LSTM模型与前向反向传播算法
在循环神经网络(RNN)模型与前向反向传播算法中,我们总结了对RNN模型做了总结。由于RNN也有梯度消失的问题,因此很难处理长序列的数据,大牛们对RNN做了改进,得到了RNN的特例LSTM(Long Short-Term Memory),它可以避免常规RNN的梯度消失,因此在工业界得到了广泛的应用。下面我们就对LSTM模型做一个总结。
1. 从RNN到LSTM
在RNN模型里,我们讲到了RNN具有如下的结构,每个序列索引位置t都有一个隐藏状态$h^{(t)}$。
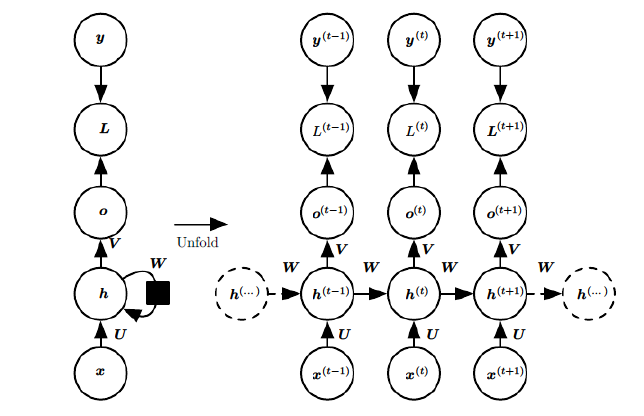
如果我们略去每层都有的$o^{(t)}, L^{(t)}, y^{(t)}$,则RNN的模型可以简化成如下图的形式:
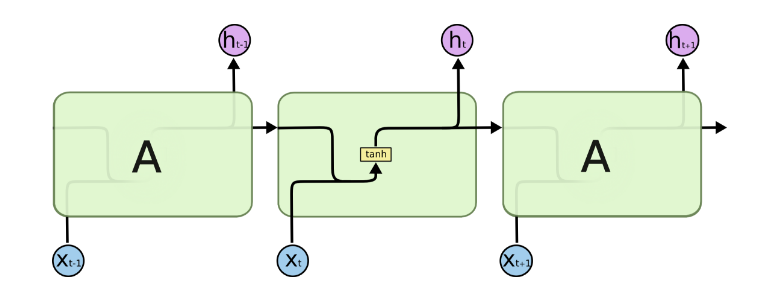
图中可以很清晰看出在隐藏状态$h^{(t)}$由$x^{(t)}$和$h^{(t-1)}$得到。得到$h^{(t)}$后一方面用于当前层的模型损失计算,另一方面用于计算下一层的$h^{(t+1)}$。
由于RNN梯度消失的问题,大牛们对于序列索引位置t的隐藏结构做了改进,可以说通过一些技巧让隐藏结构复杂了起来,来避免梯度消失的问题,这样的特殊RNN就是我们的LSTM。由于LSTM有很多的变种,这里我们以最常见的LSTM为例讲述。LSTM的结构如下图:
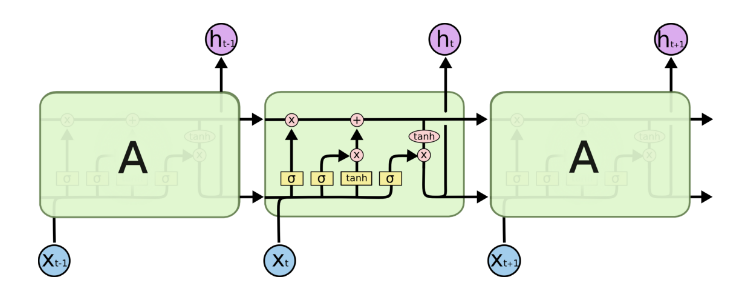
可以看到LSTM的结构要比RNN的复杂的多,真佩服牛人们怎么想出来这样的结构,然后这样居然就可以解决RNN梯度消失的问题?由于LSTM怎么可以解决梯度消失是一个比较难讲的问题,我也不是很熟悉,这里就不多说,重点回到LSTM的模型本身。
2. LSTM模型结构剖析
上面我们给出了LSTM的模型结构,下面我们就一点点的剖析LSTM模型在每个序列索引位置t时刻的内部结构。
从上图中可以看出,在每个序列索引位置t时刻向前传播的除了和RNN一样的隐藏状态$h^{(t)}$,还多了另一个隐藏状态,如图中上面的长横线。这个隐藏状态我们一般称为细胞状态(Cell State),记为$C^{(t)}$。如下图所示:
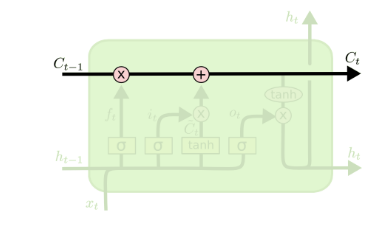
除了细胞状态,LSTM图中还有了很多奇怪的结构,这些结构一般称之为门控结构(Gate)。LSTM在在每个序列索引位置t的门一般包括遗忘门,输入门和输出门三种。下面我们就来研究上图中LSTM的遗忘门,输入门和输出门以及细胞状态。
2.1 LSTM之遗忘门
遗忘门(forget gate)顾名思义,是控制是否遗忘的,在LSTM中即以一定的概率控制是否遗忘上一层的隐藏细胞状态。遗忘门子结构如下图所示:
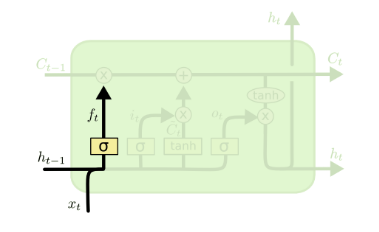
图中输入的有上一序列的隐藏状态$h^{(t-1)}$和本序列数据$x^{(t)}$,通过一个激活函数,一般是sigmoid,得到遗忘门的输出$f^{(t)}$。由于sigmoid的输出$f^{(t)}$在[0,1]之间,因此这里的输出f^{(t)}代表了遗忘上一层隐藏细胞状态的概率。用数学表达式即为:$$f^{(t)} = \sigma(W_fh^{(t-1)} + U_fx^{(t)} + b_f)$$
其中$W_f, U_f, b_f$为线性关系的系数和偏倚,和RNN中的类似。$\sigma$为sigmoid激活函数。
2.2 LSTM之输入门
输入门(input gate)负责处理当前序列位置的输入,它的子结构如下图:

从图中可以看到输入门由两部分组成,第一部分使用了sigmoid激活函数,输出为$i^{(t)}$,第二部分使用了tanh激活函数,输出为$a^{(t)}$, 两者的结果后面会相乘再去更新细胞状态。用数学表达式即为:$$i^{(t)} = \sigma(W_ih^{(t-1)} + U_ix^{(t)} + b_i)$$$$a^{(t)} =tanh(W_ah^{(t-1)} + U_ax^{(t)} + b_a)$$
其中$W_i, U_i, b_i, W_a, U_a, b_a,$为线性关系的系数和偏倚,和RNN中的类似。$\sigma$为sigmoid激活函数。
2.3 LSTM之细胞状态更新
在研究LSTM输出门之前,我们要先看看LSTM之细胞状态。前面的遗忘门和输入门的结果都会作用于细胞状态$C^{(t)}$。我们来看看从细胞状态$C^{(t-1)}$如何得到$C^{(t)}$。如下图所示:
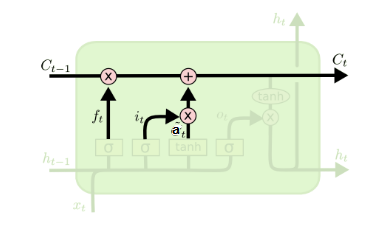
细胞状态$C^{(t)}$由两部分组成,第一部分是$C^{(t-1)}$和遗忘门输出$f^{(t)}$的乘积,第二部分是输入门的$i^{(t)}$和$a^{(t)}$的乘积,即:$$C^{(t)} = C^{(t-1)} \odot f^{(t)} + i^{(t)} \odot a^{(t)}$$
其中,$\odot$为Hadamard积,在DNN中也用到过。
2.4 LSTM之输出门
有了新的隐藏细胞状态$C^{(t)}$,我们就可以来看输出门了,子结构如下:
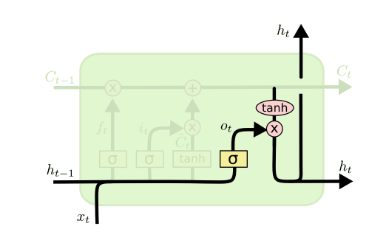
从图中可以看出,隐藏状态$h^{(t)}$的更新由两部分组成,第一部分是$o^{(t)}$, 它由上一序列的隐藏状态$h^{(t-1)}$和本序列数据$x^{(t)}$,以及激活函数sigmoid得到,第二部分由隐藏状态$C^{(t)}$和tanh激活函数组成, 即:$$o^{(t)} = \sigma(W_oh^{(t-1)} + U_ox^{(t)} + b_o)$$$$h^{(t)} = o^{(t)} \odot tanh(C^{(t)})$$
通过本节的剖析,相信大家对于LSTM的模型结构已经有了解了。当然,有些LSTM的结构和上面的LSTM图稍有不同,但是原理是完全一样的。
3. LSTM前向传播算法
现在我们来总结下LSTM前向传播算法。LSTM模型有两个隐藏状态$h^{(t)}, C^{(t)}$,模型参数几乎是RNN的4倍,因为现在多了$W_f, U_f, b_f, W_a, U_a, b_a, W_i, U_i, b_i, W_o, U_o, b_o$这些参数。
前向传播过程在每个序列索引位置的过程为:
1)更新遗忘门输出:$$f^{(t)} = \sigma(W_fh^{(t-1)} + U_fx^{(t)} + b_f)$$
2)更新输入门两部分输出:$$i^{(t)} = \sigma(W_ih^{(t-1)} + U_ix^{(t)} + b_i)$$$$a^{(t)} = \sigma(W_ah^{(t-1)} + U_ax^{(t)} + b_a)$$
3)更新细胞状态:$$C^{(t)} = C^{(t-1)} \odot f^{(t)} + i^{(t)} \odot a^{(t)}$$
4)更新输出门输出:$$o^{(t)} = \sigma(W_oh^{(t-1)} + U_ox^{(t)} + b_o)$$$$h^{(t)} = o^{(t)} \odot tanh(C^{(t)})$$
5)更新当前序列索引预测输出:$$\hat{y}^{(t)} = \sigma(Vh^{(t)} + c)$$
4. LSTM反向传播算法推导关键点
有了LSTM前向传播算法,推导反向传播算法就很容易了, 思路和RNN的反向传播算法思路一致,也是通过梯度下降法迭代更新我们所有的参数,关键点在于计算所有参数基于损失函数的偏导数。
在RNN中,为了反向传播误差,我们通过隐藏状态$h^{(t)}$的梯度$\delta^{(t)}$一步步向前传播。在LSTM这里也类似。只不过我们这里有两个隐藏状态$h^{(t)}$和$C^{(t)}$。因此这里我们要定义两个$\delta$来一步步反向传播,即:$$\delta_h^{(t)} = \frac{\partial L}{\partial h^{(t)}}$$$$\delta_C^{(t)} = \frac{\partial L}{\partial C^{(t)}}$$
而在最后的序列索引位置$\tau$的$\delta_h^{(\tau)}$和 $\delta_C^{(\tau)} $为:$$\delta_h^{(\tau)} =\frac{\partial L}{\partial o^{(\tau)}} \frac{\partial o^{(\tau)}}{\partial h^{(\tau)}} = V^T(\hat{y}^{(\tau)} - y^{(\tau)})$$$$\delta_C^{(\tau)} =\frac{\partial L}{\partial h^{(\tau)}} \frac{\partial h^{(\tau)}}{\partial C^{(\tau)}} = \delta_h^{(\tau)} \odot o^{(\tau)} \odot (1 - tanh^2(C^{(\tau)}))$$
接着我们由$\delta_h^{(t+1)}$和$\delta_C^{(t+1)}$反向推导$\delta_h^{(t)}$和$\delta_C^{(t)}$
$\delta_h^{(t)}$的反向推导和RNN中的类似,因为它的梯度误差由前一层$\delta_h^{(t+1)}$的梯度误差和本层的输出梯度误差两部分组成,即:$$\delta_h^{(t)} =\frac{\partial L}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial h^{(t)}} + \frac{\partial L}{\partial h^{(t+1)}}\frac{\partial h^{(t+1)}}{\partial h^{(t)}} = V^T(\hat{y}^{(t)} - y^{(t)}) + W^T\delta^{(t+1)}diag(1-(h^{(t+1)})^2)$$
而$\delta_C^{(t)}$的反向梯度误差由前一层$\delta_C^{(t+1)}$的梯度误差和本层的从$h^{(t)}$传回来的梯度误差两部分组成,即:$$\delta_C^{(t)} =\frac{\partial L}{\partial C^{(t+1)}} \frac{\partial C^{(t+1)}}{\partial C^{(t)}} + \frac{\partial L}{\partial h^{(t)}}\frac{\partial h^{(t)}}{\partial C^{(t)}} = \delta_C^{(t+1)} + \delta_h^{(t)} \odot o^{(t)} \odot (1 - tanh^2(C^{(t)}))$$
有了$\delta_h^{(t)}$和$\delta_C^{(t)}$, 计算这一大堆参数的梯度就很容易了,这里只给出$W_f$的梯度计算过程,其他的$U_f, b_f, W_a, U_a, b_a, W_i, U_i, b_i, W_o, U_o, b_o,V, c$的梯度大家只要照搬就可以了。$$\frac{\partial L}{\partial W_f} = \sum\limits_{t=1}^{\tau}\frac{\partial L}{\partial C^{(t)}} \frac{\partial C^{(t)}}{\partial f^{(t)}} \frac{\partial f^{(t)}}{\partial W_f} = \delta_C^{(t)} \odot C^{(t-1)} \odot f^{(t)}(1-f^{(t)}) (h^{(t-1)})^T$$
5. LSTM小结
LSTM虽然结构复杂,但是只要理顺了里面的各个部分和之间的关系,进而理解前向反向传播算法是不难的。当然实际应用中LSTM的难点不在前向反向传播算法,这些有算法库帮你搞定,模型结构和一大堆参数的调参才是让人头痛的问题。不过,理解LSTM模型结构仍然是高效使用的前提。
参考资料:
1) Neural Networks and Deep Learning by By Michael Nielsen
2) Deep Learning, book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
LSTM模型与前向反向传播算法的更多相关文章
- 循环神经网络(RNN)模型与前向反向传播算法
在前面我们讲到了DNN,以及DNN的特例CNN的模型和前向反向传播算法,这些算法都是前向反馈的,模型的输出和模型本身没有关联关系.今天我们就讨论另一类输出和模型间有反馈的神经网络:循环神经网络(Rec ...
- 前向传播算法(Forward propagation)与反向传播算法(Back propagation)
虽然学深度学习有一段时间了,但是对于一些算法的具体实现还是模糊不清,用了很久也不是很了解.因此特意先对深度学习中的相关基础概念做一下总结.先看看前向传播算法(Forward propagation)与 ...
- 反向传播算法(前向传播、反向传播、链式求导、引入delta)
参考链接: 一文搞懂反向传播算法
- [2] TensorFlow 向前传播算法(forward-propagation)与反向传播算法(back-propagation)
TensorFlow Playground http://playground.tensorflow.org 帮助更好的理解,游乐场Playground可以实现可视化训练过程的工具 TensorFlo ...
- 神经网络训练中的Tricks之高效BP(反向传播算法)
神经网络训练中的Tricks之高效BP(反向传播算法) 神经网络训练中的Tricks之高效BP(反向传播算法) zouxy09@qq.com http://blog.csdn.net/zouxy09 ...
- 稀疏自动编码之反向传播算法(BP)
假设给定m个训练样本的训练集,用梯度下降法训练一个神经网络,对于单个训练样本(x,y),定义该样本的损失函数: 那么整个训练集的损失函数定义如下: 第一项是所有样本的方差的均值.第二项是一个归一化项( ...
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
- 卷积神经网络(CNN)反向传播算法
在卷积神经网络(CNN)前向传播算法中,我们对CNN的前向传播算法做了总结,基于CNN前向传播算法的基础,我们下面就对CNN的反向传播算法做一个总结.在阅读本文前,建议先研究DNN的反向传播算法:深度 ...
- 机器学习 —— 基础整理(七)前馈神经网络的BP反向传播算法步骤整理
这里把按 [1] 推导的BP算法(Backpropagation)步骤整理一下.突然想整理这个的原因是知乎上看到了一个帅呆了的求矩阵微分的方法(也就是 [2]),不得不感叹作者的功力.[1] 中直接使 ...
随机推荐
- XML 特殊字符处理和 CDATA
在处理XML数据时,特殊字符要特殊处理,不能和节点字符混淆. 所有 XML 文档中的文本均会被解析器解析. 只有 CDATA 区段(CDATA section)中的文本会被解析器忽略. PCDATA ...
- PHP格式化字符串函数 sprintf()
定义和用法 sprintf() 函数把格式化的字符串写入一个变量中. 语法 sprintf(format,arg1,arg2,arg++) 参数 描述 format 必需.转换格式. arg1 必需. ...
- PHP中PDO错误/异常(PDOException)处理
PDO 提供了三种不同的错误处理模式,以满足不同风格的应用开发: PDO::ERRMODE_SILENT 此为默认模式. PDO 将只简单地设置错误码,可使用 PDO::errorCode() 和 P ...
- LVS 负载均衡解决方案 (windows IIS)
LVS 负载均衡解决方案 因为我们的产品运行的主流平台是WINDOWS+IIS+SQLSERVER(2000以上版本),而LVS+KEEPALIVED是LINUX下的四层负载均衡软件.其有如下特点: ...
- Angular - - $templateCache 和 $templateRequest
$templateCache 第一次使用模板,它被加载到模板缓存中,以便快速检索.你可以直接将模板标签加载到缓存中,或者通过$templateCache服务. 通过script标签: <scri ...
- js原生设计模式——7原型模式之new+call(this)组合应用再探讨实例
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8&qu ...
- DELPHI删除记录文件
http://blog.itpub.net/729024/viewspace-564890/ DBGrid1.SelectedRows.Delete;
- C# winform项目中ListView控件使用CheckBoxes属性实现单选功能
C# winform项目中ListView控件使用CheckBoxes属性实现单选功能 在做项目时需要使用ListView控件的CheckBoxes属性显示,还要在点击行时自动选中CheckBoxes ...
- spring mvc 必须传某个参数的写法
在controller中写 @RequestMapping(中的params="json") @RequestMapping(value = "/{username}&q ...
- ORACLE的Dead Connection Detection浅析
在复杂的应用环境下,我们经常会遇到一些非常复杂并且有意思的问题,例如,我们会遇到网络异常(网络掉包.无线网络断线).客户端程序异常(例如应用程序崩溃Crash).操作系统蓝屏.客户端电脑掉电.死机重启 ...