java利用url实现网页内容的抓取
闲来无事,刚学会把git部署到远程服务器,没事做,所以简单做了一个抓取网页信息的小工具,里面的一些数值如果设成参数的话可能扩展性能会更好!希望这是一个好的开始把,也让我对字符串的读取掌握的更加熟练了,值得注意的是JAVA1.8 里面在使用String拼接字符串的时候,会自动把你要拼接的字符串用StringBulider来处理,大大优化了String 的性能,闲话不多说,show my XXX code~
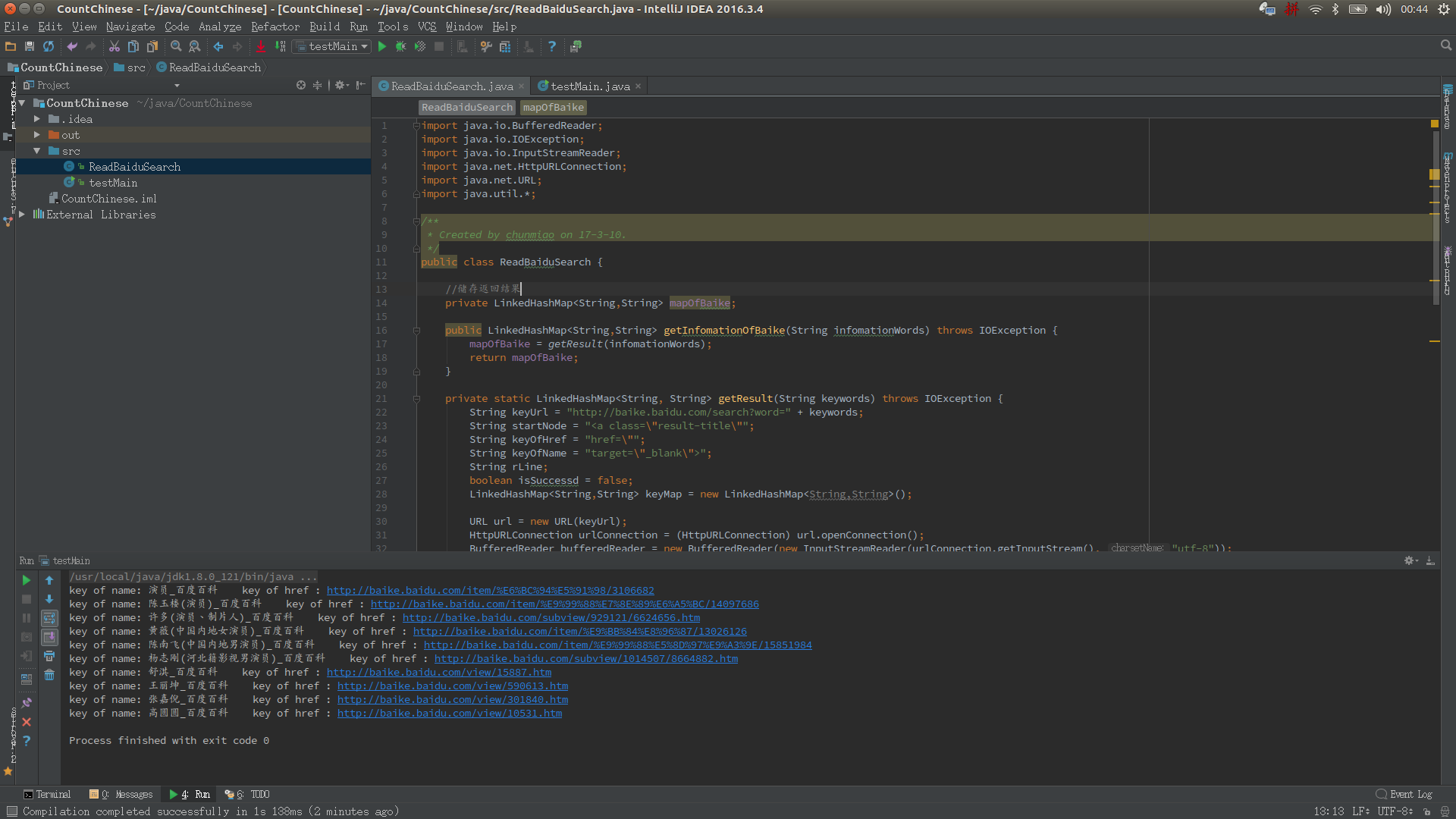
运行效果:
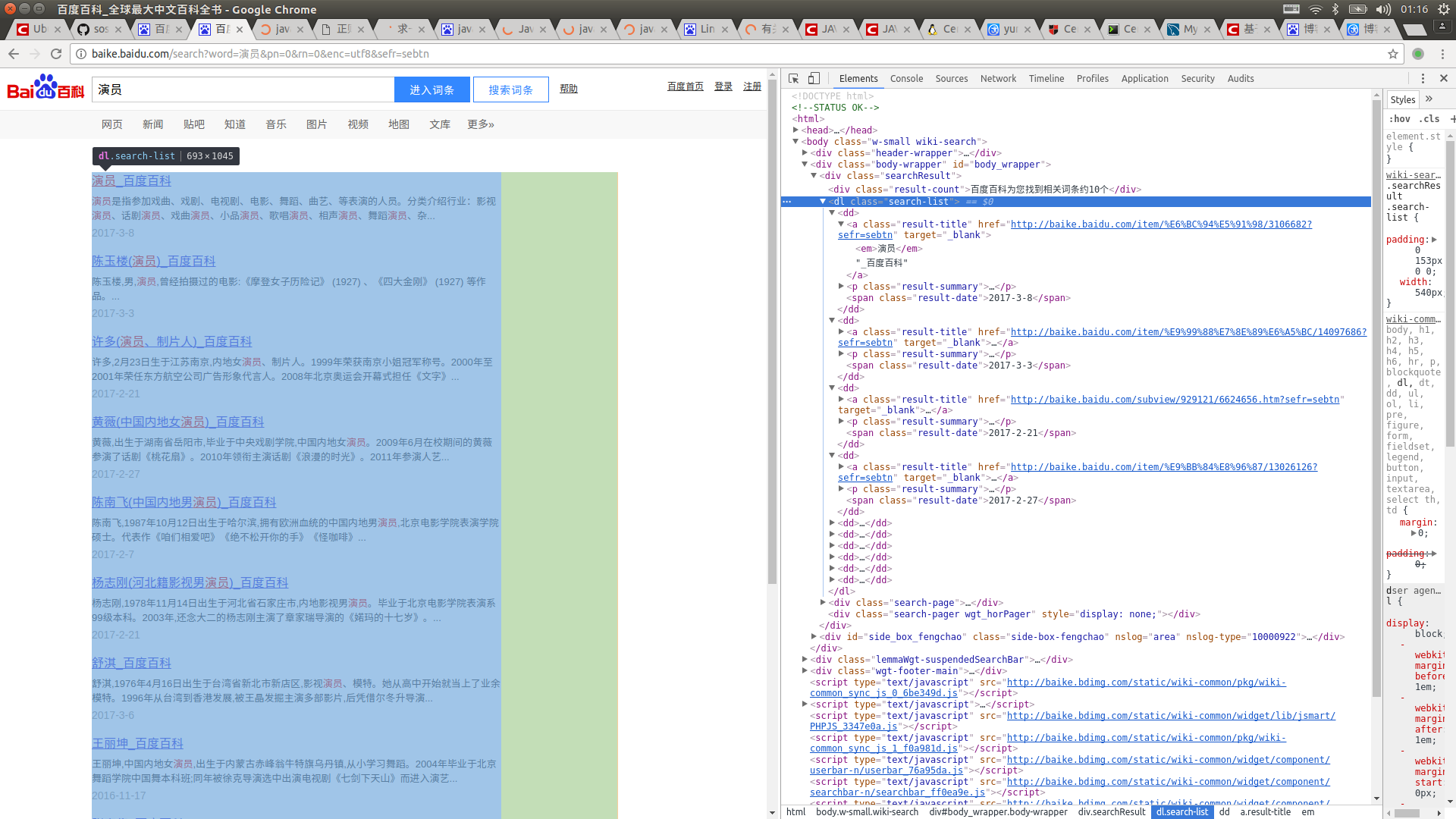
首先打开百度百科,搜索词条,比如“演员”,再按F12查看源码
然后抓取你想要的标签,注入LinkedHashMap里面就ok了,很简单是吧!看看代码罗
- import java.io.BufferedReader;
- import java.io.IOException;
- import java.io.InputStreamReader;
- import java.net.HttpURLConnection;
- import java.net.URL;
- import java.util.*;
- /**
- * Created by chunmiao on 17-3-10.
- */
- public class ReadBaiduSearch {
- //储存返回结果
- private LinkedHashMap<String,String> mapOfBaike;
- //获取搜索信息
- public LinkedHashMap<String,String> getInfomationOfBaike(String infomationWords) throws IOException {
- mapOfBaike = getResult(infomationWords);
- return mapOfBaike;
- }
- //通过网络链接获取信息
- private static LinkedHashMap<String, String> getResult(String keywords) throws IOException {
- //搜索的url
- String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
- //搜索词条的节点
- String startNode = "<dl class=\"search-list\">";
- //词条的链接关键字
- String keyOfHref = "href=\"";
- //词条的标题关键字
- String keyOfTitle = "target=\"_blank\">";
- String endNode = "</dl>";
- boolean isNode = false;
- String title;
- String href;
- String rLine;
- LinkedHashMap<String,String> keyMap = new LinkedHashMap<String,String>();
- //开始网络请求
- URL url = new URL(keyUrl);
- HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
- InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
- BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
- //读取网页内容
- while ((rLine = bufferedReader.readLine()) != null){
- //判断目标节点是否出现
- if(rLine.contains(startNode)){
- isNode = true;
- }
- //若目标节点出现,则开始抓取数据
- if (isNode){
- //若目标结束节点出现,则结束读取,节省读取时间
- if (rLine.contains(endNode)) {
- //关闭读取流
- bufferedReader.close();
- inputStreamReader.close();
- break;
- }
- //若值为空则不读取
- if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
- keyMap.put(title,href);
- }
- }
- }
- return keyMap;
- }
- //获取词条对应的url
- private static String getHref(String rLine,String keyOfHref){
- String baikeUrl = "http://baike.baidu.com";
- String result = "";
- if(rLine.contains(keyOfHref)){
- //获取url
- for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
- result += rLine.charAt(j);
- }
- //获取的url中可能不含baikeUrl,如果没有则在头部添加一个
- if(!result.contains(baikeUrl)){
- result = baikeUrl + result;
- }
- }
- return result;
- }
- //获取词条对应的名称
- private static String getName(String rLine,String keyOfTitle){
- String result = "";
- //获取标题内容
- if(rLine.contains(keyOfTitle)){
- result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
- //将标题中的内容含有的标签去掉
- result = result.replaceAll("<em>|</em>|</a>|<a>","");
- }
- return result;
- }
- }
- 现在都好晚了,去睡觉了...
java利用url实现网页内容的抓取的更多相关文章
- 【JAVA系列】Google爬虫如何抓取JavaScript的?
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[JAVA系列]Google爬虫如何抓取Java ...
- java平台利用jsoup开发包,抓取优酷视频播放地址与图片地址等信息。
/******************************************************************************************** * aut ...
- 使用java开源工具httpClient及jsoup抓取解析网页数据
今天做项目的时候遇到这样一个需求,需要在网页上展示今日黄历信息,数据格式如下 公历时间:2016年04月11日 星期一 农历时间:猴年三月初五 天干地支:丙申年 壬辰月 癸亥日 宜:求子 祈福 开光 ...
- HtmlUnitDriver 网页内容动态抓取
#抓取内容 WebDriver driver = new HtmlUnitDriver(false); driver.get(url); String html = driver.getPageSou ...
- java网络爬虫实现信息的抓取
转载请注明出处:http://blog.csdn.NET/lmj623565791/article/details/23272657 今天公司有个需求,需要做一些指定网站查询后的数据的抓取,于是花了点 ...
- java利用URL发送get和post请求
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import ...
- python3下scrapy爬虫(第四卷:初步抓取网页内容之抓取网页里的指定数据延展方法)
上卷中我运用创建HtmlXPathSelector 对象进行抓取数据: 现在咱们再试一下其他的方法,先试一下我得最爱XPATH 看下结果: 直接打印出结果了 我现在就正常拼下路径 只求打印结果: 现在 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- 网络爬虫:利用selenium,pyquery库抓取并处理京东上的图片并存储到使用mongdb数据库进行存储
一,环境的搭建已经简单的工具介绍 1.selenium,一个用于Web应用程序测试的工具.其特点是直接运行在浏览器中,就像真正的用户在操作一样.新版本selenium2集成了 Selenium 1.0 ...
随机推荐
- spring mvc 注解入门示例
web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi=" ...
- 《你不知道的js》 ------1.作用域是什么
相关定义 引擎:从头到尾负责整个JavaScript程序的编译及执行过程. 编译器:负责语法分析及代码生成等. 作用域:负责收集并维护由所有声明的标识符(变量)组成的一系列查询,并实施一套非常严格的规 ...
- HTML5中将video设置为背景的方法
主要用到了video标签,css样式,原理是先将video标签利用position:fixed;使video标签脱离文档流,在将他的z-index设置为最低的,比如-9999.再插入的内容自然就覆盖在 ...
- Fiddler 模拟请求的操作方法
此文记录使用Fidder Web Debugger工具,模拟请求的操作步骤! 首先简述一下fiddler的使用: 1.下载安装Fidder抓包工具. 2.打开fiddler发现有左边的栏有请求的url ...
- CodeForces 451B
Sort the Array Time Limit:1000MS Memory Limit:262144KB 64bit IO Format:%I64d & %I64u Sub ...
- LCD驱动移植在在mini2440(linux2.6.29)和FS4412(linux3.14.78)上实现对比(deep dive)
1.Linux帧缓冲子系统 帧缓冲(FrameBuffer)是Linux为显示设备提供的一个接口,用户可以将帧缓冲看成是显示内存的一种映像,将其映射到进程地址空间之后,就可以直接进行读写操作,而写操作 ...
- ArcGIS Pro 简明教程(3)数据编辑
ArcGIS Pro 简明教程(3)数据编辑 by 李远祥 数据编辑是GIS中最常用的功能之一,ArcGIS Pro在GIS数据编辑上使用习惯有一定的改变,因此,本章可以重点看看一些编辑工具的使用和使 ...
- JAVA构造函数的继承
1.子类中无参构造函数,可直接继承父类中无参构造函数,前提是所有变量均为public 如下:父类Student中有空构造函数Student(),子类Pupil中有空构造函数Pupil(),后者会继承前 ...
- Myeclipese改变背景色
https://www.baidu.com/s?wd=Myeclipese%E6%94%B9%E5%8F%98%E8%83%8C%E6%99%AF%E8%89%B2&ie=utf-8& ...
- php in_array语法
bool in_array ( mixed $needle , array $haystack [, bool $strict ] ) 返回值为直或假 var_dump(in_array( ...