[读书笔记] R语言实战 (五) 高级数据管理
1. 数值函数
1) 数学函数


2) 统计函数

3. 数据标准化
scale() 函数对矩阵或者数据框的指定列进行均值为0,标准化为1的标准化
mydata <- data.frame(c1=c(1,2,3),c2=c(4,5,6),c3=c(7,8,9))
#对所有列进行标准化
mydata <- scale(mydata)
#对指定列进行标准化
mydata <- data.frame(c1=c(1,2,3),c2=c(4,5,6),c3=c(7,8,9))
mydata <- transform(mydata,c1 = scale(c1))
4. 概率函数
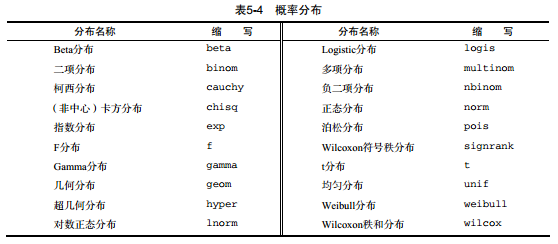
设定随机数种子:每次生成随机数的时候函数都会使用不同的种子,因此也会有不同的结果,可以通过set.seed()显示指定种子,让结果可以重现。
runif() 函数用来生成0到1区间上服从均匀分布的伪随机数
runif(5)
runif(5)
set.seed(1234)
runif(5)
set.seed(1234)
runif(5)
5. 字符处理函数


apply 函数 可以将任意一个函数应用到矩阵数组,数据框的任何维度上:
apply(x, MARGIN, FUN, ... )
mydata <- matrix(rnorm(30),nrow=6)
mydata
#计算每行的均值
apply(mydata,1,mean)
#计算每列的均值
apply(mydata,2,mean)
一个综合的例子
#限定输出小数点后两位
options(digits=2)
Student <-c("Jhon Davis","Angela Williams","Bullwinkle None",
"David Jones","Janice Markhammer","Chervl Cushing",
"Reuven Ytzrhak","Greg Knox","Joel England","Mary Rayburn")
Math <- c(502,600,412,358,495,512,410,625,573,522)
Science <- c(95,99,80,82,75,85,80,95,89,86)
English <- c(25,22,18,15,20,28,15,30,27,18)
roster <- data.frame(Student,Math,Science,English,stringsAsFactors = FALSE)
#将数学,科学,英语分数标准化,便于比较
z <- scale(roster[,2:4])
#计算行均值,每一个人的平均分
score <- apply(z,1,mean)
#将平均分
roster <- cbind(roster,score)
#计算80%,60%,40%,20%分位线
y <- quantile(score,c(.8,.6,.4,.2))
roster$grade[score>=y[1]]<-'A'
roster$grade[score<y[1] & score>=y[2]]<-'B'
roster$grade[score<y[2] & score>=y[3]]<-'C'
roster$grade[score<y[3] & score>=y[4]]<-'D'
roster$grade[score<y[4]]<-'F'
#将姓,名分开
name <- strsplit(roster$Student," ")
#抽取姓和名,'['提取对象一部分的函数
firstname <- sapply(name,"[",2)
lastname <- sapply(name,"[",1)
#将第一列剔除(下标使用-1),列拼接名和姓
roster <-cbind(firstname,lastname,roster[,-1])
roster <- roster[order(lastname,firstname),]
roster
6. 控制流
1) for 循环:for (var in seq) statement
2) while循环: while(cond) statement
3) 条件 if-else ifelse switch
7. 用户自编函数
mystats <- function(x, parametric=TRUE, print=FALSE){
if(parametric){
#计算均值和标准差
center <- mean(x); spread <- sd(x)
}else
{
#中位数和绝对中位差
center <- median(x);spread <- mad(x)
}
if (print & parametric){
cat("Mean=",center,"\n","MAD=",spread,"\n")
}
result <- list(center=center,spread=spread)
return(result)
}
set.seed(1234)
#生成服从正态分布,大小为500的样本
x <- rnorm(500)
y <- mystats(x,print=TRUE)
8. 重构与整合
1) 矩阵转置 t()
2) aggregate() 函数, aggregate(x,by,FUN), x 是待折叠的数据对象, by 是变量名组成的列表,这些变量被去掉形成新的观测,FUN,生成描述性统计量的标量函数,用来计算新观测中的值
by中的变量必须在一个列表中
options(digits=3)
attach(mtcars)
#按照cly 和 gear分类形成新的观测
aggdata <- aggregate(mtcars, by=list(Group.cyl=cyl,Group.gear=gear),FUN=mean,na.rm=TRUE)
detach(mtcars)
3) reshape包
先对数据进行融合melt():每个观测变量单独占一行,行中有唯一确定这个测量需要的标识符变量
在对数据进行重铸cast():读取已经融合的数据,使用你提供的公式和一个可选的用于整合数据的函数将其重塑
#载入reshape包
library(reshape)
#创建数据框
mydata <- data.frame(ID = c(1,1,2,2),Time = c(1,2,1,2),X1 = c(5,3,6,2),X2 = c(6,5,1,4))
#以ID和Time为标识融合数据
md <- melt(mydata,id=(c("ID","Time")))
#以ID为标识对变量求均值,可以看到ID为1的X1均值为4,X2均值为5.5
cast(md,ID~variable,mean)
#对不同ID和Time下的观测变量X进行平均
cast(md,ID~Time,mean)
[读书笔记] R语言实战 (五) 高级数据管理的更多相关文章
- [读书笔记] R语言实战 (一) R语言介绍
典型数据分析的步骤: R语言:为统计计算和绘图而生的语言和环境 数据分析:统计学,机器学习 R的使用 1. 区分大小写的解释型语言 2. R语句赋值:<- 3. R注释: # 4. 创建向量 c ...
- [读书笔记] R语言实战 (四) 基本数据管理
1. 创建新的变量 mydata<-data.frame(x1=c(2,2,6,4),x2=c(3,4,2,8)) #方法一 mydata$sumx<-mydata$x1+mydata$x ...
- [读书笔记] R语言实战 (二) 创建数据集
R中的数据结构:标量,向量,数组,数据框,列表 1. 向量:储存数值型,字符型,或者逻辑型数据的一维数组,用c()创建 ** R中没有标量,标量以单元素向量的形式出现 2. 矩阵:二维数组,和向量一 ...
- [读书笔记] R语言实战 (六) 基本图形方法
1. 条形图 barplot() #载入vcd包 library(vcd) #table函数提取各个维度计数 counts <- table(Arthritis$Improved) count ...
- [读书笔记] R语言实战 (十四) 主成分和因子分析
主成分分析和探索性因子分析是用来探索和简化多变量复杂关系的常用方法,能解决信息过度复杂的多变量数据问题. 主成分分析PCA:一种数据降维技巧,将大量相关变量转化为一组很少的不相关变量,这些无关变量称为 ...
- [读书笔记] R语言实战 (三) 图形初阶
创建图形,保存图形,修改特征:标题,坐标轴,标签,颜色,线条,符号,文本标注. 1. 一个简单的例子 #输出到图形到pdf文件 pdf("mygrapg.pdf") attach( ...
- [读书笔记] R语言实战 (十三) 广义线性模型
广义线性模型扩展了线性模型的框架,它包含了非正态的因变量分析 广义线性模型拟合形式: $$g(\mu_\lambda) = \beta_0 + \sum_{j=1}^m\beta_jX_j$$ $g( ...
- 《R语言实战》读书笔记--为什么要学
本人最近在某咨询公司实习,涉及到了一些数据分析的工作,用的是R语言来处理数据.但是在应用的过程中,发现用R很不熟练,所以再打算学一遍R.曾经花一个月的时间看过一遍<R语言编程艺术>,还用R ...
- R语言实战(第二版)-part 1笔记
说明: 1.本笔记对<R语言实战>一书有选择性的进行记录,仅用于个人的查漏补缺 2.将完全掌握的以及无实战需求的知识点略去 3.代码直接在Rsudio中运行学习 R语言实战(第二版) pa ...
随机推荐
- Git学习总结(11)——Git撤销操作详解
本文主要讨论和撤销有关的 git 操作.目的是让读者在遇到关于撤销问题时能够方便迅速对照执行解决问题,而不用去翻阅参数繁多的 git 使用说明. 一开始你只需了解大致功能即可,不必记住所有命令和具体参 ...
- NEFU 84
其实同POJ 1061 #include <iostream> #include <cstdio> #include <cstring> #include < ...
- SSH学习之中的一个 OpenSSH基本使用
在Linux系统中.OpenSSH是眼下最流行的远程系统登录与文件传输应用,也是传统Telenet.FTP和R系列等网络应用的换代产品. 当中,ssh(Secure Shell)能够替代telnet. ...
- hdu5386 Cover
Problem Description You have an n∗n matrix.Every grid has a color.Now there are two types of operati ...
- oracle rac下调节redo log file 文件大小
rac下调节redo log file 文件大小 (1)查看当前日志信息: select * from v$logfile; (步骤2中得路径能够在这里MEMBER列看到,redo文件名称自己命名.比 ...
- 浅析Context Class Loader
浅析Context Class Loader 2010-05-11 16:58:49 分类: Java 转载自 薛笛的专栏http://blog.csdn.net/kabini/archive/200 ...
- nyoj-647-奋斗小蜗牛在请客(进制转换)
奋斗小蜗牛在请客 时间限制:1000 ms | 内存限制:65535 KB 难度:2 描写叙述 一路艰辛一路收获.成功爬过金字塔的小蜗牛别提多高兴了.这不为了向以前帮助他的哥们们表达谢意,蜗牛宴请 ...
- MySQL官方文档
http://dev.mysql.com/doc/refman/5.7/en/index.html 没有比这更好的MySQL文档了,省的去买书了
- Geeks - Range Minimum Query RMQ范围最小值查询
使用线段树预处理.能够使得查询RMQ时间效率在O(lgn). 线段树是记录某范围内的最小值. 标准的线段树应用. Geeks上仅仅有两道线段树的题目了.并且没有讲到pushUp和pushDown操作. ...
- 从乐视和小米“最火电视”之战 看PR传播策略
今年的双11够热闹.一方面,阿里.京东.国美.苏宁等电商巨头卯足了劲儿.试图在双11期间斗个你死我活,剑拔弩张的气势超过了以往不论什么一场双11:还有一方面.不少硬件厂商.家电企业也来凑双11 ...