spring源码解析2--容器的基本实现
spring的主要特性是IOC,实现IOC的关键是bean,而更关键的是如何bean的管理容器,也就是BeanFactory,本文的目标是弄清楚BeanFactory具体是怎么样的存在。
先看下最简单的获取bean的案例,代码如下:
public static void main(String[] args){
BeanFactory factory = new XmlBeanFactory(new ClassPathResource("spring-beans.xml"));
User user = (User) factory.getBean("user");
System.out.println(JSON.toJSON(user).toString());
}
首先是读取spring的配置文件,创建BeanFactory实例,如何直接从BeanFactory实例中获取指定名称的bean。接下来就从这几行简单的代码入手,分析下BeanFactory。
BeanFactory实例是通过XmlBeanFactory来创建的,很明显XmlBeanFactory是BeanFactory的子类,继承关系图如下:
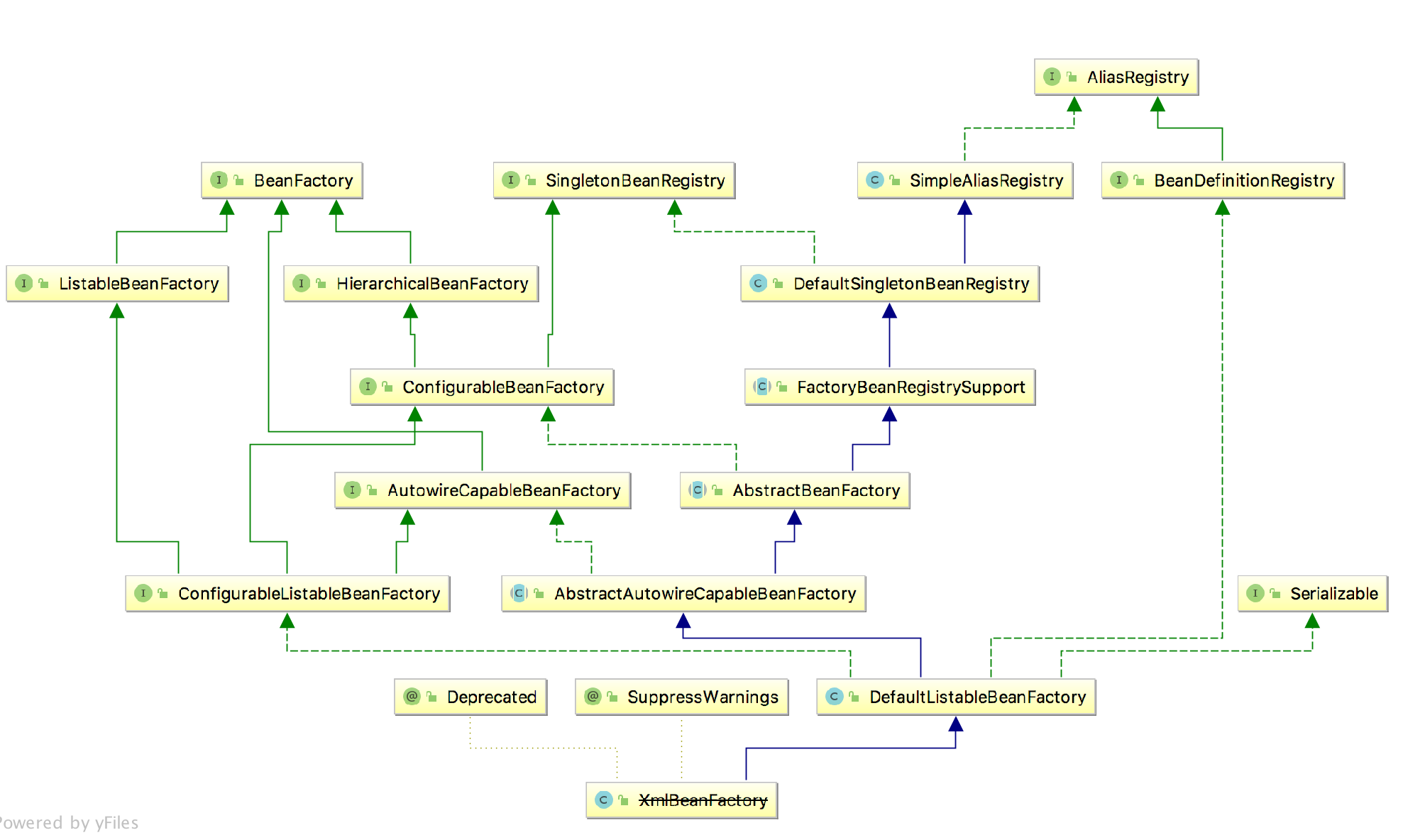
那么先就从XmlBeanFactory的构造方法开始,源码如下:
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}
}
第5行的构造方法调用第9行的构造方法,首先是执行父类的构造方法,然后执行XmlBeanFefinitionReader的loadBeanFefinitions(resource)方法,这个方法显然就是加载bean配置文件的方法。接下来跟踪查看,源码如下:
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
通过EncodeResource来封装Resource,在调用重载的方法
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
//校验Resource参数
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
//获取Resource的InputSteam流
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
//通过InputSteam构造InputSource
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
//最终执行doLoadBeanDefinitions方法
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
这次封装的EncodedResource作用主要是对XML配置文件的编码格式进行处理,然后最终执行了doLoadBeanDefinitions方法
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
//通过InputSource和Resource得到一个Document对象,然后执行注册bean的方法
Document doc = doLoadDocument(inputSource, resource);
return registerBeanDefinitions(doc, resource);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
该方法只有两行有效逻辑代码,首先是加载XML文件得到一个Document对象,然后根据Document对象来注册Bean信息,一步步来看,先看如何生成Document对象。
private DocumentLoader documentLoader = new DefaultDocumentLoader();
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
调用了DocumentLoader的实例来进行加载,DocumentLoader接口的loadDocument方法
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception { //这里显然是工厂模式+建造者模式,先创建DocumentBuilder工厂,如何得到DocumentBuilder,最终执行parse方法解析xml配置文件得到Document对象
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}
public Document parse(InputSource is) throws SAXException, IOException {
if (is == null) {
throw new IllegalArgumentException(
DOMMessageFormatter.formatMessage(DOMMessageFormatter.DOM_DOMAIN,
"jaxp-null-input-source", null));
}
if (fSchemaValidator != null) {
if (fSchemaValidationManager != null) {
fSchemaValidationManager.reset();
fUnparsedEntityHandler.reset();
}
resetSchemaValidator();
}
//上面的代码都是校验,核心是下面的三行,通过DomParser来获取Document对象
domParser.parse(is);
Document doc = domParser.getDocument();
domParser.dropDocumentReferences();
return doc;
}
解析配置文件得到了Document对象,接下来就是通过Document来注册beanl了。回到XmlBeanDefinitionReader的RegisterBeanDefinitions方法
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//创建BeanDefinitionDocumentReader实例
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//统计当前已经加载过的BeanDefinition个数
int countBefore = getRegistry().getBeanDefinitionCount();
//加载及注册bean
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//得到本次加载的BeanFinition个数
return getRegistry().getBeanDefinitionCount() - countBefore;
}
核心是BeanDefinitionDocumentReader接口的registerBeanDefinitions方法,代码如下:
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
首先是获取Document的root,然后将root元素传递给下面的方法继续执行,这里的root元素就是配置文件中的<beans>标签
protected void doRegisterBeanDefinitions(Element root) {
//专门处理解析
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
//处理<beans>标签中的profile属性
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
preProcessXml(root);//代码为空(模板方法设计模式:提供给子类实现,如果需要在bean的解析前后做一些处理的话)
parseBeanDefinitions(root, this.delegate);//Bean的解析
postProcessXml(root);//代码为空
this.delegate = parent;
}
发现bean的注册方法应该是parseBeanDefinitions方法,继续往下
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
//获取<beans>标签的子节点也就是所有的<bean>标签
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//如果是默认命名空间的bean
parseDefaultElement(ele, delegate);
}
else {
//如果是自定义命名空间的bean
delegate.parseCustomElement(ele);
}
}
}
}
else {
//自定义命名空间的bean
delegate.parseCustomElement(root);
}
}
这里是逻辑很清楚,获取root下的子节点遍历,判断是否是默认命名空间的元素来分别处理。判断是否是默认命名空间的方式是取Node的namespanceUrl来和默认命名空间的地址进行比较,默认地址为:
public static final String BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";
像<bean id="userService" class="com.test.UserService">这种写法就是默认标签,而如<tx:annotation-driven>这种就是自定义的写法。
总结:本文从BeanFactory的初始化开始,解析XML配置文件,生成Docuemnt对象,解析Document中的标签,按标签的类型来进行区分解析,而两种的解析方式截然不同,接下来就分别解析。
spring源码解析2--容器的基本实现的更多相关文章
- Spring源码解析-ioc容器的设计
Spring源码解析-ioc容器的设计 1 IoC容器系列的设计:BeanFactory和ApplicatioContext 在Spring容器中,主要分为两个主要的容器系列,一个是实现BeanFac ...
- Spring源码解析 – AnnotationConfigApplicationContext容器创建过程
Spring在BeanFactory基础上提供了一些列具体容器的实现,其中AnnotationConfigApplicationContext是一个用来管理注解bean的容器,从AnnotationC ...
- spring源码解析——2容器的基本实现(第2版笔记)
感觉第二版写的略潦草,就是在第一版的基础上加上了新的流行特性,比如idea,springboot,但是,潦草痕迹遍布字里行间. 虽然换成了idea,但是很多截图还是eclipse的,如果不是看了第一版 ...
- Spring源码解析-IOC容器的实现-ApplicationContext
上面我们已经知道了IOC的建立的基本步骤了,我们就可以用编码的方式和IOC容器进行建立过程了.其实Spring已经为我们提供了很多实现,想必上面的简单扩展,如XMLBeanFacroty等.我们一般是 ...
- Spring源码解析-IOC容器的实现
1.IOC容器是什么? IOC(Inversion of Control)控制反转:本来是由应用程序管理的对象之间的依赖关系,现在交给了容器管理,这就叫控制反转,即交给了IOC容器,Spring的IO ...
- Spring源码解析-Web容器启动过程
Web容器启动过程,主要讲解Servlet和Spring容器结合的内容. 流程图如下: Web容器启动的Root Context是有ContextLoaderListener,一般使用spring,都 ...
- Spring源码解析 - AbstractBeanFactory 实现接口与父类分析
我们先来看类图吧: 除了BeanFactory这一支的接口,AbstractBeanFactory主要实现了AliasRegistry和SingletonBeanRegistry接口. 这边主要提供了 ...
- spring 源码解析
1. [文件] spring源码.txt ~ 15B 下载(167) ? 1 springн┤┬вио╬Ш: 2. [文件] spring源码分析之AOP.txt ~ 15KB 下载( ...
- Spring源码解析系列汇总
相信我,你会收藏这篇文章的 本篇文章是这段时间撸出来的Spring源码解析系列文章的汇总,总共包含以下专题.喜欢的同学可以收藏起来以备不时之需 SpringIOC源码解析(上) 本篇文章搭建了IOC源 ...
- Spring源码解析之BeanFactoryPostProcessor(三)
在上一章中笔者介绍了refresh()的<1>处是如何获取beanFactory对象,下面我们要来学习refresh()方法的<2>处是如何调用invokeBeanFactor ...
随机推荐
- 【Tomcat】Tomcat配置JVM参数步骤
这里向大家描述一下如何使用Tomcat配置JVM参数,Tomcat本身不能直接在计算机上运行,需要依赖于硬件基础之上的操作系统和一个java虚拟机.您可以选择自己的需要选择不同的操作系统和对应的JDK ...
- Resource Allocation of Yarn
关键词:yarn 资源分配 mapreduce spark 简要指南 适合不想看太多原理细节直接上手用的人. 基本原则: container分配的内存不等于机器实际用掉的内存.NM给container ...
- [LeetCode] Cheapest Flights Within K Stops K次转机内的最便宜的航班
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a pri ...
- poj1106
极角排序扫一圈. 今天没什么状态写个水题减轻负罪感(大雾) #include <cstdio> #include <cmath> #include <cstring> ...
- Python基础之容器1----字符串和列表
一.编码: 1.编码只是梳理 2.编码涉及的函数: 3.实例: 字符串内存图 二.字符串 1.定义:由一系列字符组成的不可变序列容器,存储的是字符的编码值. 不可变:指字符串一旦定义,其内存地址就已经 ...
- rbac权限控制,基于无线分类
2018年9月18日11:21:28 数据库结构 CREATE TABLE `admin` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `c ...
- 20175320 2018-2019-2 《Java程序设计》第9周学习总结
20175320 2018-2019-2 <Java程序设计>第9周学习总结 教材学习内容总结 本周学习了教材的第十一章的内容,在这章中介绍了JDBC与Mysql数据库,通过本章我了解到了 ...
- SQL 关键字练习
--1.使用基本查询语句.--(1)查询DEPT表显示所有部门select dname from dept:--(2)查询EMP表显示所有雇员名及其全年收入(月收入=工资+补助),处理NULL行,并指 ...
- JS promise
1.Promise是什么? Promise是抽象异步处理对象以及对其进行各种操作的组件. 2.实例化 使用new来调用Promise的构造器来进行实例化 var promise = new Promi ...
- 【C++】基于邻接矩阵的图的深度优先遍历(DFS)和广度优先遍历(BFS)
写在前面:本博客为本人原创,严禁任何形式的转载!本博客只允许放在博客园(.cnblogs.com),如果您在其他网站看到这篇博文,请通过下面这个唯一的合法链接转到原文! 本博客全网唯一合法URL:ht ...