大数据系列之Flume+HDFS
本文将介绍Flume(Spooling Directory Source) + HDFS,关于Flume 中几种Source详见文章 http://www.cnblogs.com/cnmenglang/p/6544081.html
1.资料准备 : apache-flume-1.7.0-bin.tar.gz
2.配置步骤:
a.上传至用户(LZ用户mfz)目录resources下
b.解压
tar -xzvf apache-flume-1.7.-bin.tar.gz
c.修改conf下 文件名

mv flume-conf.properties.template flume-conf.properties
mv flume-env.sh.template flume-env.sh
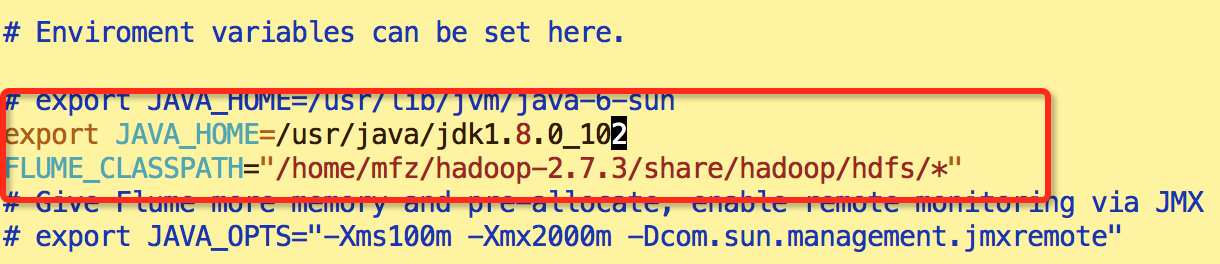
d.修改flume-env.sh 环境变量,添加如下:
export JAVA_HOME=/usr/java/jdk1.8.0_102
FLUME_CLASSPATH="/home/mfz/hadoop-2.7.3/share/hadoop/hdfs/*"
e.新增文件 hdfs.properties
LogAgent.sources = apache
LogAgent.channels = fileChannel
LogAgent.sinks = HDFS #sources config
#spooldir 对监控指定文件夹中新文件的变化,一旦有新文件出现就解析,解析写入channel后完成的文件名将追加后缀为*.COMPLATE
LogAgent.sources.apache.type = spooldir
LogAgent.sources.apache.spoolDir = /tmp/logs
LogAgent.sources.apache.channels = fileChannel
LogAgent.sources.apache.fileHeader = false #sinks config
LogAgent.sinks.HDFS.channel = fileChannel
LogAgent.sinks.HDFS.type = hdfs
LogAgent.sinks.HDFS.hdfs.path = hdfs://master:9000/data/logs/%Y-%m-%d/%H
LogAgent.sinks.HDFS.hdfs.fileType = DataStream
LogAgent.sinks.HDFS.hdfs.writeFormat=TEXT
LogAgent.sinks.HDFS.hdfs.filePrefix = flumeHdfs
LogAgent.sinks.HDFS.hdfs.batchSize = 1000
LogAgent.sinks.HDFS.hdfs.rollSize = 10240
LogAgent.sinks.HDFS.hdfs.rollCount = 0
LogAgent.sinks.HDFS.hdfs.rollInterval = 1
LogAgent.sinks.HDFS.hdfs.useLocalTimeStamp = true #channels config
LogAgent.channels.fileChannel.type = memory
LogAgent.channels.fileChannel.capacity =10000
LogAgent.channels.fileChannel.transactionCapacity = 100
3.启动:
1.在 apache-flume 目录下执行
bin/flume-ng agent --conf-file conf/hdfs.properties -c conf/ --name LogAgent -Dflume.root.logger=DEBUG,console

启动出错,Ctrl+C 退出,新建监控目录/tmp/logs
mkdir -p /tmp/logs
重新启动:
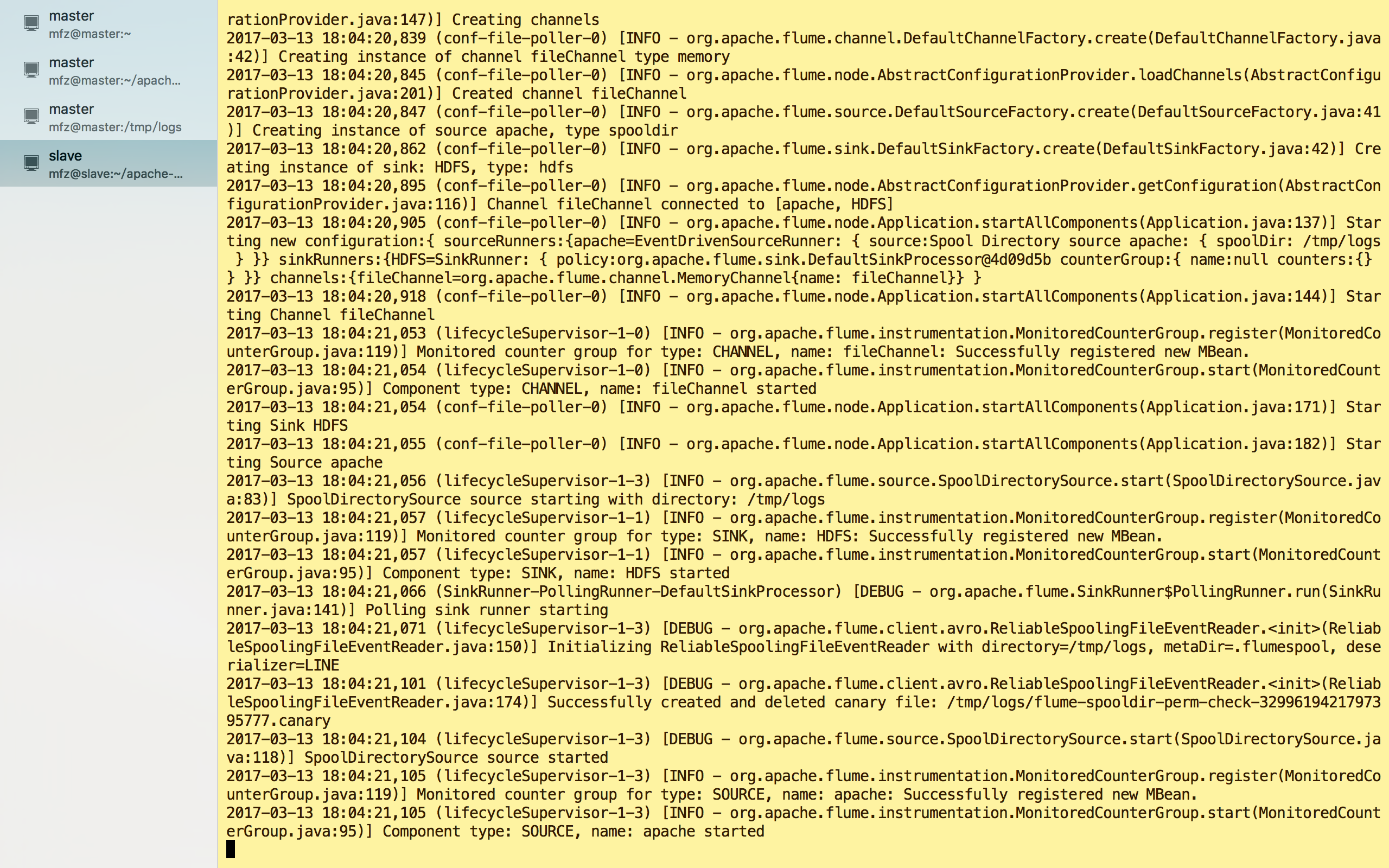
启动成功!
4.验证:
a.另新建一终端操作;
b.在监控目录/tmp/logs下新建test.log目录
vi test.log #内容
test hello world
c.保存文件后查看之前的终端输出为
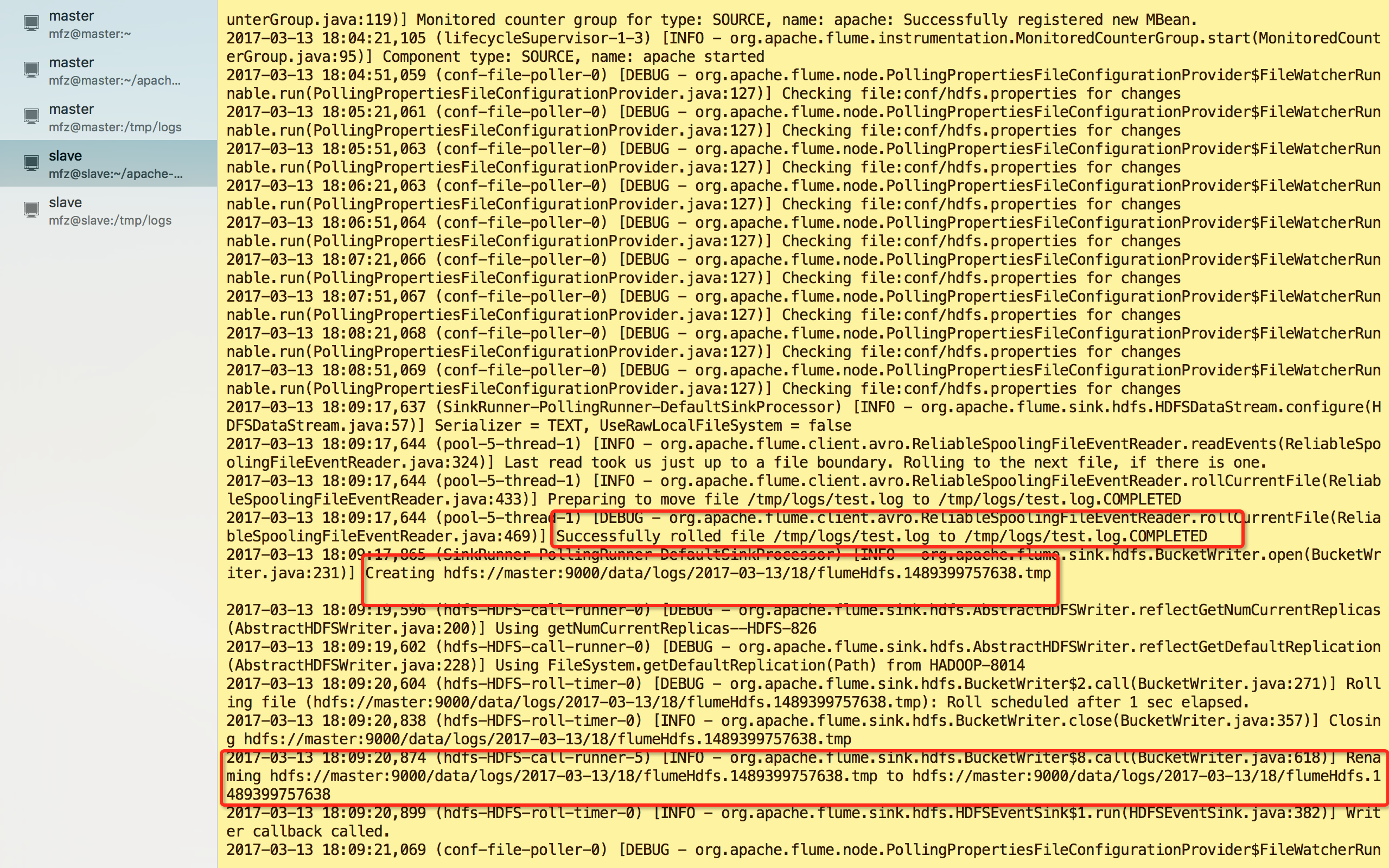
看图可得到信息:
1.test.log 已被解析传输完成且名称修改为test.log.COMPLETED;
2.HDFS目录下生成了文件及路径为:hdfs://master:9000/data/logs/2017-03-13/18/flumeHdfs.1489399757638.tmp
3.文件flumeHdfs.1489399757638.tmp 已被修改为flumeHdfs.1489399757638
那么接下里登录master主机,打开WebUI,如下操作
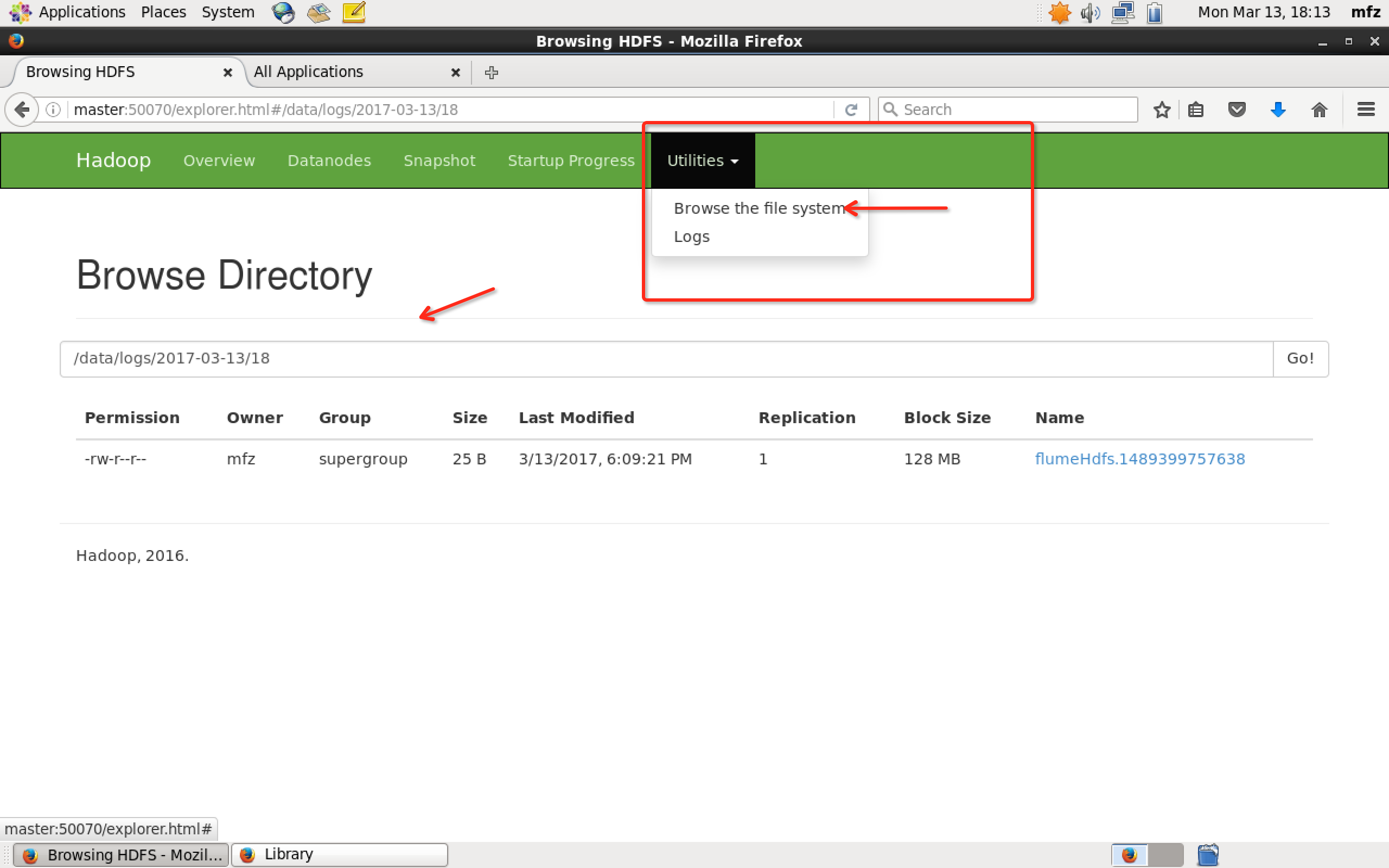
或者打开master终端,在hadoop安装包下执行命令
bin/hadoop fs -ls -R /data/logs/--/

查看文件内容,命令:
bin/hadoop fs -cat /data/logs/2017-03-13/18/flumeHdfs.1489399757638

OK,完成!
大数据系列之Flume+HDFS的更多相关文章
- 大数据系列之Flume+kafka 整合
相关文章: 大数据系列之Kafka安装 大数据系列之Flume--几种不同的Sources 大数据系列之Flume+HDFS 关于Flume 的 一些核心概念: 组件名称 功能介绍 Agent ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据系列之并行计算引擎Spark部署及应用
相关博文: 大数据系列之并行计算引擎Spark介绍 之前介绍过关于Spark的程序运行模式有三种: 1.Local模式: 2.standalone(独立模式) 3.Yarn/mesos模式 本文将介绍 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
随机推荐
- 有关extdelete恢复测试
客户意外rm掉了数据文件,导致数据库无法打开,由于没有完整的备份和归档,需要使用别的方法,而客户又关闭了数据库,导致无法使用文件描述符恢复,就要使用linux上别的方法了,现记录使用extundele ...
- 利用Flare3D和Stage3D创建3D
Flare3D 是一款功能强大的引擎,它使得 Flash 中的 3D 内容管理变得更为简便. 它的设计宗旨是提供一个完美的开发工作流程,以便你能够获得事半功倍的效果. 本教程侧重讨论在 Flash 中 ...
- HDU1864(背包)
最大报销额 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submi ...
- BZOJ两水题连发~(BZOJ1854&&BZOJ1191)
前言:两题都是省选题不过水的惊人,且都可以用二分图最大匹配做哎--- 1854: [Scoi2010]游戏 Time Limit: 5 Sec Memory Limit: 162 MBSubmit: ...
- 基于MAC OS 操作系统安装、配置mysql
$ sudo mv mysql-5.1.45-osx10.6-x86_64 /usr/local/mysql$ cd /usr/local$ sudo chown -R mysql:mysql mys ...
- Xcode版本太低引发的bug,xcode各种版本下载方式详解
问题描述: mac系统10.9.5 .之前用的xcode 是5.1.接sdk时,一直报错,编译不过去.最后发现原因是xcode版本太低导致的. 于是去网上找xcode历史版本下载.因为系统版本原因,我 ...
- java实现解析二进制文件(字符串、图片)
1.需求说明,实现细节要求: 解析二进制文件 files\case10\binary,其中包含一个字符串和一张图片,数据文件格式为字符串数据长度(2字节)+字符串内容+图片数据长度(4字节)+图片数据 ...
- WAS缓存导致的修改文件不生效问题【转】
WAS缓存导致的修改文件不生效问题: 解决方法: 一. 修改web.xml文件,需要修改以下三个目录下的文件: 1. /opt/IBM/WebSphere/AppServer/profiles/Dmg ...
- 修改本地配置远程连接oracle数据库
当我们需要查看数据库信息时,我们更愿意通过客户端来查看,这样不仅操作方便,而且查看更精准.那么需要远程连接数据库需要在本地修改那些配置呢?以下是我个人的经验,希望大家都指正. 1.在oracle安装目 ...
- CSS之浏览器默认样式设置
今天自己写css样式时,其中用到了<ul>标签,设置了一系列效果后运行,发现位置与设置有出入.chrome上打开检查项,发现<ul>标签的styles底部多了以下一段: ul, ...