[Erlang 0116] 当我们谈论Erlang Maps时,我们谈论什么 Part 1

Record的痛点
7> rd(person,{name,id}).
person
8> #person{}.
#person{name = undefined,id = undefined}
9> P=person.
person
10> #P{}.
* 1: syntax error before: P
10>
http://stackoverflow.com/questions/4103731/is-it-possible-to-use-record-name-as-a-parameter-in-erlang
10> N=name.
name
11> #person{N="zen"}.
* 1: field 'N' is not an atom or _ in record person
12>
Eshell V6.0 (abort with ^G)
1> rd(foo,{a,b,c}).
foo
2> rd(a,{f,m}).
a
3> rd(f,{id,name}).
f
4> #foo{a=#a{f=#f{id=2002,name="zen"},m=1984},b=1234,c=2465}.
#foo{a = #a{f = #f{id = 2002,name = "zen"},m = 1984},
b = 1234,c = 2465}
5> D=v(4).
#foo{a = #a{f = #f{id = 2002,name = "zen"},m = 1984},
b = 1234,c = 2465}
6> D#foo.a#a.f#f.name.
"zen"
原因何在?
This parse transform can be used to reduce compile-time dependencies in large systems.In the old days, before records, Erlang programmers often wrote access functions for tuple data. This was tedious and error-prone. The record syntax made this easier, but since records were implemented fully in the pre-processor, a nasty compile-time dependency was introduced.
This module automates the generation of access functions for records. While this method cannot fully replace the utility of pattern matching, it does allow a fair bit of functionality on records without the need for compile-time dependencies.

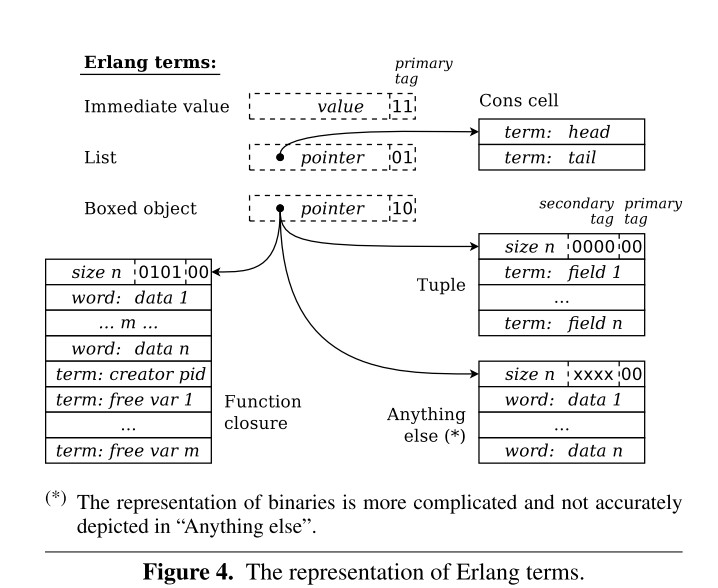
01 = Cons cell (list)
10 = Boxed (tuple, float, bignum, binary, external pid/port, exterrnal/internal ref ...)
11 = Immediate (the rest - secondary tag present)
– 0001 = Binary match state (internal type)
– 001x = Bignum (needs more than 28 bits)
– 0100 = Ref
– 0101 = Fun
– 0110 = Float
– 0111 = Export fun (make_fun/3)
– 1000 - 1010 = Binaries
– 1100 - 1110 = External entities (Pids, Ports and Refs)
#define BIN_MATCHSTATE_SUBTAG (0x1 << _TAG_PRIMARY_SIZE)
#define POS_BIG_SUBTAG (0x2 << _TAG_PRIMARY_SIZE) /* BIG: tags 2&3 */
#define NEG_BIG_SUBTAG (0x3 << _TAG_PRIMARY_SIZE) /* BIG: tags 2&3 */
#define _BIG_SIGN_BIT (0x1 << _TAG_PRIMARY_SIZE)
#define REF_SUBTAG (0x4 << _TAG_PRIMARY_SIZE) /* REF */
#define FUN_SUBTAG (0x5 << _TAG_PRIMARY_SIZE) /* FUN */
#define FLOAT_SUBTAG (0x6 << _TAG_PRIMARY_SIZE) /* FLOAT */
#define EXPORT_SUBTAG (0x7 << _TAG_PRIMARY_SIZE) /* FLOAT */
#define _BINARY_XXX_MASK (0x3 << _TAG_PRIMARY_SIZE)
#define REFC_BINARY_SUBTAG (0x8 << _TAG_PRIMARY_SIZE) /* BINARY */
#define HEAP_BINARY_SUBTAG (0x9 << _TAG_PRIMARY_SIZE) /* BINARY */
#define SUB_BINARY_SUBTAG (0xA << _TAG_PRIMARY_SIZE) /* BINARY */
#define MAP_SUBTAG (0xB << _TAG_PRIMARY_SIZE) /* MAP */
#define EXTERNAL_PID_SUBTAG (0xC << _TAG_PRIMARY_SIZE) /* EXTERNAL_PID */
#define EXTERNAL_PORT_SUBTAG (0xD << _TAG_PRIMARY_SIZE) /* EXTERNAL_PORT */
#define EXTERNAL_REF_SUBTAG (0xE << _TAG_PRIMARY_SIZE) /* EXTERNAL_REF */
Types:
ETERM **array;
int arrsize;
Creates an Erlang tuple from an array of Erlang terms.
array is an array of Erlang terms.
arrsize is the number of elements in array.
- 快速查询 O(1), 编译期间完成了对key的索引,对于小数据量存取相当快 (~50 values),
- 没有过多额外的内存消耗,只有Value和name 2+ N个字 (name + size+ N)
- 函数头完成匹配
http://www.cnblogs.com/me-sa/archive/2012/03/24/you-win-yourself-zen-this-is-the-50-erlang-article-go-on.html
http://www.cnblogs.com/me-sa/archive/2012/04/28/2474892.html
http://www.cnblogs.com/me-sa/archive/2012/06/06/2538941.html
[Erlang 0116] 当我们谈论Erlang Maps时,我们谈论什么 Part 1的更多相关文章
- [Erlang 0117] 当我们谈论Erlang Maps时,我们谈论什么 Part 2
声明:本文讨论的Erlang Maps是基于17.0-rc2,时间2014-3-4.后续Maps可能会出现语法或函数API上的有所调整,特此说明. 前情提要: [Erlang 0116] 当我们谈论E ...
- 当我们谈论Erlang Maps时,我们谈论什么 Part 2
声明:本文讨论的Erlang Maps是基于17.0-rc2,时间2014-3-4.兴许Maps可能会出现语法或函数API上的有所调整,特此说明. 前情提要: [Erlang 0116] 当我们谈论E ...
- 当我们谈论Erlang Maps时,我们谈论什么 Part 1
Erlang 添加 Maps数据类型并非非常突然,由于这个提议已经进行了2~3年之久,仅仅只是Joe Armstrong老爷子近期一篇文章Big changes to Erlang掀起不小了 ...
- [Erlang 0121] 当我们谈论Erlang Maps时,我们谈论什么 Part 3
Erlang/OTP 17.0 has been released http://www.erlang.org/download/otp_src_17.0.readme Erlang/OTP ...
- Erlang基础 -- 介绍 -- 历史及Erlang并发
前言 最近在总结一些Erlang编程语言的基础知识,拟系统的介绍Erlang编程语言,从基础到进阶,然后再做Erlang编程语言有意思的库的分析. 其实,还是希望越来越多的人关注Erlang,使用Er ...
- 话题讨论&征文--谈论大数据时我们在谈什么 获奖名单发布
从社会发展趋势的角度,非常明显大数据会是眼下肉眼可及的视野范围里能看到的最大趋势之中的一个.从传统IT 业到互联网.互联网到移动互联网,从以智能手机和Pad 为主要终端载体的移动互联网到可穿戴设备的移 ...
- [Erlang 0109] From Elixir to Erlang Code
Elixir代码最终编译成为erlang代码,这个过程是怎样的?本文通过一个小测试做下探索. 编译一旦完成,你就看到了真相 Elixir代码组织方式一方面和Erlang一样才用非常 ...
- [Erlang 0128] Term sharing in Erlang/OTP 下篇
继续昨天的话题,昨天提到io:format对数据共享的间接影响,如果是下面两种情况恐怕更容易成为"坑", 呃,恰好我都遇到过; 如果是测试代码是下面这样,得到的结果会是怎样?猜! ...
- [Erlang 0127] Term sharing in Erlang/OTP 上篇
之前,在 [Erlang 0126] 我们读过的Erlang论文 提到过下面这篇论文: On Preserving Term Sharing in the Erlang Virtual Machine ...
随机推荐
- Thread.Sleep(0) vs Sleep(1) vs Yeild
本文将要提到的线程及其相关内容,均是指 Windows 操作系统中的线程,不涉及其它操作系统. 文章索引 核心概念 Thread.Yeild Thread.Sleep(0) Thread. ...
- Azure 部署 Asp.NET Core Web App
在云计算大行其道的时代,当你在部署一个网站时,第一选择肯定是各式各样的云端服务.那么究竟使用什么样的云端服务才能够以最快捷的方式部署一个 ASP.NET Core 的网站呢?Azure 的 Web A ...
- 使用自定义 classloader 的正确姿势
详细的原理就不多说了,网上一大把, 但是, 看了很多很多, 即使看了jdk 源码, 说了罗里吧嗦, 还是不很明白: 到底如何正确自定义ClassLoader, 需要注意什么 ExtClassLoade ...
- 使用python实现短信PDU编码
前几天入手一个3G模块,便倒腾了一下.需要发送中英文混合短信,所以采用PDU模式(不了解google ^_^). 最大问题当然就是拼接PDU编码(python这么强大,说不定有模块),果不其然找到一个 ...
- JavaScript动画-模拟拖拽
模拟拖拽的原理: x1等于div.offsetLeft y1等于div.offsetTop x2等于ev.clientX(ev表示event事件) y2等于ev.clientY 当我们在方块上按下鼠标 ...
- java中的文件读取和文件写出:如何从一个文件中获取内容以及如何向一个文件中写入内容
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.Fi ...
- geotrellis使用(二十六)实现海量空间数据的搜索处理查看
目录 前言 前台实现 后台实现 总结 一.前言 看到这个题目有人肯定会说这有什么可写的,最简单的我只要用文件系统一个个查找.打开就可以实现,再高级一点我可以提取出所有数据的元数据,做个元 ...
- 原生js之四步走搞定Ajax
说到Ajax,不得不先提一下HTTP(HTTP,HyperText Transfer Protocol)协议,中文名:超文本传输协议,是互联网上应用最为广泛的一种网络协议.所有的WWW文件 ...
- js获取屏幕宽高
最近想自己实现一个全屏滚动. 结果一开始就遇到了问题.因为不知道如何获取一个页面屏幕的高度. 网上所有的博客都是复制粘贴. 网页可见区域宽:document.body.clientWidth 网页可见 ...
- SQL Server 并行操作优化,避免并行操作被抑制而影响SQL的执行效率
为什么我也要说SQL Server的并行: 这几天园子里写关于SQL Server并行的文章很多,不管怎么样,都让人对并行操作有了更深刻的认识. 我想说的是:尽管并行操作可能(并不是一定)存在这样或者 ...