载Chronograf,后文会介绍
### Welcome to the InfluxDB configuration file. # The values in this file override the default values used by the system if
# a config option is not specified. The commented out lines are the configuration
# field and the default value used. Uncommenting a line and changing the value
# will change the value used at runtime when the process is restarted. # Once every 24 hours InfluxDB will report usage data to usage.influxdata.com
# The data includes a random ID, os, arch, version, the number of series and other
# usage data. No data from user databases is ever transmitted.
# Change this option to true to disable reporting.
# reporting-disabled = false # Bind address to use for the RPC service for backup and restore.
# bind-address = "127.0.0.1:8088" ###
### [meta]
###
### Controls the parameters for the Raft consensus group that stores metadata
### about the InfluxDB cluster.
### [meta]
# Where the metadata/raft database is stored
dir = "D:/influxdb-1.4.2-1/meta" # Automatically create a default retention policy when creating a database.
retention-autocreate = true # If log messages are printed for the meta service
logging-enabled = true ###
### [data]
###
### Controls where the actual shard data for InfluxDB lives and how it is
### flushed from the WAL. "dir" may need to be changed to a suitable place
### for your system, but the WAL settings are an advanced configuration. The
### defaults should work for most systems.
### [data]
# The directory where the TSM storage engine stores TSM files.
dir = "D:/influxdb-1.4.2-1/data" # The directory where the TSM storage engine stores WAL files.
wal-dir = "D:/influxdb-1.4.2-1/wal" # The amount of time that a write will wait before fsyncing. A duration
# greater than 0 can be used to batch up multiple fsync calls. This is useful for slower
# disks or when WAL write contention is seen. A value of 0s fsyncs every write to the WAL.
# Values in the range of 0-100ms are recommended for non-SSD disks.
# wal-fsync-delay = "0s" # The type of shard index to use for new shards. The default is an in-memory index that is
# recreated at startup. A value of "tsi1" will use a disk based index that supports higher
# cardinality datasets.
# index-version = "inmem" # Trace logging provides more verbose output around the tsm engine. Turning
# this on can provide more useful output for debugging tsm engine issues.
# trace-logging-enabled = false # Whether queries should be logged before execution. Very useful for troubleshooting, but will
# log any sensitive data contained within a query.
query-log-enabled = true # Settings for the TSM engine # CacheMaxMemorySize is the maximum size a shard's cache can
# reach before it starts rejecting writes.
# Valid size suffixes are k, m, or g (case insensitive, 1024 = 1k).
# Vaues without a size suffix are in bytes.
# cache-max-memory-size = "1g" # CacheSnapshotMemorySize is the size at which the engine will
# snapshot the cache and write it to a TSM file, freeing up memory
# Valid size suffixes are k, m, or g (case insensitive, 1024 = 1k).
# Values without a size suffix are in bytes.
# cache-snapshot-memory-size = "25m" # CacheSnapshotWriteColdDuration is the length of time at
# which the engine will snapshot the cache and write it to
# a new TSM file if the shard hasn't received writes or deletes
# cache-snapshot-write-cold-duration = "10m" # CompactFullWriteColdDuration is the duration at which the engine
# will compact all TSM files in a shard if it hasn't received a
# write or delete
# compact-full-write-cold-duration = "4h" # The maximum number of concurrent full and level compactions that can run at one time. A
# value of 0 results in 50% of runtime.GOMAXPROCS(0) used at runtime. Any number greater
# than 0 limits compactions to that value. This setting does not apply
# to cache snapshotting.
# max-concurrent-compactions = 0 # The maximum series allowed per database before writes are dropped. This limit can prevent
# high cardinality issues at the database level. This limit can be disabled by setting it to
# 0.
# max-series-per-database = 1000000 # The maximum number of tag values per tag that are allowed before writes are dropped. This limit
# can prevent high cardinality tag values from being written to a measurement. This limit can be
# disabled by setting it to 0.
# max-values-per-tag = 100000 ###
### [coordinator]
###
### Controls the clustering service configuration.
### [coordinator]
# The default time a write request will wait until a "timeout" error is returned to the caller.
# write-timeout = "10s" # The maximum number of concurrent queries allowed to be executing at one time. If a query is
# executed and exceeds this limit, an error is returned to the caller. This limit can be disabled
# by setting it to 0.
# max-concurrent-queries = 0 # The maximum time a query will is allowed to execute before being killed by the system. This limit
# can help prevent run away queries. Setting the value to 0 disables the limit.
# query-timeout = "0s" # The time threshold when a query will be logged as a slow query. This limit can be set to help
# discover slow or resource intensive queries. Setting the value to 0 disables the slow query logging.
# log-queries-after = "0s" # The maximum number of points a SELECT can process. A value of 0 will make
# the maximum point count unlimited. This will only be checked every second so queries will not
# be aborted immediately when hitting the limit.
# max-select-point = 0 # The maximum number of series a SELECT can run. A value of 0 will make the maximum series
# count unlimited.
# max-select-series = 0 # The maxium number of group by time bucket a SELECT can create. A value of zero will max the maximum
# number of buckets unlimited.
# max-select-buckets = 0 ###
### [retention]
###
### Controls the enforcement of retention policies for evicting old data.
### [retention]
# Determines whether retention policy enforcement enabled.
enabled = true # The interval of time when retention policy enforcement checks run.
check-interval = "30m" ###
### [shard-precreation]
###
### Controls the precreation of shards, so they are available before data arrives.
### Only shards that, after creation, will have both a start- and end-time in the
### future, will ever be created. Shards are never precreated that would be wholly
### or partially in the past. [shard-precreation]
# Determines whether shard pre-creation service is enabled.
enabled = true # The interval of time when the check to pre-create new shards runs.
check-interval = "10m" # The default period ahead of the endtime of a shard group that its successor
# group is created.
advance-period = "30m" ###
### Controls the system self-monitoring, statistics and diagnostics.
###
### The internal database for monitoring data is created automatically if
### if it does not already exist. The target retention within this database
### is called 'monitor' and is also created with a retention period of 7 days
### and a replication factor of 1, if it does not exist. In all cases the
### this retention policy is configured as the default for the database. [monitor]
# Whether to record statistics internally.
store-enabled = true # The destination database for recorded statistics
store-database = "_internal" # The interval at which to record statistics
store-interval = "10s" ###
### [http]
###
### Controls how the HTTP endpoints are configured. These are the primary
### mechanism for getting data into and out of InfluxDB.
### [http]
# Determines whether HTTP endpoint is enabled.
enabled = true # The bind address used by the HTTP service.
bind-address = ":8086" # Determines whether user authentication is enabled over HTTP/HTTPS.
# auth-enabled = false # The default realm sent back when issuing a basic auth challenge.
# realm = "InfluxDB" # Determines whether HTTP request logging is enabled.
# log-enabled = true # Determines whether detailed write logging is enabled.
# write-tracing = false # Determines whether the pprof endpoint is enabled. This endpoint is used for
# troubleshooting and monitoring.
# pprof-enabled = true # Determines whether HTTPS is enabled.
# https-enabled = false # The SSL certificate to use when HTTPS is enabled.
# https-certificate = "/etc/ssl/influxdb.pem" # Use a separate private key location.
# https-private-key = "" # The JWT auth shared secret to validate requests using JSON web tokens.
# shared-secret = "" # The default chunk size for result sets that should be chunked.
# max-row-limit = 0 # The maximum number of HTTP connections that may be open at once. New connections that
# would exceed this limit are dropped. Setting this value to 0 disables the limit.
# max-connection-limit = 0 # Enable http service over unix domain socket
# unix-socket-enabled = false # The path of the unix domain socket.
# bind-socket = "/var/run/influxdb.sock" # The maximum size of a client request body, in bytes. Setting this value to 0 disables the limit.
# max-body-size = 25000000 ###
### [ifql]
###
### Configures the ifql RPC API.
### [ifql]
# Determines whether the RPC service is enabled.
# enabled = true # Determines whether additional logging is enabled.
# log-enabled = true # The bind address used by the ifql RPC service.
# bind-address = ":8082" ###
### [subscriber]
###
### Controls the subscriptions, which can be used to fork a copy of all data
### received by the InfluxDB host.
### [subscriber]
# Determines whether the subscriber service is enabled.
# enabled = true # The default timeout for HTTP writes to subscribers.
# http-timeout = "30s" # Allows insecure HTTPS connections to subscribers. This is useful when testing with self-
# signed certificates.
# insecure-skip-verify = false # The path to the PEM encoded CA certs file. If the empty string, the default system certs will be used
# ca-certs = "" # The number of writer goroutines processing the write channel.
# write-concurrency = 40 # The number of in-flight writes buffered in the write channel.
# write-buffer-size = 1000 ###
### [[graphite]]
###
### Controls one or many listeners for Graphite data.
### [[graphite]]
# Determines whether the graphite endpoint is enabled.
# enabled = false
# database = "graphite"
# retention-policy = ""
# bind-address = ":2003"
# protocol = "tcp"
# consistency-level = "one" # These next lines control how batching works. You should have this enabled
# otherwise you could get dropped metrics or poor performance. Batching
# will buffer points in memory if you have many coming in. # Flush if this many points get buffered
# batch-size = 5000 # number of batches that may be pending in memory
# batch-pending = 10 # Flush at least this often even if we haven't hit buffer limit
# batch-timeout = "1s" # UDP Read buffer size, 0 means OS default. UDP listener will fail if set above OS max.
# udp-read-buffer = 0 ### This string joins multiple matching 'measurement' values providing more control over the final measurement name.
# separator = "." ### Default tags that will be added to all metrics. These can be overridden at the template level
### or by tags extracted from metric
# tags = ["region=us-east", "zone=1c"] ### Each template line requires a template pattern. It can have an optional
### filter before the template and separated by spaces. It can also have optional extra
### tags following the template. Multiple tags should be separated by commas and no spaces
### similar to the line protocol format. There can be only one default template.
# templates = [
# "*.app env.service.resource.measurement",
# # Default template
# "server.*",
# ] ###
### [collectd]
###
### Controls one or many listeners for collectd data.
### [[collectd]]
# enabled = false
# bind-address = ":25826"
# database = "collectd"
# retention-policy = ""
#
# The collectd service supports either scanning a directory for multiple types
# db files, or specifying a single db file.
# typesdb = "/usr/local/share/collectd"
#
# security-level = "none"
# auth-file = "/etc/collectd/auth_file" # These next lines control how batching works. You should have this enabled
# otherwise you could get dropped metrics or poor performance. Batching
# will buffer points in memory if you have many coming in. # Flush if this many points get buffered
# batch-size = 5000 # Number of batches that may be pending in memory
# batch-pending = 10 # Flush at least this often even if we haven't hit buffer limit
# batch-timeout = "10s" # UDP Read buffer size, 0 means OS default. UDP listener will fail if set above OS max.
# read-buffer = 0 # Multi-value plugins can be handled two ways.
# "split" will parse and store the multi-value plugin data into separate measurements
# "join" will parse and store the multi-value plugin as a single multi-value measurement.
# "split" is the default behavior for backward compatability with previous versions of influxdb.
# parse-multivalue-plugin = "split"
###
### [opentsdb]
###
### Controls one or many listeners for OpenTSDB data.
### [[opentsdb]]
# enabled = false
# bind-address = ":4242"
# database = "opentsdb"
# retention-policy = ""
# consistency-level = "one"
# tls-enabled = false
# certificate= "/etc/ssl/influxdb.pem" # Log an error for every malformed point.
# log-point-errors = true # These next lines control how batching works. You should have this enabled
# otherwise you could get dropped metrics or poor performance. Only points
# metrics received over the telnet protocol undergo batching. # Flush if this many points get buffered
# batch-size = 1000 # Number of batches that may be pending in memory
# batch-pending = 5 # Flush at least this often even if we haven't hit buffer limit
# batch-timeout = "1s" ###
### [[udp]]
###
### Controls the listeners for InfluxDB line protocol data via UDP.
### [[udp]]
# enabled = false
# bind-address = ":8089"
# database = "udp"
# retention-policy = "" # These next lines control how batching works. You should have this enabled
# otherwise you could get dropped metrics or poor performance. Batching
# will buffer points in memory if you have many coming in. # Flush if this many points get buffered
# batch-size = 5000 # Number of batches that may be pending in memory
# batch-pending = 10 # Will flush at least this often even if we haven't hit buffer limit
# batch-timeout = "1s" # UDP Read buffer size, 0 means OS default. UDP listener will fail if set above OS max.
# read-buffer = 0 ###
### [continuous_queries]
###
### Controls how continuous queries are run within InfluxDB.
### [continuous_queries]
# Determines whether the continuous query service is enabled.
# enabled = true # Controls whether queries are logged when executed by the CQ service.
# log-enabled = true # Controls whether queries are logged to the self-monitoring data store.
# query-stats-enabled = false # interval for how often continuous queries will be checked if they need to run
# run-interval = "1s"
四、使配置生效并打开数据库连接,双击influxd.exe就好,然后双击influx.exe进行操作,网上有操作教程,注意操作数据库时不能关闭influxd.exe,我不知道为什么总有这么个提示:There was an error writing history file: open : The system cannot find the file specified.不过好像没啥影响
五、要使用web管理需要下载Chronograf,https://portal.influxdata.com/downloads第三个就是,下载完直接解压,双击exe程序,在浏览器输入http://localhost:8888/,一开始登录要账户密码,我都用admin就进去了
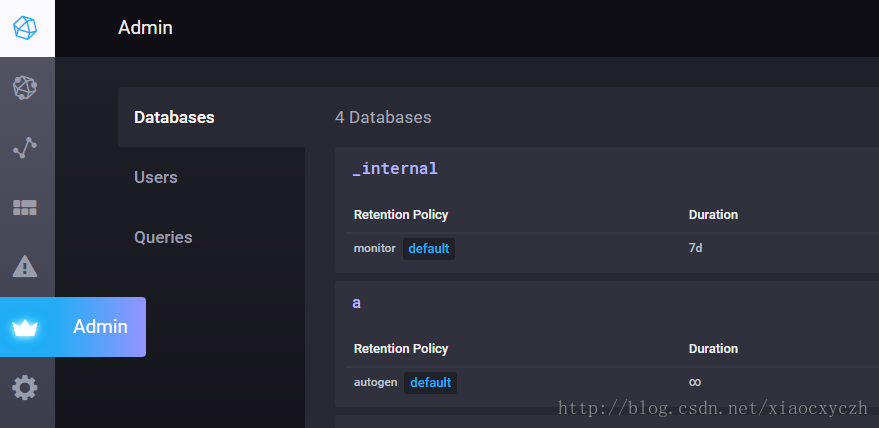
这个是查看建立的数据库
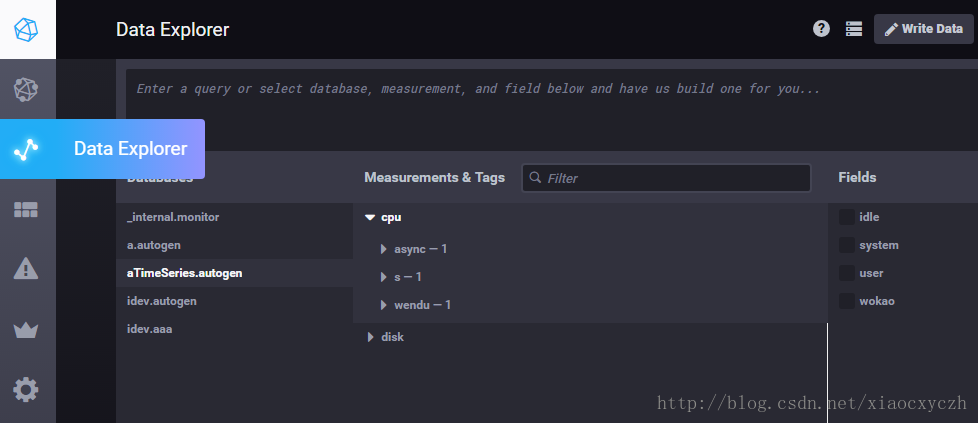
这个是查看数据库的数据
没了
转发自:https://blog.csdn.net/xiaocxyczh/article/details/78682211
windows版influxDB安装与配置的更多相关文章
- windows下手动安装和配置xamarin
安装xamarin xamarin官方给出了两种安装方式,自动安装和手动安装. 自动安装比较简单,到http://xamarin.com/download下载xamarininstaller.exe ...
- Windows下pry安装和配置
Windows下pry安装和配置 pry是一个增强型的交互式命令行工具,比irb强大. 有自动完成功能,自动缩进,有颜色.有更强大的调试功能. pry 安装很简单. 在终端输入: gem instal ...
- InfluxDB安装及配置
这是我之前整理的InfluxDB安装及配置的笔记,这里记录下,也方便我以后查阅. 环境: CentOS6.5_x64 InfluxDB版本:1.1.0 一.安装 1.二进制安装 这里以centos6. ...
- windows下redis安装和配置
windows下redis安装和配置 redis介绍 Redis是一个开源,高级的键值存储和一个适用的解决方案,用于构建高性能,可扩展的Web应用程序. Redis有三个主要特点,使它优越于其它键值数 ...
- [InfluxDB] 安装与配置
[InfluxDB] 安装与配置 1- 下载 ubtuntu: wget https://dl.influxdata.com/influxdb/releases/influxdb_1.5.2_amd6 ...
- 在Windows平台下安装与配置Memcached及C#使用方法
1.在Windows下安装Memcached 资料来源:http://www.jb51.net/article/30334.htm 在Windows平台下安装与配置Memcached的方法,Memca ...
- solr在windows下的安装及配置
solr在windows下的安装及配置 首先,solr是基于Java开发的,所以使用的话需要先进行java环境的配置,在Java环境配置好之后就可以去http://www.apache.org/dyn ...
- Lua在Windows下的安装、配置、运行
Lua在Windows下的安装.配置.运行 本文链接:https://blog.csdn.net/ChinarCSDN/article/details/78667262 展开 # Windows下安装 ...
- Mysql 5.7.12解压版的安装及配置系统编码
这篇博文是由于上篇EF+MySql博文引发的,上篇博文中在Seed方法中插入中文数据到Mysql数据库中乱码,后来网上找了N种方法也没解决.重装了MySql并在安装过程中配置了系统编码,此篇记录一下. ...
随机推荐
- elasticsearch+logstash_jdbc 实现mysql数据实时同步至es
jdk安装1.8版本,es.ls.ik.kibana版本一致我这里使用的6.6.2版本 安装es tar xf elasticsearch-6.6.2.tar.gz mv elasticsearch- ...
- cssselector元素定位
转自https://blog.csdn.net/qq_40024178/article/details/78945651 一.概述 cssSelector也是一种常用的选择器,CSS locator比 ...
- linux下的缓存机制及清理buffer/cache/swap的方法梳理 (转)
一.缓存机制介绍 在Linux系统中,为了提高文件系统性能,内核利用一部分物理内存分配出缓冲区,用于缓存系统操作和数据文件,当内核收到读写的请求时,内核先去缓存区找是否有请求的数据,有就直接返回,如果 ...
- LOJ 2409「THUPC 2017」小 L 的计算题 / Sum
思路 和玩游戏一题类似 定义\(A_k(x)=\sum_{i=0}^\infty a_k^ix^i=\frac{1}{1-a_kx}\) 用\(\ln 'x\)代替\(\frac{1}{x}\), 所 ...
- hdu2159 FATE----完全背包
标准完全背包板子,动态方程为dp[j][x]=max(dp[j][x],dp[j-c[i]][x-1]+a[i]); 其中,dp[j][x]表示花费j点耐心杀x个怪所能得到的最大经验值. 具体代码如下 ...
- 【HNOI 2017】大佬
Problem Description 人们总是难免会碰到大佬.他们趾高气昂地谈论凡人不能理解的算法和数据结构,走到任何一个地方,大佬的气场就能让周围的人吓得瑟瑟发抖,不敢言语.你作为一个 OIer, ...
- 15_Raid及mdadm命令 _LVM
磁盘管理: 机械式硬盘: U盘,光盘,软盘,硬件,磁带 ln [ -s -v ] SRC DEST 硬链接: 1.只能对文件创建,不能应用于目录 2.不能跨文件系统 ...
- 防cc攻击策略
黑客攻击你的网站,会采取各种各样的手段,其中为了降低你网站的访问速度,甚至让你的服务器瘫痪,它会不断的刷新你的网站,或者模拟很多用户同一时间大量的访问你的网站, 这就是所谓的CC攻击,这就需要我们在程 ...
- 在 Laravel 项目中使用 Elasticsearch 做引擎,scout 全文搜索(小白出品, 绝对白话)
项目中需要搜索, 所以从零开始学习大家都在用的搜索神器 elasiticsearch. 刚开始 google 的时候, 搜到好多经验贴和视频(中文的, 英文的), 但是由于是第一次接触, 一点概念都没 ...
- 爬坑之路---Google map
google.maps.event.adddDomListen(window, 'load', callback);当文档流中所有的dom加载完成后,执行回调函数,可以不用在script中使用defe ...